

Day 7 閒聊I/O密集型任務與 Context Switch

突然今天想寫這篇是因為 Line 社群有網友問到 I/O密集型任務 如果開大量 Thread 或是將這個任務以容器啟動了數十個容器在消費從 Message Queue 接收到的事件,然後做大量的 I/O 密集任務。會不會導致 Context Switch ?以及如果真要提高吞吐量與處理效能,開大量 Worker 是常見的方式,但要怎能知道開多少數量的 Worker 在這台機器上適合呢?
今天先從資源使用情況來看,明天在從任務的執行時間來分析。
今天會講比較多基本知識先了解打底用,也能當我在混天數吧 :)
CPU 使用率
CPU 的使用率可以透過測量一段時間內 CPU 忙於執行任務的時間比例獲得,通常以百分比 % 表示。也可以透過測量 CPU 未執行 kernel idel 的時間得出,這段時間內 CPU 可能會執行一些 user level 的應用程式,或其他的 kernel 程式,或者在處理 interrupt。
CPU 使用率高不代表一定有問題,只能說系統有在工作。也有人認為這是投資回報率(ROI)的指標,畢竟機器買了租了就用好用滿。CPU 資源高度被利用的系統認為有著較好的 ROI,而空閒太多的系統則是浪費。這點與硬碟(I/O)有著很大的不同。
ROI 很重要,一開始就用的好,則花費都用在刀口上。
後期才投入分析的話,那就是省運行成本,看能否跟老闆凹,省下來的10%當bonus吧!
在OpenTeletetry 入門指南,第 2 章也有提到可觀測性工程對於數位轉型的 ROI 是否幫助的。
CPU 使用率高,不等於應用程式的性能跟著出現顯著的下降!因為 kernel 支援優先級別的處理、搶佔處理和分時共享處理。這些概念組合起來讓 kernel 決定了什麼應用程式或執行緒的優先級更高,並保證它優先執行。
CPU 的時間花費在處理 user space 的時間稱為 User-CPU-Time,而執行 kernel 類型的時間稱為 System-CPU-Time。 System-CPU-Time 包含系統底層調用、kernel 執行緒和處理 interrupt 的時間。在整個系統範圍內進行量測時,User-CPU-Time 與 System-CPU-Time的比例揭示了該系統執行的負載類型。
如果User-CPU-Time 比例很高,那麼可能就在處理像是影像處理、機器學習、數學運算或數據分析等。
反之,如果 System-CPU-Time 很高,則可能是 I/O Intensive Workload,通過 kernel 在進行 I/O 操作。
I/O Intensive Workload
又稱 I/O-bound 或 I/O 密集型工作負載。這裡的 bound 或 intensive,指「受限於」或「受制於」。當我們說一個任務是「I/O-bound」時,意思是這個任務的性能或速度主要受限於 I/O 操作的速度,而非 CPU 的處理能力。
當一個任務是 I/O-intensive 時,系統的其他資源(例如 CPU、記憶體等)可能無法被充分利用。這是因為系統必須等待 I/O 操作完成,而在這段等待時間內,其他資源可能處於閒置或低效狀態。也就是說,儘管 CPU 可能有足夠的能力處理更多的計算任務,但由於 I/O 操作成為瓶頸,整個系統的資源利用率會受到限制。
例如,在一個 I/O-bound 系統中,即使 CPU 的利用率很低,系統整體的性能也可能達不到預期,因為它主要受限於磁碟或網路 I/O 操作的速度和容量。這種情況下,即便增加更多的 CPU 或記憶體資源,也無法顯著提高系統性能,因為真正的瓶頸是 I/O 操作。
相呼應的是速度,系統在處理這類任務時,CPU 的計算能力可能有富餘,但由於需要等待 I/O 操作(例如讀取磁碟、網路請求、文件讀寫等)完成,整體系統的速度和性能會受到這些 I/O 操作的制約。因此,任務的執行效率主要取決於 I/O 操作的效率,而不是計算的速度。
舉例來說,假設一個應用程序需要頻繁地從磁碟讀取數據並進行處理,如果磁碟讀取速度較慢,即使 CPU 再快,也要等待數據讀取完成後才能繼續處理。這時候,我們就可以說這個任務是「I/O-bound」,因為它的性能主要受限於磁碟的 I/O 速度。
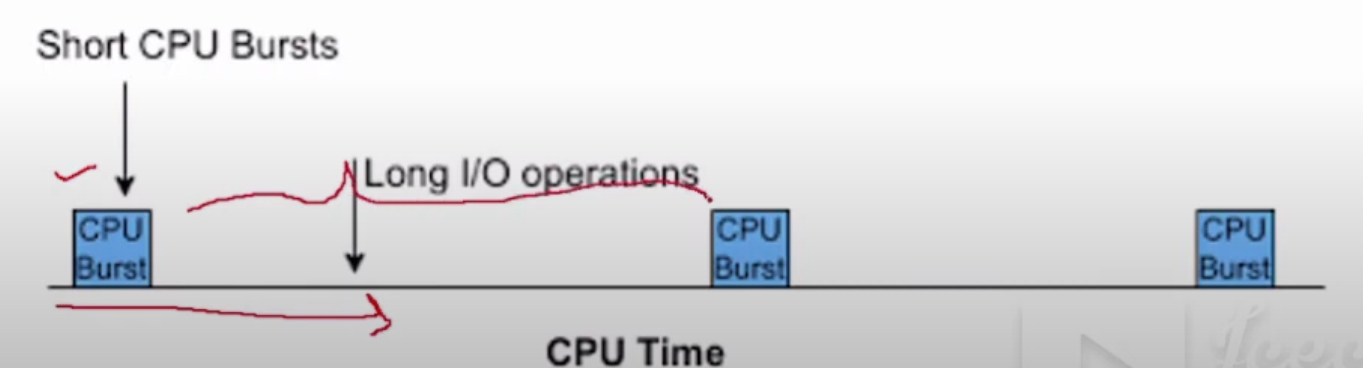
[YouTube I/O Bound Process](https://youtu.be/6CegqIE-yxk?t=204)
該影片用圖簡單闡述,I/O Bound 的處理,其實真正用到 CPU 的時間很少很少。但對於一個I/O操作具體什麼時候能回應,其實是未知的。由於 I/O 操作的延遲不可預期,這就導致了系統在等待 I/O 回應的過程中,CPU 的資源可能無法被充分利用。在這些等待期間,CPU 可能切換到另 一個可以利用 CPU 資源任務的執行,這就引出了 CPU Context Switching 的概念。
