

System Design Interview Ch 12 Digital Wallet
確立問題與設計範疇
| 角色 | 對話內容 |
| 面試者 | 我們應該只關注兩個數位錢包之間的餘額轉帳操作嗎?我們是否需要擔心其他功能? |
| 面試官 | 讓我們只關注餘額轉帳操作。 |
| 面試者 | 該系統需要支援多少 TPS(每秒交易次數)? |
| 面試官 | 讓我們假設是 1,000,000 TPS (每秒 100 萬次交易)。 |
| 面試者 | 數位錢包對正確性有嚴格的要求。我們可以假設事務保證 就足夠了嗎? |
| 面試官 | 聽起來不錯。 |
| 面試者 | 我們需要證明正確性嗎? |
| 面試官 | 這是一個很好的問題。正確性(Correctness)通常只有在交易完成後才能驗證。一種驗證方法是將我們的內部記錄與銀行對帳單進行比較。對帳的局限性在於它只顯示差異,無法說明差異是如何產生的。因此,我們希望設計一個具有**可重現性(Repoducibility)**的系統,這意味著我們可以透過從頭開始重放數據,隨時重建歷史餘額。 |
| 面試者 | 我們可以假設可用性要求是 99.99% 嗎? |
| 面試官 | 聽起來不錯。 |
| 面試者 | 我們需要考慮外匯嗎? |
| 面試官 | 不,這超出了本次討論範圍。 |
摘要:
• 高吞吐量 (TPS): 系統需要支援每秒 1,000,000 次交易 (1,000,000 TPS)。
- 為了達到這個目標,後端估算可能需要約 2,000 個資料庫節點來處理每秒 1 百萬次轉帳(因為每次轉帳涉及兩條指令,相當於 2 百萬次操作)。
• 可靠性: 系統的可靠性必須至少達到 99.99%。
• 事務與一致性: 必須支援交易 (transactions),以確保資料的正確性。
• 可重現性 (Reproducibility): 系統需要具備從頭開始重放資料來重建歷史餘額的能力
Step 1 粗略估算
1. 估算的前提與假設
• 背景: 討論 TPS 時,通常假設系統將使用事務型資料庫 (transactional database)。
• 性能基準: 來源指出,現今運行在典型資料中心節點上的關係型資料庫,大約可以支援每秒幾千次事務。
• 單節點假設: 為了進行估算,假設一個資料庫節點可以支援 1,000 TPS(每秒 1,000 次事務)。
• 目標負載: 系統必須支援 1,000,000 TPS(每秒 1 百萬次交易)。
2. 初始計算與修正
這個估算過程的關鍵點在於,交易數(轉帳次數)並不等同於實際的資料庫操作數。
1. 初始(不準確的)計算: 如果系統需要 1,000,000 TPS,而每個資料庫節點能處理 1,000 TPS,那麼初始估算需要 1,000 個資料庫節點(1,000,000 / 1,000 = 1,000)。
2. 關鍵修正(實際操作數): 這個計算被認為是稍微不準確的。這是因為每個轉帳指令 (transfer command) 需要兩個操作:
◦ 從一個帳戶扣除資金 (deducting money)。
◦ 向另一個帳戶存入資金 (depositing money)。
3. 最終所需的節點數量: 為了支援每秒 1 百萬次的轉帳,系統實際上需要處理高達 2 百萬次 TPS(2,000,000 TPS,即 2 百萬次操作)。 因此,根據每個節點 1,000 TPS 的假設,系統需要 2,000 個節點(2,000,000 / 1,000 = 2,000 節點)來支援此負載。
3. 對設計的影響
這個粗略估算直接影響了設計目標,因為所需節點的總數與單節點可處理的事務次數成反比:
• 設計目標: 降低所需的總節點數量是設計目標之一,這意味著必須增加單一節點可以處理的事務數量 (per-node TPS)。單節點的 TPS 越高,所需的硬體成本就越低。
來源提供了 TPS 與所需節點數量的映射表(Table 12.1),進一步說明了這種關係:
| 每節點 TPS (Per-node TPS) | 所需節點數量 (Node Number) |
| 100 | 20,000 |
| 1,000 | 2,000 (此為計算結果) |
| 10,000 | 200 |
總結來說,粗略估算確定了數位錢包系統為了處理 1 百萬次轉帳的負載,需要數千個資料庫節點,這為後續討論分區 (sharding)、分佈式事務 (distributed transactions) 以及如何提高單節點效率奠定了基礎。
Step 2 - Propose High-level Design and Get Buy-in
1. API 設計 (API Design)
在深入討論架構之前,首先要確立外部客戶端將如何與系統互動。
• API 協定: 採用 RESTful API 協定。
• 唯一支援的 API: 在本次面試中,只需支援一個 API,即跨錢包餘額轉帳操作。
• API 規範:
◦ 方法/路徑: POST /v1/wallet/balance_transfer。
◦ 功能: 執行從一個錢包向另一個錢包轉帳。
• 請求參數 (Request parameters): 請求需要包含以下欄位:
◦ from_account:借記帳戶(扣款帳戶)。
◦ to_account:貸記帳戶(收款帳戶)。
◦ amount:金額(資料類型為字串 string)。
◦ currency:貨幣類型(使用 ISO 4217 標準)。
◦ transaction_id:用於去重複 (deduplication) 的 UUID。
•Response Body:
◦ status
◦ transaction_id
2. 三種高階設計方案的討論 (Three High-level Designs)
此階段的重點是逐步提出並完善三個高階設計方案,以解決系統對一致性和可重現性的嚴格要求。
2.1. 方案一:簡單的記憶體內解決方案 (Simple In-memory solution)
這是第一個被提出的高階方案,主要利用記憶體內分區儲存(例如 Redis 叢集)來維護帳戶餘額。
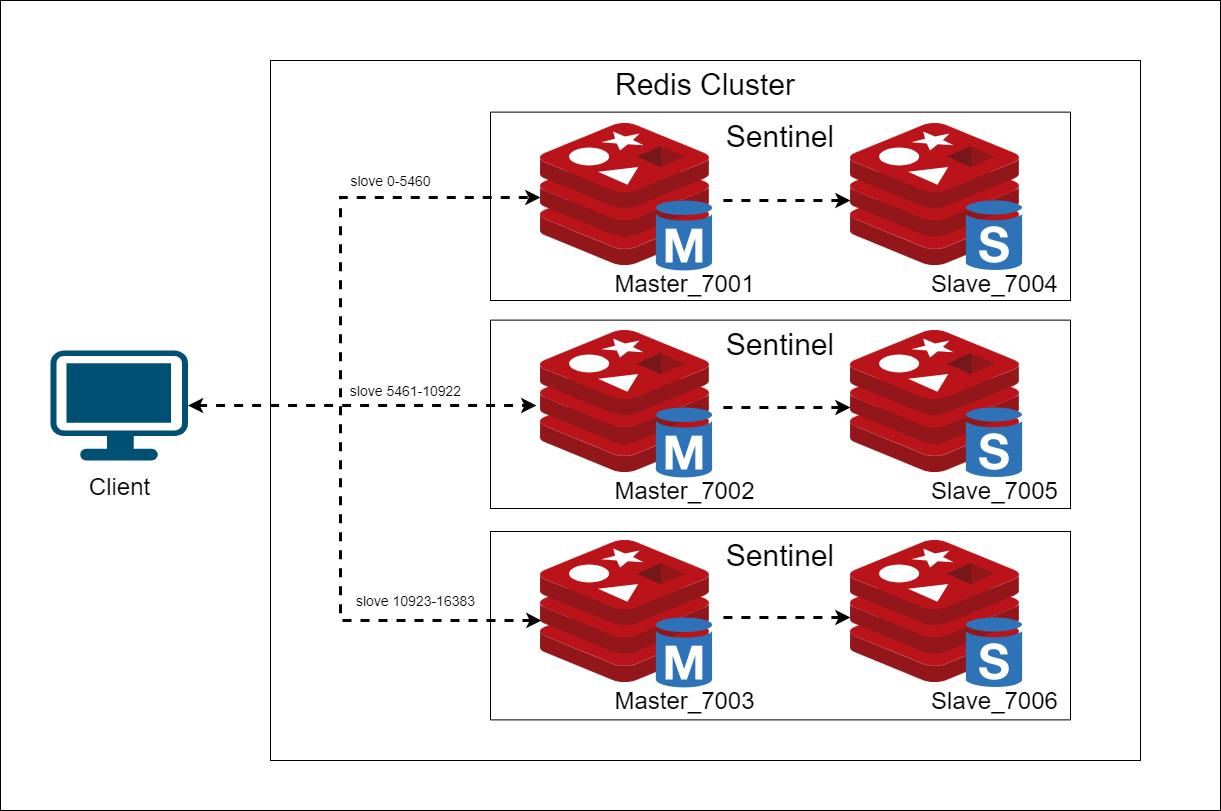
• 架構: 錢包服務 (Wallet Service) 是無狀態的,它根據分片資訊(可能由 ZooKeeper 管理)向分佈在多個 Redis 節點上的帳戶發出更新指令。

