

Day 4 性能分析常見外部指標

今天來聊常見的性能問題,和如何進行相應的性能分析。通常性能問題的顯現會用指標來展示。但指標的背後可能是內部瓶頸或資源的制約所致。
性能的外部指標
在性能分析中,外部指標是最直觀反映系統或應用程式性能的方式。這些指標通常用來描述使用者體驗和系統的運行效率,其中包括 Service Latency、Throughput 和 Resource Utilization。
Service Latency
處理延遲指的是從使用者發出請求到收到回應所需的時間。這個指標直接影響使用者體驗,因此在性能測試中,我們通常進行端到端(E2E)的測試,而不是僅僅測試系統架構中的某一個節點。這樣可以確保我們捕捉到整體性能表現,而不僅僅是某個局部的表現。
延遲的增加可能反映了系統內部的多種潛在問題,例如資料庫查詢速度變慢、後端服務之間的通訊效率降低,甚至是應用層面的資源鎖競爭。這些問題都會導致使用者在發出請求後需要等待更長的時間來獲得回應。因此,延遲分析不僅能幫助我們了解使用者體驗,還能讓我們深入挖掘系統內部的性能瓶頸所在。
Throughput
吞吐量,指的是單位時間內可以成功處理的請求數量或完成的工作任務數量。 這指標其實與 Latency 指標相輔相成,只是一個注重時間,一個注重空間,也就是系統容量。通常一個系統的外部性能主要就是受限於這兩個條件的約束,缺一不可。
相輔相成的意思是這兩個指標通常要一起來分析。如果一個電商系統每秒可以提供十萬吞吐量,也就是它能同時服務約十萬的使用者。但是使用者的處理延遲是5分鐘以上,那麼這十萬吞吐量在這樣的表現下是毫無意義的,因為沒有使用者能接受每個請求處理幾乎都要等5分鐘在那邊排隊。這裡又能提到排隊理論。反之,如果延遲很低,但吞吐量超少,這樣的系統就不太好用了。
所以,一個對外服務必然受到者兩個條件的同時作用。
此外,吞吐量還受到系統的架構設計、併發處理能力和資源分配策略的影響。舉例來說,如果系統的資源分配不合理,導致某些關鍵資源(如 CPU 或 I/O)過度飽和,這將直接限制系統的吞吐量,進而影響整體性能。因此,通過監控和分析吞吐量,我們可以識別出系統中的瓶頸資源,從而為進一步的性能優化提供依據。
Resource Utilization
從上面就能知道系統和各自的服務都需要容量來支撐的,所以資源利用率就至關重要了,因為這直接決定了系統和各自服務的運營成本。如果配置給一個服務 1 Core+2GB Ram 但卻最高只用到 20%,但雲端供應商還是會收 100%的費用的,就算是地端該機器的成本也已經在購買時就投入了。