CPU Context Switching
Context
這裡指的 Context,指的是該應用程式/Thread/Coroutine 等等在執行時的環境,包含了所有的 Register 的內容、該應用程式正在使用的文件(或你說 FileDescriptor)、記憶體中的等變數內容(MMU)等等。
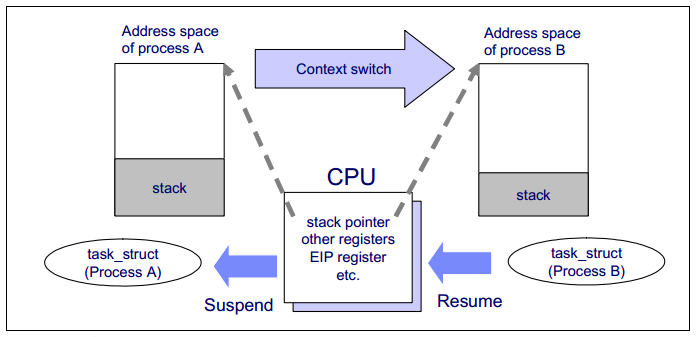
[圖片來源 CPU 上下文切換](https://jaminzhang.github.io/os/CPU-Context-Switch/)
上圖示意,同一個 CPU 從 Process A 切換至 Process B 來執行的流程跟需要用到的 context 內容,過程中會進行現有 context 的儲存,已經載入新的 context。
其實 CPU context swithing 細說有三種,Process context switching、Thread context switching 與 Interrupt Context Switching。有興趣能根據這關鍵字去搜尋學習。
這三種類型的 context switching 切換的成本依序是 Process context switching > Thread context switch > Interrupt Context Switching。
在 Linux 系統中,這些 context switching 共同協作,以確保系統能夠多任務併發運行,並及時回應各種事件和操作。但這些 switching 其實都有成本與開銷,如果設計軟體時沒設計好,就會產生巨量的 context switching 其實反而沒達到當初想要的吞吐量與效能,反而表現的會更差。
用 Go 產生大量的 context switching
通過增加大量的 Worker 或 Thread 來提高吞吐量是一種常見的優化方法,但我們需要謹慎地評估系統的 context switching 頻率,因為過多的 context switching 可能會使問題更加嚴重。
Go 有個函式 Gosched() 可以強制讓該 goroutine 釋放所佔有的 CPU,來讓其他 gorouine 能使用該 CPU 處理事情。搭配 GOMAXPROCS() 限定該程式最多使用 1 個 CPU 核心。透過模擬單核心環境中的行為,這樣所有的goroutine 都必須在同一個 CPU 上執行,這也意味著它們需要更多的 context switching 來共享這個 CPU 處理時間。
package main
import (
"flag"
"fmt"
"log"
"os"
"os/signal"
"runtime"
"sync"
"syscall"
)
func excessiveWorker(id int, wg *sync.WaitGroup) {
defer wg.Done()
for {
// 模擬大量的磁碟 I/O 操作
data := make([]byte, 1024*1024*1) // 1MB 大小的資料
err := os.WriteFile(fmt.Sprintf("/tmp/testfile_%d", id), data, 0644)
if err != nil {
continue
}
_, err = os.ReadFile(fmt.Sprintf("/tmp/testfile_%d", id))
if err != nil {
continue
}
runtime.Gosched()
// 模擬取得資料後的計算
sum := 0
for i := 0; i < 1000; i++ {
sum += i
}
}
}
func main() {
numWorkers := flag.Int("workers", 1000, "number of workers to start")
procs := flag.Int("procs", 1, "number of go max procs")
flag.Parse()
runtime.GOMAXPROCS(*procs)
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
var wg sync.WaitGroup
for i := 0; i < *numWorkers; i++ {
wg.Add(1)
go excessiveWorker(i, &wg)
}
fmt.Printf("Running workers: %d", *numWorkers)
go func() {
<-sigChan
log.Println("Received signal, shutting down...")