以下是面試官與面構、高效能優勢,以及最關鍵的缺陷——缺乏事務原子性 (Atomicity) 進行了交流。
1. 面試者對方案的描述(架構概述)
面試者首先說明了該方案的結構和工作原理:
• 資料儲存與分散: 帳戶餘額分佈在多個 Redis 節點上。
• 分片資訊: ZooKeeper 被用於維護分片(sharding)資訊。
• 服務層: 無狀態的錢包服務 (stateless Wallet Service) 利用分片資訊來定位客戶端所在的 Redis 節點。
• 操作: 錢包服務隨後相應地更新帳戶餘額。
2. 面試官的評論與關鍵挑戰(指出缺陷)
面試官肯定了此設計在工作方面是可行的,但立刻指出了它最大的問題——無法滿足系統對「正確性」的嚴格要求:
• 承認可行性: 面試官指出:「這個設計是可行的 (The design works)」。
• 否決原因: 面試官接著說:「但它不符合我們對正確性的要求 (but it does not meet our correctness requirement)」。
• 問題暴露: 面試官解釋了轉帳操作如何違反原子性:
◦ 錢包服務需要為每次轉帳更新兩個 Redis 節點。
◦ 無法保證這兩次更新都能成功。
◦ 失敗情境: 如果錢包服務節點在第一次更新完成之後、但在第二次更新完成之前崩潰,就會導致轉帳不完整 (an incomplete transfer)。
結論要求: 面試官強調,這兩次更新需要作為單一的原子事務 (single atomic transaction) 進行。
• 結論: 儘管它能滿足高吞吐量的需求(1,000,000 TPS),但無法保證原子性。由於一次轉帳涉及兩次獨立的更新,如果錢包服務在兩次更新之間崩潰,會導致轉帳不完整。因此,此方案因缺乏事務保證而被排除。
2.2. 方案二:基於資料庫的分佈式事務解決方案 (Database-based distributed transaction solution)
為了提供事務保證,設計從記憶體儲存轉向使用事務型關聯式資料庫。由於帳戶仍然需要分區,因此需要實施分佈式事務。

來源討論了兩種分佈式事務的實施方式:
• 兩階段提交 (2PC): 這是一種低階解決方案,依賴資料庫本身來確保原子性。然而,2PC 的主要問題是可能導致鎖被長時間佔用,並且協調者 (Coordinator) 可能成為單點故障 (single point of failure)。


