

DDD 紅皮書 - Ch4

訪問 CIO
了解系統架構演化的過程與面臨什麼事件因此需要演化。
主持人 Maria 與 SaaSOvation 的 CIO Mitchell 對談,回顧十年來他們如何在不同階段選用合適的架構、搭配 DDD 而穩健成長。
早期:原本規劃桌面部署+中央資料庫,採 分層架構(Layers),對單一應用層+DB 的情境合理。
轉向 SaaS:與夥伴合作、拿到資金,優先做協作工具,再回頭強化敏捷專案管理產品。
引入 DIP:為了可測試性,用 依賴反轉(DIP) 讓 UI、基礎設施(例如持久化)可替換;以 Aggregate/Repository 配合「記憶體實作 → 真正持久化」的替換策略。
上雲與行動化:行動需求、同盟登入、安全、BI 報表等湧現,採 REST;同時轉向 六邊形架構(Ports & Adapters),方便加新用戶端、持久化與訊息等 Adapter。
擴張與整併:大量新租戶、資料遷移需求,於服務邊界用 SOA(例如 Mule 的 Collection Aggregator)整合,同時仍維持六邊形核心。
UI 日益複雜:專案/缺陷看板需即時更新、且每租戶偏好不同;為降低指令與查詢世界的摩擦,引入 CQRS。
長流程需求:某些功能要跑一串分散流程,不能讓使用者等待;導入 事件驅動架構(EDA) 與 Pipes & Filters。
規模再起:被大型雲商收購後,用戶暴增,將 Pipes & Filters 分散化與平行化,並加入 Saga(長流程/補償)。
法規遵循:政府要求追蹤每次變更;採用 Event Sourcing 作為自然的領域機制以滿足合規。
總結:一路以 DDD 為核心,依需求與風險適時引入合適的架構影響,支撐快速成長與變更。
Service Oriented
服務導向架構(SOA)對不同的人有不同的意義,這使得相關的討論往往充滿挑戰。最好的方式是先找到一些共同基礎,或者至少定義出本次討論的範圍。依照 Thomas Erl 的定義,服務除了必須具備互通性外,還應符合 八項設計原則。
Service Contract(服務契約)
原則:服務要清楚表達自己的目的與能力,並以契約(通常是描述文件或 API 定義)來規範。
例子:
假設有一個「線上支付服務」,它的 API 契約會定義:
輸入:信用卡號、金額、貨幣
輸出:交易成功或失敗的訊息
限制:金額上限、支援幣別
這樣,任何人使用此服務前,都能明確知道怎麼使用,而不必了解服務的內部實作。
Service Loose Coupling(服務低耦合)
原則:服務之間應該盡量減少依賴,只需知道彼此的存在即可。
例子:「會員服務」不需要知道「購物車服務」的內部資料庫結構,它只需要透過 API 要到「會員資訊」。
如果日後「購物車服務」改用另一種資料庫,「會員服務」完全不用修改。
Service Abstraction(服務抽象化)
原則:服務只公開契約(API/RPC/Protocol),隱藏內部邏輯與技術細節。
例子:使用「天氣查詢服務」時,只要調用 API 就能得到今天的氣溫。
使用者不需要知道它是抓氣象局資料,還是透過 AI 預測,只要能拿到正確結果即可。
Service Reusability(服務可重用性)
原則:服務設計應能被多方使用,而不是只針對單一應用場景。
例子:「寄送 Email 的服務」可被:
訂單服務用來寄送「訂單確認信」
行銷服務用來寄送「廣告電子報」
系統通知用來寄送「忘記密碼信」
同一個服務被重複利用,減少開發與維護成本。
Service Autonomy(服務自主性)
原則:服務應能掌控自己的資源與運行環境,獨立可靠。
例子:「圖片上傳服務」自己有獨立的伺服器與儲存空間,無需依賴「會員服務」的資料庫。
即使會員系統故障,用戶仍能正常上傳圖片。
Service Statelessness(服務無狀態性)
原則:服務本身不應該保存狀態,狀態交由使用者或外部系統管理。
例子:「訂單查詢服務」每次請求時,必須附上「訂單 ID」,而不是依賴服務端記住用戶的上一次請求。
這樣可以讓服務更容易擴展(加機器分流),因為不用保存用戶的上下文。
Service Discoverability(服務可發現性)
原則:服務應有描述與標記(metadata),能讓其他人快速找到並理解它能做什麼。