os.Exit(0)
}()
wg.Wait()
}
go build -o cs main.go
./cs
在我執行該程式後,首先我先使用 TOP 這工具做簡單的觀察,
執行程式之前

執行程式之後
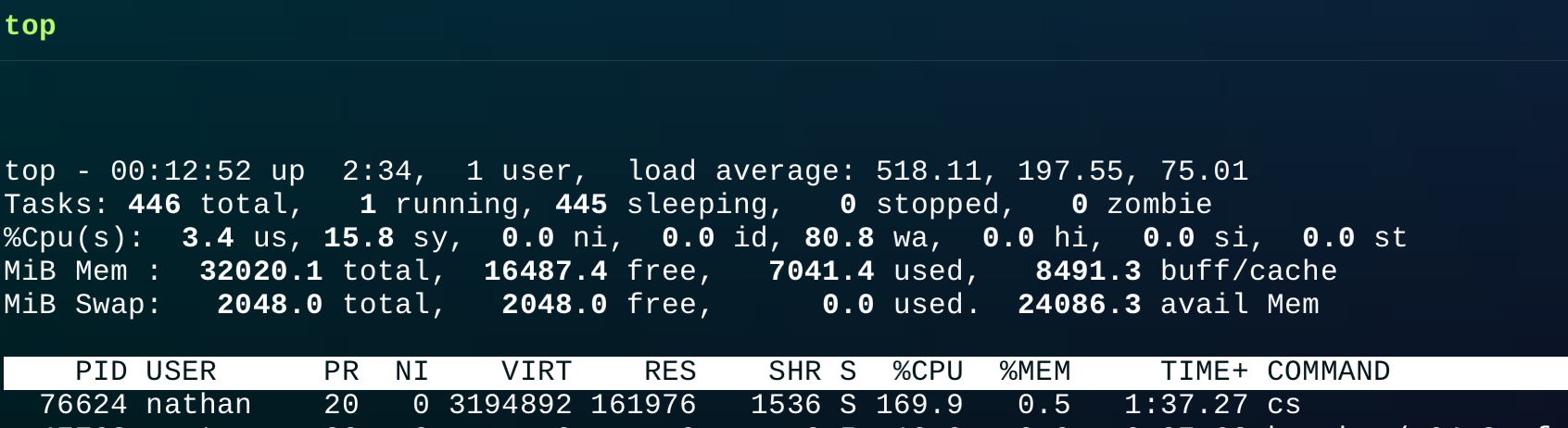
能看見load average 瞬間來到五百多。load average: 518.11, 197.55, 75.01分別表示系統在過去 1 分鐘、5 分鐘和 15 分鐘內的平均負載。這些數值非常高,表示系統的運行隊列中有大量的程式在等待 CPU 資源。
然後 CPU 情況,%Cpu(s): 3.4 us, 15.8 sy, 0.0 ni, 0.0 id, 80.8 wa, 0.0 hi, 0.0 si, 0.0 st,其中80.8 wa: 等待 I/O 操作完成的時間百分比。這是主要的負載來源,表示 CPU 大部分時間在等待磁碟或其他 I/O 操作完成。
然後能看到這程式使用了 VIRT 3.1 GB, RES 佔用了 160MB。%CPU 169.9: 該程式大約 1.7 個 CPU 核心。
RES 是我們這程式佔用的實際物理記憶體大小,佔用 160MB,因為我們有把文件內的資料讀取進去程式中。VIRT 來到了 3.1 GB,這是由於大量的 goroutine 分配或HTTP 請求的高併發處理,以及 Go 運行時記憶體管理所致。這些因素在大量併發的情況下累積,會導致 VIRT 看起來非常大,但實際上未必消耗了同樣多的物理記憶體。
這次 top 的輸出顯示了系統處於極高負載的狀態,主要表現在高 load average、高 wa 值和幾乎耗盡的記憶體。這些數據表明系統可能正在執行大量 I/O 密集型任務,導致 CPU 大部分時間在等待 I/O 完成,記憶體資源緊張,並且進程競爭 CPU 資源非常激烈。如果不加以優化,系統性能可能會進一步惡化,影響到正常運行。
VMSTAT
VMSTAT 是個工具能夠動態監看 OS 的 CPU、記憶體、I/O 等活動。我們能透過 TOP 看到資源的使用情況,但還是看不到有在發生 context switching。其中在 VMSTAT 提供了 system 中提供了 cs (context switches per second)。還有 CPU 的資訊像是 us(user time) 和 sy(system time)、id(idle)和 wa(waiting for IO)。
vmstat 5 表示我每5秒統計顯示一次數據,這裡面的 cs 是這5秒內,每秒平均發生 context switching的次數。可以看見我平時大概每秒3000次上下的context switching。大多數情況下 us 和 sy 僅有 1% 到 2% 的 CPU 使用,這表示系統在執行較少的計算任務。然後 CPU 大部分時間處於 Idle,顯示 95% 到 99% 的 idle 時間。這表示系統在當前負載下有足夠的資源。