• 嘗試-確認/取消 (TC/C): 這是一種高階解決方案,在業務邏輯層處理事務,因此它與底層資料庫無關。TC/C 分為兩個階段:第一階段是 Try(保留資源),第二階段是 Confirm(確認)或 Cancel(取消,即「undo」操作)。

Try (嘗試階段): 進行業務檢查,並預留必要的業務資源。例如圖中的帳戶 A 先扣除 $1,確保這筆錢被鎖定,但還沒真正交給帳戶 C。
Confirm (確認階段): 當所有參與者的 Try 都成功後,執行真正的業務操作。此階段不進行業務檢查,只使用 Try 階段預留的資源。
Cancel (取消階段): 如果有任何參與者的 Try 失敗,則執行回滾,釋放 Try 階段預留的資源(即「undo」操作)。

第一階段:Try Phase (Figure 12.7)
這是所有流程的起點。
Coordinator (Wallet Service) 發起請求。
Database A (扣款方): 執行
UPDATE將餘額減 1。這就是「預留資源」,錢已經從 A 的可用餘額中消失了。Database C (收款方): 此時執行
NOP(No Operation),意即在 Try 階段不做任何實質改動,僅確認服務可用。

第二階段:Confirm Phase (Figure 12.8)
當 Try 階段全部成功(Done)時進入此流程。
Database A: 既然 Try 已經扣過錢了,Confirm 階段只需確認(NOP),不需要再動 A。
Database C: 執行
UPDATE將餘額加 1。這完成了最終的轉帳動作。結果: A 減 1,C 加 1,事務成功完成。

第二階段:Cancel Phase (Figure 12.9)
如果在 Try 階段發生錯誤(例如圖中的 X Failed),則進入取消流程。
Database A: 因為 Try 階段已經扣了 $1,現在必須「補償」回來。執行
UPDATE balance = balance + 1,將 A 的錢加回去。Database C: 維持 NOP,因為 Try 階段本來就沒動到 C。
結果: A 的餘額恢復原狀,系統回到初始狀態,保證了一致性。
階段狀態表(Phase Status Table)
1. 階段狀態表的用途與必要性
在分佈式事務的設計中,例如 TC/C,協調者(在本案例中是錢包服務或 TCC/Saga 協調者)負責協調多個資料庫節點的更新。
• 解決的問題: 來源提到,如果錢包服務在 TC/C 處理的中途重新啟動,它可能會遺失所有先前的操作歷史記錄,並且不知道如何恢復事務。
• 解決方案: 解決方案很簡單,就是將 TC/C 執行的進度 (progress) 儲存到事務型資料庫中的階段狀態表內。

• 功能: 階段狀態表用於儲存分佈式事務的狀態,從而允許系統在協調者崩潰或重新啟動後,知道如何恢復,確保事務的持久性和一致性。
2. 階段狀態表的內容
階段狀態表儲存了確保分佈式事務能夠恢復和追蹤所需的重要資訊,包括:
1. 分佈式事務的 ID 與內容 (ID and content)。
2. Try 階段的狀態 (The status of the Try phase):記錄了給定資料庫的狀態(例如,狀態是否已發送、已接收、或已回應)。
3. 第二階段的名稱 (The name of the Second phase):根據 Try 階段的結果,可以計算出第二階段是 **Confirm(確認)**或 Cancel(取消)。
4. 第二階段的狀態 (The status of the second phase)。
5. 亂序執行狀態 (An out-of-order execution status):用於處理亂序執行的狀況。
- TC/C 發生 Out-of-order Execution
TC/C 模式處理因網路延遲導致「亂序執行(Out-of-order Execution)」的機制如下:
1. 問題場景定義
在分散式系統中,網路延遲可能導致指令到達順序與發送順序不一致。最典型的亂序場景是 Cancel 命令比 Try 命令先到達。
發生原因: 協調者(Coordinator)發送
Try後,因為網路擁塞導致超時(Timeout)。協調者隨即判定失敗並發送Cancel進行補償。結果Cancel請求比遲到的Try請求更早到達參與者節點。風險: 如果不處理,節點收到
Cancel時發現沒有Try記錄可能什麼都不做。接著Try到達並成功預留資源。但因為協調者已經發過Cancel並認為事務已結束,這筆被Try預留的資源將永遠不會被 Confirm 或釋放(資源洩漏)。
2. 解決方案:階段狀態表與亂序旗標
為了處理解決這個問題,系統必須利用 階段狀態表 (Phase Status Table) 配合特定的邏輯檢查:
步驟一:允許「空回滾」並記錄標記
當節點收到 Cancel 指令時,如果發現沒有對應的 Try 記錄,它不能視為錯誤或忽略。
邏輯: 節點必須允許在未收到
Try的情況下執行Cancel。記錄: 節點必須在 階段狀態表 中插入一條記錄,並設置一個 「亂序旗標 (out-of-order flag)」。這個旗標表示:「我已經收到過 Cancel 了,雖然我還沒看過 Try」。
步驟二:Try 階段的預先檢查
當延遲的 Try 指令最終到達節點時,系統必須執行以下檢查:
檢查:
Try操作在執行任何資源預留之前,必須先查詢階段狀態表,檢查是否已存在該事務 ID 的 亂序旗標。結果: 如果發現該旗標存在(表示 Cancel 已經先執行了),
Try操作必須返回失敗 (return a failure)。