例子:公司內部有「服務登錄中心(Service Registry)」,開發者能快速查到有哪些服務,例如:
「支付服務」:支援信用卡與電子錢包
「會員服務」:支援註冊、登入、會員升級
新團隊就能直接使用,不必自己重造輪子。
Service Composability(服務可組合性)
原則:服務應能像積木一樣被組合,形成更大型的服務。
例子:「旅遊預訂服務」可以組合以下子服務:
「航班查詢服務」
「飯店預訂服務」
「支付服務」
這樣能快速打造一個複雜的商業應用。
這八個原則的核心思想是:
清楚定義(契約、抽象化)
減少依賴(低耦合、無狀態、自主性)
最大化價值(可重用、可發現、可組合)
我們可以將這些原則與 六邊形架構(Hexagonal Architecture) 結合,將服務邊界放在最左側,而將 領域模型(Domain Model) 置於核心。圖 4.5 展示了這種基本架構:使用者可透過 REST、SOAP 或訊息傳遞(Messaging) 來存取服務。請注意,一個基於六邊形的系統可以同時支援多種技術服務端點,這也會影響 DDD 在 SOA 內的應用方式。
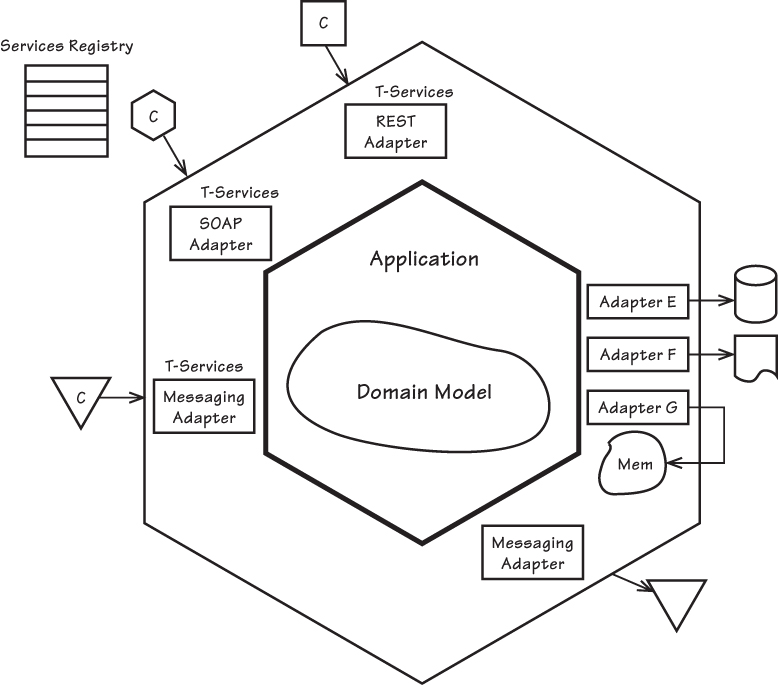
核心領域模型(Domain Model)
在圖中央,可以看到 Domain Model 與 Application。
這是系統的業務核心,所有規則與邏輯都在這裡,與外部技術無關。
👉 對應原則:Service Abstraction(服務抽象化)
技術服務端點(T-Services Adapters)
左側看到三種 技術服務適配器(Adapters):
REST Adapter
SOAP Adapter
Messaging Adapter
這代表一個應用可以同時支援多種協定或技術,服務使用者(Clients, C)可以自由選擇方式存取服務。
👉 對應原則:
Service Contract(服務契約):每個 Adapter 提供清晰 API 規格。
Service Loose Coupling(低耦合):REST 使用者不需要知道 SOAP 的存在。
服務登錄中心(Services Registry)
左上角的 Services Registry,用來存放服務的描述與資訊(metadata)。
使用者可以查詢有哪些服務可用,並了解它們的契約。
👉 對應原則:Service Discoverability(服務可發現性)- 讓服務成為「可尋找、可理解、可重用的資產」。
外部資源整合(右側 Adapters)
右側的 Adapter E, F, G,以及 Mem,表示服務可透過不同 Adapter 存取外部資源,例如:
資料庫
外部 API
記憶體快取
這些整合點不影響核心 Domain Model,因為它們被封裝在 Adapter 裡。
👉 對應原則:Service Autonomy(自主性):服務掌控自己的依賴資源。
Service Reusability(可重用性):不同服務可以共用相同 Adapter(例如資料庫連線)。
服務的組合(Composability)
圖裡的 REST / SOAP / Messaging 都是不同的「技術服務」,但它們都代表同一個「業務服務」。
在更大範圍內,這些服務可以進一步被組合,形成更高階的商業應用。
👉 對應原則:Service Composability(可組合性)
無狀態性(Statelessness)
REST、SOAP、Messaging 的請求都必須包含完整資訊,讓服務能獨立處理。
例如查詢訂單時,請求必須帶上「訂單 ID」,服務不會記住你上一次查了什麼。
👉 對應原則:Service Statelessness(無狀態性)
「電商平台」做一個端到端的實務案例
角色:會員、商品、訂單、支付、出貨、通知、服務註冊中心、快取/資料庫
一、場景敘述(從下單到到貨)
使用者在前台挑選商品 → 呼叫 商品服務 查價格與庫存(REST)。
按「下單」 → 訂單服務 建立訂單(REST),並發出
OrderCreated事件(Messaging)。支付服務 接到事件後執行扣款(可用 REST 或第三方 SOAP 介面),成功後發
PaymentCaptured。出貨服務 監聽到