這一個指標雖然主要是面向系統的資源用量的,但其實跟使用者也直接相關。如果資源使用率偏低,例如 CPU 使用率偏低,但在系統容量固定(比如叢集內的服務節點數量固定)的情況下,吞吐量也可能會比較低,或是處理延遲比較高,這是因為系統資源沒有被充分利用。
資源利用率的高低還會影響到系統的可擴展性和穩定性。在雲端原生環境中,資源利用率的優化不僅僅是為了節省成本,更是為了提升系統的動態調整能力。比如,在一個高流量的應用中,如果能夠有效地利用資源,那麼當流量突增時,系統能夠迅速擴展資源,滿足更大的請求需求。同時,合理的資源利用也能減少系統故障的風險,因為過度飽和的資源往往是故障的根源之一。
此外,在OpenTelemetry 入門指南第三章介紹的四個黃金信號與U.S.E. method都有 Saturation 飽和度這指標。飽和度與 Resource Utilization 密切相關。當系統接近飽和狀態時,資源利用率通常會達到峰值,導致性能下降,這時就會看到吞吐量的減少和延遲的增加。
總結來說,Golden Four Signals 和 U.S.E. 方法都提供了分析和優化系統性能的框架,這些方法可以幫助識別和理解你所提到的 Service Latency、Throughput 和 Resource Utilization 指標之間的關聯性。通過結合這些概念,我們可以更全面地進行性能分析,識別瓶頸,並進行有效的優化。
外部性能指標的變化
從上述的描述,我們現在知道這三個性能指標有自己的特點,但也經常會相互影響。
對一個系統來說,如果 Throughput 很低,那麼 Latency 通常會表現得很穩定。而當 Throughput 突然變高時, Latency 一般來說也會隨之增加。
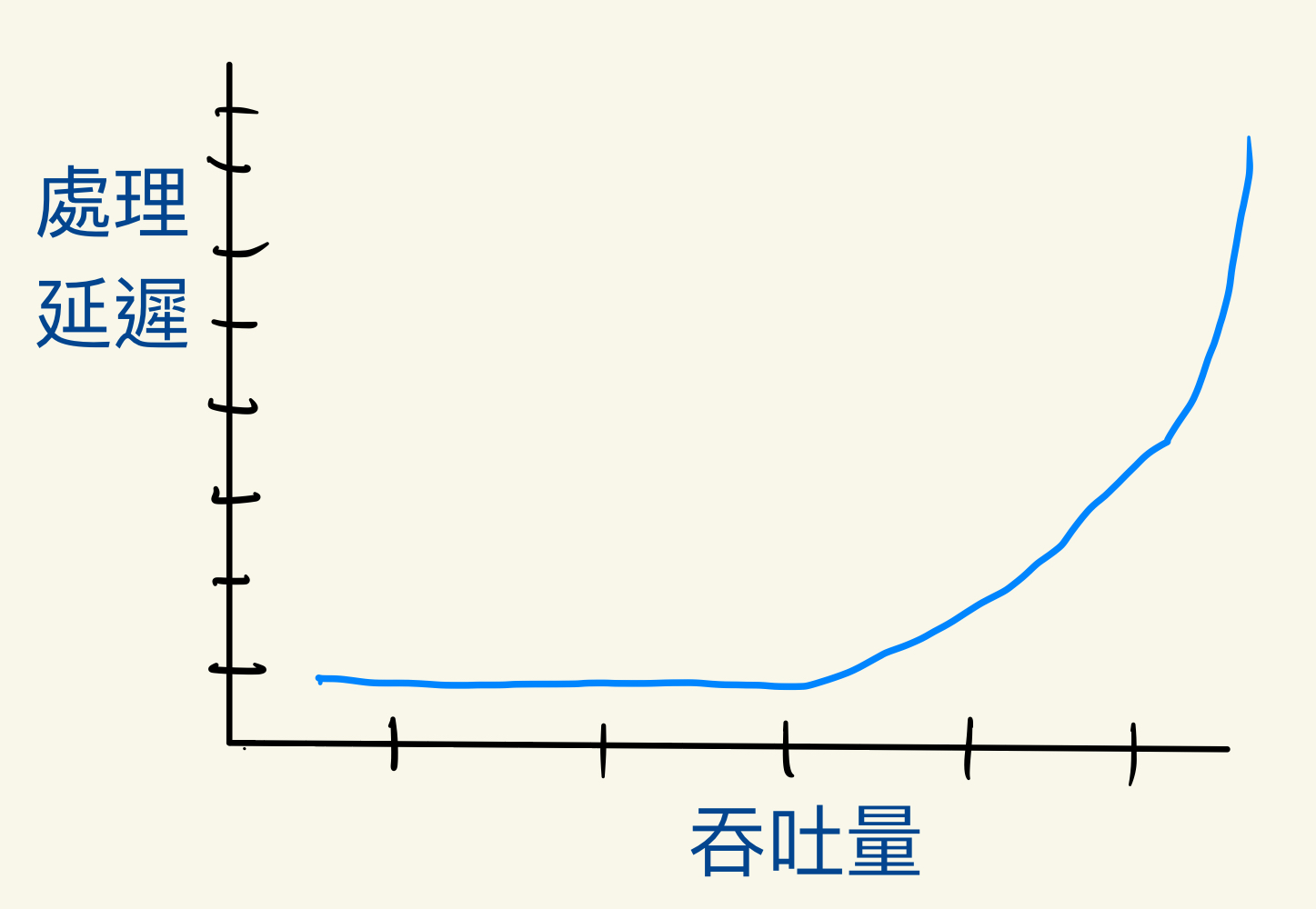
這圖想說明的是通常在 throughput 低於假設每秒500時,處理延遲會小於50ms,這延遲長期觀察起來非常的穩定。但隨著 throughput 逐漸增高, latencyt 也飛速攀升。一般而言,根據系統被規定的可接受的處理延遲快慢,我們會需要在系統層面上控制負載流量,以免處理延遲過大而直接影響使用者體驗。
此外在分析處理延遲時,不僅要計算 AVG,還要注意延遲的分佈情況,例如,有百分之幾的請求在服務允許的最大延遲範圍內,有百分之幾的略為超過了,有百分之幾的是完全無法接受的程度。因為出問題的時候,通常 AVG 指標是達標的不會觸發警報,但很大比例(可能10%~25%)的請求處理的情況是超出了我們設定的可接受範圍。
所以在設定 SLO 時,除了設定AVG均值的標準外,還要定義百分位數的可以接受值。比如,AVG 50 ms,P90 <= 80ms,P99 <= 100ms 等等,這些一起被納入計算才會準確。