透過在 階段狀態表 中儲存 亂序執行狀態 (out-of-order execution status),系統確保了即使 Cancel 先於 Try 執行,遲到的 Try 也不會錯誤地鎖定資源,從而保證了分散式事務在網路不穩定環境下的正確性。這也是為什麼來源強調階段狀態表是 TC/C 中處理協調者崩潰恢復與亂序執行的關鍵組件。
3. 階段狀態表的位置
階段狀態表通常儲存在包含資金被扣除的錢包帳戶(借記帳戶)的資料庫中。
在最終的高階設計中,階段狀態表與 TCC/Saga 協調者協同工作。當使用者發送轉帳命令時:
• TCC/Saga 協調者會在階段狀態表中建立一條記錄,以追蹤該事務的狀態。
• 當分區 1(帳戶 A 所在的資料庫)成功執行扣款操作後,Saga 協調者會在階段狀態表中記錄該操作成功。這確保了在執行下一步(向帳戶 C 存入資金)之前,系統狀態是可追溯和可恢復的。
總體來說,階段狀態表是將應用層實現的分佈式事務(如 TC/C 和 Saga)的狀態持久化的機制,從而將無狀態的服務轉變為具備故障恢復能力的系統。
不平衡狀態 (Unbalanced state)
「不平衡狀態 (Unbalanced state)」是在分佈式事務解決方案,特別是應用層事務模型,如嘗試-確認/取消 (TC/C) 或 Saga,執行過程中出現的一種暫時性資料不一致狀態。

這張圖片詳細解釋了在分散式事務(特別是 TCC 或 Saga 模式)中,系統處於中間過程時所產生的**「不平衡狀態 (Unbalanced state)」**。
簡單來說,它描述了「錢已經扣了,但還沒入帳」的那段暫時性消失的狀態。
圖表流程拆解
追蹤了帳戶 A 加帳戶 C 的總金額 ($A+C$) 變化:
1. 初始狀態 (Before TCC start)
狀態: 帳戶 A 有 $1,帳戶 C 有 $0。
總和: $A+C = \$1$。此時系統是平衡的。
2. 第一階段結束後 (After first phase: Try)
動作: Coordinator 執行了
Try: A-$1。資料庫 A 的餘額被更新為 $0。狀態: 帳戶 A 變成了 $0,而帳戶 C 依然是 $0。
總和: $A+C = \$0$。
現象 (Money loss): 從系統宏觀角度看,這 $1 暫時「失蹤」了。這就是圖中所標註的 「不平衡狀態 (Unbalanced state)」。這是一種暫時性的資料不一致。
3. 第二階段結束後 (After second phase: Confirm)
動作: Coordinator 執行了
Confirm: C+$1。資料庫 C 的餘額被更新為 $1。狀態: 帳戶 A 為 $0,帳戶 C 為 $1。
總和: $A+C = \$1$。
現象 (Money recovery): 隨著第二階段完成,失蹤的 $1 被找回來了,系統重新回到平衡狀態。
以下是針對不平衡狀態的詳細說明:
1. 不平衡狀態的定義與發生時機
不平衡狀態發生在分佈式轉帳操作的第一階段結束時。
• 機制: 假設有一個從帳戶 A 轉帳 1給帳戶C的操作。在∗∗TC/C的Try階段(第一階段)∗∗結束時,∗∗1 已成功從帳戶 A 扣除**,但帳戶 C 仍然保持不變(尚未收到 $1)。
• 結果: 在這個中間點,帳戶 A 和帳戶 C 的餘額總和將會是 $0(假設交易開始時總和為 $1),這小於 TC/C 開始時的總和。