PaymentCaptured→ 鎖定庫存、產生配送單 → 發ShipmentCreated。通知服務 監聽各事件,寄 Email/SMS(REST 介接寄信供應商)。
會員服務 可查到使用者的歷史訂單(REST),但不依賴訂單內部實作。
服務註冊中心 提供各服務契約與位址,方便新團隊接入(Discoverability)。
1) Service Contract(服務契約)
每個服務在註冊中心都有清楚的 API/事件契約。
- 訂單服務 REST 契約(摘要)
POST /orders建立訂單
Request
{ "customerId":"C-1024", "items":[{"sku":"SKU-9","qty":2}], "coupon":"SPRING20" }
Response
{ "orderId":"O-9001", "status":"PENDING_PAYMENT", "total": 1280 }
事件契約
Topic: commerce.ordersOrderCreated:
{ "orderId":"O-9001", "customerId":"C-1024", "total":1280, "occurredAt":"2025-09-30T10:02:11Z" }
2) Service Loose Coupling(低耦合)
訂單服務只知道「支付服務的契約」和「事件主題」,不知道支付內部是否接 Stripe、Line Pay 或銀行 SOAP。
出貨服務透過事件觸發,不直接呼叫訂單的資料庫或私有 API。
3) Service Abstraction(抽象化)
支付服務 封裝不同金流供應商(REST/SOAP),對外只暴露:
POST /payments/captureGET /payments/{id}
內部如何重試、如何對帳,對其他服務是不可見的。
4) Service Reusability(可重用性)
通知服務 被多方使用:下單成功寄信、付款成功簡訊、出貨提醒、重設密碼。
會員服務 的「會員等級查詢」同時被行銷服務(做分眾推播)與訂單服務(計算折扣)重用。
5) Service Autonomy(自主性)
每個服務持有自己的資料庫與快取:
訂單 DB 儲存訂單、明細;
支付 DB 儲存交易、對帳;
出貨 DB 儲存配送單與追蹤碼。
任一服務掛掉,不會把整個系統拖垮(例如通知延遲不影響下單流程;可用事件堆積 & 重試)。
6) Service Statelessness(無狀態性)
REST 請求必帶必要上下文(如
Authorization、orderId),服務不記用戶會話。橫向擴充時,請求可被任何一台實例處理;狀態放 DB/快取/Message 中間件,而非應用記憶體。
7) Service Discoverability(可發現性)
服務註冊中心/API 入口網站(Dev Portal)提供:
Swagger / OpenAPI、AsyncAPI(事件)
範例請求/回應、錯誤碼表、速率限制
版本/生命週期標示(如:
/v1穩定,/v2測試中)
新團隊(例如「發票服務」)能快速找到
PaymentCaptured事件並訂閱。
8) Service Composability(可組合性)
「結帳服務」其實是一個流程編排:
呼叫訂單服務建單
呼叫支付服務扣款
等待
PaymentCaptured事件呼叫/觸發出貨服務
呼叫通知服務送信
同一組服務也可被「市集平台」重用(只換前端 App 或 BFF),或被「門市 POS」以 Messaging 介接。
由於 SOA 的價值和定義眾說紛紜,你可能會不同意這裡的觀點。Martin Fowler 把這種情況稱為「[服務導向的模糊性(service-oriented ambiguity)](https://martinfowler.com/bliki/ServiceOrientedAmbiguity.html)」。因此,我不會嘗試去嚴格消除 SOA 的歧義,而是提供一個觀點,說明 DDD 如何與 SOA 宣言(SOA Manifesto) 的優先事項相契合。
雖然 SOA 宣言本身曾受到不少批評,但我們仍能從中獲得一些價值。Manifesto 的撰寫者之一 Stefan Tilkov 提出了務實的看法:
「[SOA 宣言] 讓我可以把服務視為一組 SOAP/WSDL 介面,或是一組 RESTful 資源。這並不是嚴格的定義,而是嘗試找出大家都能同意的價值與原則。」
Representational State Transfer—REST
REST 作為一種架構風格
架構風格(Architectural Style) 就像是架構領域的設計模式:它抽象出多種實作的共同點,讓人能比較不同架構的優劣。
Fielding 在論文裡,先介紹了分散式系統的幾種風格(例如 client-server、distributed objects),然後定義了每種風格的限制(constraints)。
REST 就是其中一種風格,專門描述 Web 架構應該遵守的原則。
REST 的關鍵概念
資源(Resource)
系統必須定義哪些東西要對外暴露(例如:客戶、產品、訂單、搜尋結果)。就像 Class 的 public & private
每個資源要有唯一 URI,可透過不同表現形式(JSON、XML、HTML)對外呈現。就像可以是 Public Function with Void、Public Function with arguments… Public Const Static function… ( URI == Function Name, 表現形式 == 方法簽章或返回的內容)
無狀態性(Stateless Communication)
每個 HTTP 請求必須自包含處理所需資訊(例如授權、請求參數)。
不依賴伺服器「記住」用戶的上下文(session)。
有助於擴展性(scalability)。
統一介面(Uniform Interface)
所有資源共用相同操作方法(HTTP verbs:GET、POST、PUT、DELETE)。
注意:這些方法 不是等同 CRUD,例如 POST 可以用來觸發動作。
安全性 safety 與冪等性 Idempotency
GET 是「安全操作」,只讀取資料,不應產生副作用,可快取。
PUT、DELETE、GET 是「冪等(idempotent)」:同樣的請求執行多次,結果相同。
HATEOAS(Hypermedia as the Engine of Application State)
回應中要包含可導航的連結,讓客戶端能透過資源之間的關聯找到操作路徑。
就像 Web 瀏覽器點擊超連結一樣,客戶端能自發探索。
例子:
初始入口:
GEThttps://api.shop.com/
回應:
{
"_links": {
"products": {"href": "/products"},
"orders": {"href": "/orders"},
"profile": {"href": "/users/me"}
}
}
客戶端只需要知道一個 Root URI,其餘由 _links 告訴它下一步可以去哪裡。
例子2: 如果訂單尚未付款:
{
"orderId": "O-1001",
"status": "PENDING_PAYMENT",
"_links": {
"pay": {"href": "/orders/O-1001/payment"}
}
}
如果訂單已出貨:
{
"orderId": "O-1001",
"status": "SHIPPED",
"_links": {
"track": {"href": "/shipments/S-2222"},
"invoice": {"href": "/orders/O-1001/invoice"}
}
}
➡️ 客戶端不需要硬編「如果狀態是 PENDING 就去 /payment」,而是依伺服器給的 _links 來行動。
REST 與 DDD 的關係
不要直接把領域模型(Domain Model)暴露為 REST API:
- 因為模型的改動會直接反映到 API,導致脆弱。
更佳的方式有兩種:
分離 Bounded Context:
系統的 API 介面層(用例導向)與核心領域模型分離。
API 的資源模型來自領域模型,但不等於領域模型。
使用標準媒體型別:
例如行事曆使用
ical,其模型跨系統共用。這相當於 DDD 的「共享核心(Shared Kernel)」或「發佈語言(Published Language)」。
為什麼選 REST?