接著來啟動 go cs程式。可以看見下圖,第 2 行開始有很顯著的不同了。Context switching 次數從數百次到數千次迅速增加到每秒幾千次甚至超過一萬次。,這正是由於我建立了大量 goroutine 並在單個 CPU 核心上運行所導致的結果。這樣的情況會顯著增加系統的調度負擔,導致更多的 context switching。我們能通過 VMSTAT 該工具觀察。

此外這裡還透漏很多資訊。b: 正在等待 I/O 操作完成的thread數量。這裡的數字非常高,大約在 1000,這與我們程式設定的 numWorkers 一致,這表示有大量的進程因為等待 I/O 操作(例如磁碟讀寫)而被阻塞。I/O 的 bo 寫入量很高,這是能理解的,畢竟我們真的有寫資料的動作。
重點在於 System 與 CPU 的部份。 in: 每秒進行的 interrupt 次數。in 值大幅增加,有時高達 11,827 次,表示系統正在處理大量的中斷。cs: 每秒上下文切換的次數。cs 值大幅增加,有時高達 17,219 次,表示大量的 context switching,系統負載非常高。us: User space 程式佔用的 CPU 百分比。通常在 0% 到 4% 之間,這表示 CPU 的計算資源大部分用於處理系統操作和 I/O,而不是應用程式邏輯。id: 空閒時間百分比。大部分時間 id 非常低,甚至達到 0%,這表明 CPU 幾乎沒有空閒時間,完全被利用。wa: I/O 等待時間百分比。wa 值非常高,達到 94% 甚至更高,這表明 CPU 大部分時間在等待 I/O 操作完成。這是 I/O 密集型負載的特徵。
這些統計資料表明系統處於非常高的負載狀態,特別是在 I/O 操作上,CPU 大部分時間都在等待磁碟 I/O 完成。相比於平常,系統的記憶體和 I/O 資源消耗非常嚴重,Context switching 次數大幅增加,CPU 幾乎無空閒時間。這樣的情況可能會導致系統性能下降或回應變慢,特別是在 I/O 密集型應用場景下。
PIDSTAT
剛剛 VMSTAT 能看到整體情況,但要是我們想往更細緻的方向去排查分析,通常就要依賴 pidstat 這工具了。 pidstat 主要用來監控和報告個別處理程式的各種性能指標,包括 CPU 使用率、記憶體使用率、I/O 操作、Context switching 等。
其中 -w 是用來顯示處理程式的Context switching次數,包括 cswch 自願 Context switching(由處理程自身引起)和 nvcswch 非自願Context switching(由操作系統引起)。
能看見下圖所示,PID 128422 (cs):此處的 cs 處理程式在報告時間內每秒發生了 4701.70 次 cswch,並且有 11.89 次 nvcswch/s。這表明該進程頻繁地進行了 I/O 操作或其他等待操作,導致了大量的 cswch。

那我們就能抓到是哪個程式沒設計好,導致 CPU 的資源忙於 Context switching上。
明天再來分享 go tool 怎發現這樣的情況。