2. 會計原則的違反
這種暫時的狀態被稱為「不平衡」,因為它違反了一項基本的會計原則:在一次交易之後,資金的總和應該保持不變。
• 在 Try 階段完成後,資金似乎「丟失」了 $1 (Money loss: $1),這就是不平衡狀態的體現。資金必須等到第二階段(Confirm 確認)完成後才會恢復平衡 (Money recovery: $1)。
3. TC/C 導致狀態可見性
不平衡狀態是應用層級分佈式事務(如 TC/C 和 Saga)的特性,因為這些高階解決方案是透過協調數個獨立的本地事務 (several independent local transactions) 來運作的。
• 應用程式可見: 因為 TC/C 是在應用程式層實施的,應用程式本身能夠看到這些本地事務之間產生的中間結果(即不平衡狀態)。
• 與 2PC 的區別: 相比之下,資料庫事務或兩階段提交 (2PC) 版本的集中式分佈式事務,通常會由資料庫維護這種高層次事務的抽象,因此這些不平衡狀態對於應用程式來說是不可見的。
4. 解決與處理
儘管存在不平衡狀態,事務保證仍然由 TC/C 維持。這意味著系統最終會通過執行第二階段(確認或取消)來達成最終的一致性。
• 由於高階分佈式事務會導致這種差異可見,如果底層的系統(如資料庫)沒有預先修復這些差異,那麼應用程式層必須自行處理這些不一致性 (handle them ourselves)。例如,TC/C 模式必須透過 Confirm 階段完成轉入,或者透過 Cancel 階段執行補償操作(undo)來回滾先前的操作,從而最終消除不平衡狀態。
此階段還討論了 Saga 工作流程,這是另一種應用層的分佈式事務模式。TC/C 和 Saga 都可以用來實施分佈式事務,但 TC/C 允許並行執行,而 Saga(除非使用協調模式)通常需要線性順序執行。
[Saga Pattern](https://ithelp.ithome.com.tw/articles/10236124)
[Saga, Choreography vs Orchestration](https://ithelp.ithome.com.tw/articles/10236411)
[YouTUbe Digital Wallet System Design | Distributed transactions | SAGA pattern](https://www.youtube.com/watch?v=8ByEyCd-MEM)
Saga v.s. TC/C
Saga 模式與 TC/C (Try-Confirm/Cancel) 在性能上最顯著的差異在於**「並行執行能力 (Parallel Execution)導致的延遲 (Latency)不同,以及適用交易長度**的區別。
| 角色 | 對話內容 |
| 面試官 | 我們在實務中應該使用哪一個? |
| 面試者 | 答案取決於延遲(Latency)的要求。Saga 中的操作必須按線性順序(串聯)執行,但在 TCC 中則可以並行執行。因此,這項決定取決於以下幾個因素: |
| 面試者 | 1. 如果沒有延遲要求,或者服務數量非常少(例如我們的轉帳範例),我們可以選擇其中任何一種。如果我們想追隨微服務架構的趨勢,請選擇 Saga。 |
| 面試者 | 2, 如果系統對延遲非常敏感,且包含許多服務或操作,TCC 可能是更好的選擇。 |
| 面試者 | 為了讓餘額轉帳具備事務性(Transactional),我們將 Redis 替換為 RDBMS,並使用 TCC 或 Saga 來實現分散式事務。 |
以下是差異分析:
1. 並行執行與延遲 (Parallelism & Latency)
這是兩者在架構設計上最直接的性能差異:
TC/C (低延遲,支援並行):
機制: TC/C 允許協調者在第一階段 (Try 階段) 同時向所有參與服務發送請求(例如同時預留資源 A 和資源 B)。
性能影響: 由於操作是並行執行的,總耗時取決於最慢的那個服務,而非所有服務耗時的總和。因此,TC/C 非常適合對延遲敏感 (Latency-sensitive) 的系統,,。
Saga (較高延遲,線性執行):
機制: 在典型的編排模式中,Saga 通常被設計為線性執行 (Linear execution),即操作按順序一個接一個執行(例如先扣款,成功後再觸發存款)。
性能影響: 總耗時是鏈條上所有服務耗時的總和。如果業務流程包含多個步驟,Saga 的整體響應時間會比 TC/C 長,。
2. 資源鎖定與交易長度 (Resource Locking & Transaction Duration)
兩者對資源的佔用方式不同,這決定了它們分別適用於「短交易」還是「長交易」:
TC/C (適用於短交易):
資源預留 (Quasi-Isolation): TC/C 在 Try 階段會「凍結」或「預留」資源(例如將資金移入
trading_balance欄位)。雖然這不是資料庫層級的死鎖,但在 Confirm/Cancel 完成前,這部分資源是無法被其他事務使用的,。性能限制: 由於應用程式崩潰可能導致預留狀態遺失,且長時間預留會影響業務並發度,TC/C 被設計用來處理短時間且要求高一致性的交易,。
Saga (適用於長交易 - Long Lived Transactions):
無鎖/立即提交 (Lock-free): Saga 的每個本地事務執行完後會立即提交 (Commit) 到資料庫,不進行資源預留。這意味著資源鎖定時間極短,。
性能優勢: 由於不長時間佔用資源,Saga 非常適合處理跨越數分鐘甚至數天的長事務 (LLTs),在這種場景下它能維持高吞吐量,不會像 2PC 或 TC/C 那樣因為長時間佔用資源而導致性能瓶頸,,。
3. 補償成本 (Compensation Cost)
TC/C (輕量回滾): TC/C 的 Cancel 操作通常只是釋放 Try階段預留的資源(例如解凍資金),邏輯相對簡單且副作用較小,。
Saga (昂貴補償): 由於 Saga 的本地事務已提交,若後續步驟失敗,必須執行補償事務 (Compensating Transaction) 來「修正」數據(例如退款)。這通常涉及新的業務邏輯寫入(如新增一條負向流水的紀錄),在性能開銷和開發複雜度上可能較高,。
總結比較表
| 特性 | TC/C (Try-Confirm/Cancel) | Saga |
| 執行順序 | 可並行 (Parallel) | 線性/順序 (Linear) |
| 延遲 (Latency) | 低 (取決於最慢的服務) | 高 (所有步驟耗時總和) |
| 資源佔用 | 預留資源 (準隔離性),佔用時間較長 | 立即提交 (無隔離性),佔用時間極短 |
| 適用場景 | 短交易、高併發、對延遲敏感 | 長交易 (LLT)、非同步流程, |
結論: 如果您的系統追求極致的低延遲且能接受較高的開發成本(需實作 Try/Confirm/Cancel 三個接口),TC/C 是性能較佳的選擇;如果您處理的是長流程且希望避免資源鎖定,Saga 則能提供更好的系統吞吐量。
面試官: 分散式事務解決方案雖然有效,但在某些情況下可能表現不佳。例如,用戶可能在應用層輸入了錯誤的操作,在這種情況下,我們指定的金額可能是錯誤的。我們需要一種方法來追蹤問題的根因,並審計(Audit)所有帳戶操作。我們該如何做到這一點?
- 2.3. 方案三:具備可重現性的事件溯源解決方案 (Event sourcing solution with reproducibility)
此方案是為了滿足面試官提出的對審計和追蹤問題根本原因的更高要求。
1. 為什麼選擇事件溯源? (Background)
在面試場景中,面試官提出了一個關鍵挑戰:外部審計員可能會問:「我們如何知道任何給定時間點的帳戶餘額?」或「我們如何證明程式碼更改後的系統邏輯仍然正確?」。
傳統資料庫只儲存當前的狀態 (Current State)(例如:餘額 $10),一旦更新就覆蓋了舊值,丟失了變更的歷史軌跡。事件溯源正是為了回答這些問題而引入的設計哲學。
• 核心理念: 事件溯源 (Event Sourcing) 哲學將所有狀態變化儲存為不可變的事件清單,而不是只儲存最終的餘額狀態。
• 可重現性: 事件清單是不可變的,狀態機 (State machine) 的行為是確定性的,因此系統可以透過重放 (replaying) 事件來重建歷史狀態。這是事件溯源相對於其他架構的最大優勢。
• 狀態機: 狀態機在事件溯源中扮演核心角色,負責驗證命令 (Validate commands) 和應用事件 (Apply event) 來更新狀態。
2. 四個核心概念 (Definitions)