鬆耦合(Loose Coupling):容易增加新資源,不會破壞現有客戶端。
可擴展性:利用 HTTP 快取、URI 重寫等既有機制。
可理解性:每個資源都是獨立的入口,容易測試與調試。
高成熟度的生態:HTTP 工具、伺服器、快取已經非常成熟。
CQRS
在複雜的領域模型中,當使用者介面需要顯示跨越多個聚合(Aggregate)型別與實例的資料時,單純透過 Repository 查詢往往很困難。隨著領域越複雜,這種情況越常發生。
如果僅靠 Repository,解法通常不理想:
客戶端可能需要呼叫多個 Repository,取出不同 Aggregate,然後自行組裝成 DTO。
或者我們可以在 Repository 中設計特製的 finder 方法,讓它能透過一個查詢找齊分散的資料。
如果這些方式都不合適,那麼可能會犧牲使用者體驗,把 UI 強行綁在聚合的邊界上,但長遠來看,這種僵化的介面設計並不理想。
有沒有一種完全不同的方式,能更好地把領域資料映射到 UI?答案就是 CQRS。它是將 Bertrand Meyer 的 命令-查詢分離原則(CQS) 推廣到架構層級的一種模式。
CQS 的原則是:
每個方法要麼是命令(修改狀態,不回傳值),要麼是查詢(回傳值,不改變狀態),不能兩者兼具。
例如:在 Java/C# 中,命令方法宣告為
void,查詢方法回傳值且不能引發任何狀態變化。
在典型的 DDD 模型(限界上下文)中,我們會看到:
聚合既有命令方法也有查詢方法。
Repository 除了
add()、save()之外,還有各種 finder 查詢。
CQRS 的做法:
把命令與查詢責任完全分開。
命令模型(Command Model):只保留命令方法與最基本的查詢(
fromId())。聚合不再有 getters,Repository 不再有複雜查詢。查詢模型(Query Model):專門用來優化查詢,直接面向使用者介面或報表需求。
因此,傳統單一的領域模型會被拆成兩部分:
命令模型(Write Model) 存在一個資料庫。
查詢模型(Read Model) 存在另一個資料庫。
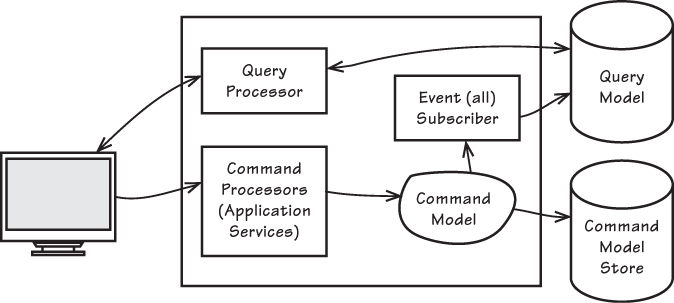
最終形成如圖所示的結構:
命令 Command 從客戶端傳到命令模型。
查詢 Query 直接針對查詢模型執行,通常經過最佳化,結果用於 UI 或報表。
有人可能覺得這樣很麻煩,增加了額外複雜度。
但要注意,CQRS 是針對特定情境的解法:當 UI 的查詢需求高度複雜時,CQRS 的價值才會凸顯。它並不是一種「潮流」或炫技,而是用來解決複雜查詢場景的架構模式。
另外,CQRS 裡:
Query Model 也稱為 Read Model。
Command Model 也稱為 Write Model。
Client 和 Query Processor
客戶端(圖的最左側)可能是網頁瀏覽器或桌面 UI。它透過伺服器上的 Query Processor(查詢處理器) 來存取資料。圖中沒有顯示伺服器層級的分層,因為 Query Processor 本身只是簡單元件,負責執行基本查詢,例如針對 SQL 資料庫。
這個元件不包含複雜邏輯:它執行查詢,必要時把結果序列化成可傳輸格式(例如 DTO、XML、JSON)。若是客戶端能直接讀取資料集(如 JDBC),甚至不需要序列化。不過,使用 Query Processor 來做連線池仍是較佳選擇,可以避免每個客戶端都需要昂貴的 DB 授權。
Query Model(或 Read Model)
查詢模型 是一種 非正規化(denormalized)資料模型。
它不是用來承載領域行為,而是 針對顯示與報表做最佳化。
在 SQL 中,一張表可以對應一個 UI 的畫面。