關於 Throughput ,其實現實的系統一定有一個峰值極限存在。超過這峰值極限後,系統就會進入超載狀態,除了服務的整體處理延遲會超標外,還會造成一系列相關的性能問題(例如排隊延遲增加、錯誤率上升、資源耗盡、死鎖、GC、服務 crach和雪崩效應...)。這個峰值極限往往需要經過全面且詳細的性能測試,並且結合 Service Latency 這些指標來確定。 只要確定了這系統峰值值後,之後面對需求的設計方案或維運就需要確保系統的負載不會超過這個值。
在考慮 Resource Utilization 的標準時,除了運營成本和系統容量外,還有幾個重要的因素需要考慮,包括意外事件的緩衝(Buffer)、災難恢復(Disaster Recovery, DR)、冗餘設計(Redundancy)、可擴展性(Scalability)、熱點管理(Hotspot Management)、容錯性(Fault Tolerance)以及資源使用率與性能的非線性關係。這些因素在實際運營中對於維護系統的穩定性至關重要。
小結
各種性能問題雖然表現各異,但歸根總結就是某個資源不夠。而處理請求時在某個地方被卡住了,這個卡住的地方就叫做瓶頸。
瓶頸通常發生在四類地方︰軟體程式、CPU與記憶體、I/O、網路。
一個核心觀點、瓶頸是導致系統性能問題的根本原因,而 Profilling 性能分析的目的是找出這些瓶頸並加以解決。所以我們掉實驗調查順序會是︰
- 瓶頸的存在:首先,當系統在某個環節「卡住」時,這個地方就成為了瓶頸。瓶頸的存在意味著該環節的資源已經達到了其處理能力的極限,無法再高效地完成更多的任務。這個瓶頸直接導致了整個系統的性能問題,比如高延遲、低吞吐量等。
- 性能分析的必要性:既然瓶頸是系統性能問題的根本原因,那麼要改善系統的性能,就必須找出這些瓶頸所在的位置。這就是 Profilling 性能分析的目的。性能分析是一個系統化的過程,通過測試和分析系統的各個部分,來識別出哪個部分成為了瓶頸。
- 瓶頸分類和深入分析:在你的描述中,瓶頸被分為了四大類,這使得性能分析有了一個明確的方向和目標。通過針對不同類型的瓶頸進行測試和分析,我們可以了解每個瓶頸可能涉及的具體資源問題,比如 CPU 性能、記憶體頻寬、網路延遲等。
- 從瓶頸到優化:找到瓶頸之後,性能分析就進入了優化階段。具體的優化方式通常是針對瓶頸的資源進行擴充或調整,比如增加記憶體、優化 CPU 使用效率、提升 I/O 性能等,這樣可以有效地緩解或消除瓶頸,從而提高系統的整體性能。
而主流的程式語言都有 Profiler 工具來進行性能分析,像 Java 有 JVMTI。而 Python 有 sys.setprofile 函式。Go 有更多豐富的 Profiler 工具,這個在之後的部份再來一一介紹。