事件溯源的四個重要術語,:
命令 (Command):
這是來自外部世界的意圖 (Intended action)。例如:「從 A 轉 $1 給 C」。
命令不是事實,它可能會失敗(例如餘額不足)。命令必須按順序放入 FIFO 佇列中。
事件 (Event):
這是已經發生並經過驗證的事實 (Validated fact)。例如:「從 A 轉了 $1 給 C (Transferred $1 from A to C)」。
不可變性: 事件一旦生成,就永遠不能被改變。
區別: 一個命令可能產生零個或多個事件。事件代表過去式。
狀態 (State):
- 這是在應用事件後變更的內容。在錢包系統中,狀態就是客戶的帳戶餘額 (Map<User, Balance>)。
狀態機 (State Machine):
這是驅動事件溯源過程的引擎。它有兩個主要功能:
驗證命令並生成事件 (Validate commands and generate events)。
應用事件以更新狀態 (Apply event to update state)。
關鍵特性 - 確定性 (Deterministic): 狀態機的行為必須是嚴格確定性的。它不能包含任何隨機性(如隨機數、依賴系統時間或外部 I/O)。這保證了只要輸入相同的事件序列,無論何時重播,輸出的狀態永遠一致。
3. 運作流程 (Dynamic View)
狀態機處理請求的流程如下,:
讀取命令: 從命令佇列(如 Kafka)讀取轉帳請求。
讀取狀態: 從資料庫讀取當前的餘額。
驗證邏輯: 檢查餘額是否足夠。
生成事件: 如果驗證通過,生成事件(如
MoneyDeducted)。應用事件: 更新資料庫中的餘額。

系統分為三個層次:Command(指令)、Event(事件) 與 State(狀態)。
指令經過驗證(Validate)後轉化為事件,事件被應用(Apply)後改變狀態。
錢包服務範例 (Wallet Service Example):

Command 是來自外部世界(客戶端)的請求。它不是事實,因為它可能會失敗(例如餘額不足或驗證失敗)。Command 會被放入一個 FIFO 隊列中等待處理。
{ "name": "TransferRequest", "payload": { "transaction_id": "81589980-2664-11ec-9621-0242ac130002", // 用於去重 (Deduplication) "from_account": "A", // 扣款帳戶 "to_account": "C", // 收款帳戶 "amount": "1.00", // 金額 (字串類型以避免精度丟失) "currency": "USD" // 貨幣類型 }, "timestamp": "2023-10-27T10:00:00Z" }
Event 是經過狀態機驗證後產生的結果。它代表已經發生且不可變 (Immutable) 的歷史事實。
事件 1:扣款事件 (針對帳戶 A) { "name": "MoneyDeducted", // 過去式,表示已發生 "payload": { "account_id": "A", // 影響的帳戶 "amount": "1.00", // 變動金額 "transaction_id": "81589980-2664-11ec-9621-0242ac130002", // 關聯的交易 ID "new_balance": "9.00" // (可選) 有些設計會包含結果餘額,或由重播計算 }, "sequence_id": 101, // 用於確保順序 "timestamp": "2023-10-27T10:00:01Z" } 事件 2:入帳事件 (針對帳戶 C) { "name": "MoneyCredited", // 過去式 "payload": { "account_id": "C", "amount": "1.00", "transaction_id": "81589980-2664-11ec-9621-0242ac130002" }, "sequence_id": 102, "timestamp": "2023-10-27T10:00:01Z" }
在錢包服務中,「指令」就是轉帳請求。
* 這些指令會進入一個 FIFO Queue。實務上常用的選擇是 Kafka。
* 當狀態儲存在關聯式資料庫時,狀態機按以下 5 個步驟執行:
1. Read commands: 從指令隊列(Command Queue)讀取指令。
2. Read balance: 從資料庫讀取目前的餘額狀態。
3. Validate: 驗證指令(例如餘額是否充足)。若有效,為涉及的帳戶生成事件。
* 範例: 指令是「A 轉 $1 元給 C」,會生成兩個事件:「A: $-$1」與「C: $+$1」。
4. Read next event: 讀取生成的事件。
5. Apply event: 通過更新資料庫中的餘額來應用事件。
4. 核心優勢:可重現性 (Reproducibility)
這是事件溯源相對於其他架構的最大優勢。由於事件列表是不可變的,且狀態機是確定性的,系統可以透過從頭重播 (Replay) 所有事件來隨時重建歷史上的任何狀態。這完美解決了對帳與審計的需求,也能用來驗證修復 Bug 後的邏輯是否正確,。

審計問題的解答 (Final Section)
事件溯源能回答以下三個關鍵問題:
我們能否知道任何特定時間點的帳戶餘額?
- 回答: 可以,透過從起點重放事件,直到你想知道的那個時間點為止。
我們如何知道歷史與目前的餘額是正確的?
- 回答: 透過事件列表重新計算來驗證。
如何證明代碼更動後系統邏輯依然正確?
- 回答: 可以針對同一組事件運行不同版本的代碼,驗證其產出的結果是否一致(即 Regression Testing)。
結論: 由於具備強大的審計能力,事件溯源通常被視為錢包服務(Wallet Service)的標準解決方案。
5. CQRS 架構 (Command-Query Responsibility Segregation)
[CQRS亂談](https://ithelp.ithome.com.tw/articles/10237458)

由於事件溯源主要處理寫入,且只是一堆事件日誌,客戶端很難直接查詢「我現在有多少錢」。因此系統採用了 CQRS,:
寫入路徑 (Write Path): 由上述狀態機負責,處理命令並生成/儲存事件。
讀取路徑 (Read Path): 由 唯讀狀態機 (Read-only state machines) 負責。它們訂閱事件流,並計算出狀態,儲存到專門用於查詢的資料庫或視圖 (View) 中。客戶端查詢時是訪問這個讀取層。
特性: 讀取層可能有輕微的延遲(最終一致性),但在金融系統中,這通常是可接受的,且能提供完整的審計軌跡。
6. 深入設計:高效能與可靠性優化 (Deep Dive)
為了達到 100 萬 TPS 的目標,簡單的 Kafka + 資料庫方案是不夠的。所以能考慮進行深度的技術優化:
A. 檔案基於的命令與事件儲存 (File-based Storage)
問題: 透過網絡訪問遠端儲存(如 Kafka 或傳統 DB)太慢。
優化: 將命令和事件直接保存在本地磁碟 (Local Disk) 的追加日誌檔 (Append-only file) 中。
技術: 利用 mmap (Memory Mapped File) 技術。這將磁碟文件映射到記憶體數組中,將寫入操作轉換為記憶體操作,並由作業系統負責刷入磁碟。這將隨機 I/O 轉換為極快的循序 I/O (Sequential I/O)。
B. 狀態儲存 (Local State)
- 使用嵌入式的高效能資料庫,如 RocksDB 或 SQLite,直接在本地儲存狀態(餘額),避免遠端資料庫調用的開銷。RocksDB 使用 LSM-tree 結構,非常適合高寫入場景。
C. 快照 (Snapshot)
為了避免每次重啟都要從「創世區塊」重播數百萬個事件,系統會定期將當前的狀態存成快照。
恢復時,只需讀取最近的快照,然後重播該快照之後的事件即可。
D. 可靠性:Raft 共識演算法 (Consensus)
[etcd Raft淺談(上) 名詞簡介](https://ithelp.ithome.com.tw/articles/10239673)
風險: 使用本地磁碟儲存雖然快,但如果該節點掛了,資料就丟了(單點故障)。
解決方案: 引入 Raft 共識演算法。
運作: 系統將節點組成一個 Raft 群組(1 個 Leader,多個 Follower)。
Leader 接收命令並轉換為事件。
Raft 負責將事件列表 (Event List) 複製到其他 Follower 節點。
只要大多數節點存活,資料就不會丟失。
這確保了在本地高效能儲存的基礎上,同時擁有分散式系統的高可用性與資料一致性。
為什麼「事件 (Event)」是可靠性的核心?
為什麼我們備份「事件」而不是「指令」或「狀態」。
指令 (Command) 不具備決定性: 指令在轉化為事件的過程中,可能包含隨機數或外部 I/O。如果只記錄指令,重新執行時結果可能不同。
事件 (Event) 是既定事實: 事件代表已經發生的歷史紀錄(如:帳戶餘額變動),它是不可變 (Immutable) 的。
結論: 只要確保「事件列表」具備高可靠性,我們隨時都能透過重放 (Replay) 事件來還原系統狀態。
利用 Raft 演算法達成共識
為了避免單點故障,需要將事件列表同步到多個節點。
多數決原則 (Majority): 只要集群中超過半數的節點正常運作(例如 5 台中有 3 台活著),系統就能持續運作。
角色分工:
Leader (領導者): 負責接收外部指令、轉換成事件,並同步給其他節點。
Follower (跟隨者): 接收來自 Leader 的事件並存檔。
Candidate (候選人): 競選 Leader 時的過渡狀態。
解決效能瓶頸:分片與即時性
單一 Raft 組無法支撐百萬級 TPS,因此需要擴展架構。
資料分片 (Sharding):根據 Key 的雜湊值將資料切分到不同的 Raft 組(Partition)。(Multi Raft Group)
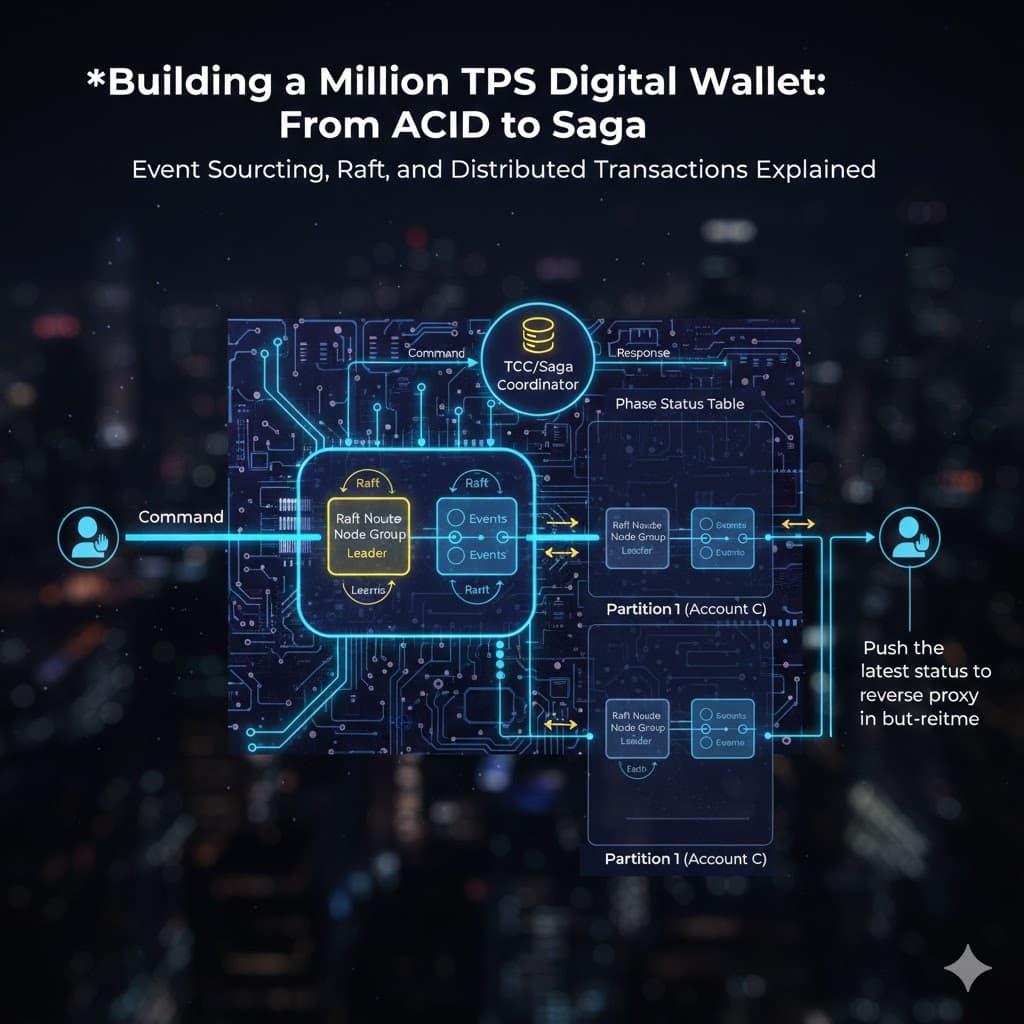
從「拉」到「推」:為了避免客戶端因輪詢 (Polling) 產生的延遲,引入 反向代理 (Reverse Proxy)。當狀態機完成更新時,主動將結果推送給反向代理,給予用戶即時的回饋感。
跨區交易:Saga 分散式事務
當一筆交易(如轉帳)跨越兩個分片時,需要 Saga 協調器 (Coordinator) 來確保一致性。
轉帳成功流程 (Happy Path):
發起請求:用戶 A 要求轉帳 $1 給用戶 C。
狀態追蹤:協調器在狀態表中建立記錄。
分片 1 執行 (扣款):協調器發送指令給 Partition 1。Leader 將其轉為事件、同步 Raft,並執行扣款。成功後透過讀取路徑回傳狀態給協調器。
分片 2 執行 (存款):協調器確認扣款成功後,發送指令給 Partition 2 執行存款。同樣完成 Raft 同步後回傳成功訊息。
結束交易:協調器更新狀態表,完成整個分散式事務。
架構總結表
| 組件 | 解決的問題 | 關鍵機制 |
| Event Sourcing | 數據一致性與可追溯性 | 指令轉事件、事件不可變性 |
| Raft Algorithm | 服務高可用性與防單點故障 | 多數決同步、Leader 選舉 |
| Sharding | 系統吞吐量 (TPS) 限制 | 按 Hash 分片處理 |
| Saga Model | 跨分片的數據一致性 | 協調器、階段性狀態追蹤 |
在分散式架構中,當多個請求同時想對同一個帳戶(用戶 A)進行操作時,系統設計主要透過 「排序」 與 「驗證」 兩個核心機制來確保資料正確性。
1. Raft Leader 的序列化 (Serialization)
在 Partition 1 的 Raft 組中,只有一個 Leader 負責接收所有指令。
指令排隊:不論有多少個 Saga 協調器同時發送「扣款用戶 A」的指令,Partition 1 的 Leader 都會將這些指令放入一個指令列表 (Command List) 中。
單一順序:Leader 會按照接收順序,一個接一個地處理這些指令。這意味著在技術層面上,對同一個用戶的操作已經在進入系統的第一關被「排好隊」了。
2. 狀態驗證與事件轉換 (Validation)
當 Leader 處理到某個扣款指令時,它會執行以下動作:
即時驗證:Leader 會根據目前的狀態機(State Machine)檢查用戶 A 的餘額是否足夠。
轉換為事件:如果餘額足夠且指令合法,Leader 才會將其轉換為「事件(Event)」並寫入 Log。
失敗處理:如果前一筆轉帳已經扣光了錢,第二筆指令在「驗證」階段就會被 Leader 拒絕,不會產生事件,也不會進行後續的 Raft 同步。
3. 分散式事務的狀態鎖定 (Isolation)
在 Saga 模型中,為了防止「超支」或「髒讀」,通常有兩種常見的設計模式:
| 模式 | 處理方式 | 特點 |
| 悲觀鎖 (Pessimistic) | 進入 Saga 後,先將用戶 A 的餘額「凍結」(Reserved)。 | 確保後續一定有錢扣,但會降低帳戶的可用性。 |
| 補償機制 (Compensating) | 直接執行扣款事件。若後續(如 Partition 2)失敗,再執行一個「加回餘額」的反向事件。 | 效能較高,是 Saga 的標準作法。 |
當用戶 A 同時有兩筆轉帳請求時:
第一筆請求到達 Leader,Leader 檢查餘額夠,轉換成「扣款事件」,同步給 Follower 並完成扣款。
第二筆請求在 Leader 的隊列中等待,輪到它時,Leader 發現餘額已經被第一筆扣掉了。
結果:Leader 直接回傳錯誤給 Saga 協調器,該筆交易失敗,不會影響系統一致性。
如果第一筆交易在 Partition 1 扣款成功,但最後在 Partition 2 失敗時,系統是如何幫用戶 A「把錢還回來」的(補償機制)?
簡單來說:既然錢已經扣了,我們就再發一個「存回去」的動作來抵銷。
總結
該章節描述的 Event Sourcing 方案,是從一個簡單的概念演進為一個工業級的高頻交易引擎:
利用 事件不可變性 解決審計問題。
利用 CQRS 解決查詢問題。
利用 mmap/RocksDB (本地循序 I/O) 解決吞吐量問題 (1M TPS)。
利用 Raft 解決本地儲存的可靠性問題。