表可以有很多欄位,甚至超過單一畫面需要的資料,以便不同角色(一般用戶、管理員、主管)透過不同的 table view 存取到該角色能看到的資料。
這些視圖(views)可以很便宜、很快生成,也可以隨需求刪除重建。若結合 Event Sourcing,則可以重新播放歷史事件來生成新的查詢模型,甚至換一種完全不同的儲存技術。
例如: 普通用戶查詢 vw_usr_product 視圖,而管理員則查詢 vw_mgr_product,能看到更多資訊。
SELECT * FROM vw_usr_product WHERE id = ?
Client 驅動的 Command 提交
UI 客戶端會透過命令(Command)來執行系統行為。
Command 包含要執行的行為名稱與必要參數(相當於序列化的 method invocation)。
UI 設計上需幫助使用者輸入正確的資料,形成正確的命令封包。
這裡最適合「任務驅動(inductive)」的 UI 設計,讓使用者只看到能執行的動作,避免誤操作。
Command Processors(命令處理器)
命令由 Command Handler / Processor 接收並處理,常見有三種風格:
分類式(Categorized):一個 Application Service 處理一類命令,每個命令對應一個方法 → 簡單、易維護。
專用式(Dedicated):一個處理器只處理一個命令 → 單一職責、可獨立部署、易於水平擴展。
訊息式(Messaging):命令以異步訊息傳遞 → 支援更高擴展性與容錯,但設計更複雜。
處理步驟:
從 Repository 拿出 Aggregate
執行對應的命令方法(例如 commit backlog item to sprint)
更新完成後,發佈 Domain Event,供查詢模型更新
Command Model(或 Write Model)
命令模型的重點是執行業務行為,並在完成後 發佈領域事件(Domain Event)。
例如:
BacklogItem.commitTo(Sprint)→ 發佈BacklogItemCommitted事件。發佈機制基於 Observer 模式。
事件用於:
更新查詢模型
或(若採用事件溯源)用來重建 Aggregate 狀態
Event Subscriber 更新 Query Model
專門的 事件訂閱者(Event Subscriber) 會監聽命令模型發佈的所有事件,用來更新查詢模型。
每個事件需要包含足夠資訊,讓查詢模型能正確更新。
更新可以:
同步(synchronous):在同一交易中同時更新 Command Model 與 Query Model → 保證一致,但成本較高。
非同步(asynchronous):透過事件佇列稍後更新 → 可擴展,但會導致 最終一致性(eventual consistency)。
當新增新的 UI 視圖時:
如果使用事件溯源,可以重播舊事件來建構新表。
如果不是事件溯源,可以用 ETL 從 Command Model Store 匯出資料,轉換後載入 Query Model Store。
Eventually Consistent Query Model
如果查詢模型設計成 最終一致性(也就是在寫入命令模型後,查詢模型是非同步更新),那麼使用者介面就會遇到一些問題。
例如:使用者提交一個命令後,下個畫面是否會立即顯示更新後的資料?答案是不一定,可能取決於系統負載或其他因素。但我們最好假設最壞情況:UI 永遠不會即時一致,然後基於這個前提來設計。
UI 設計技巧
一個方法是:UI 暫時顯示剛剛提交的命令參數,也就是直接呈現使用者剛輸入的資料。雖然這有點「取巧」,但它能保證使用者看到的是「將來最終會一致」的結果,而不是完全過時的查詢數據。
但如果這方法不實用,或在多人同時操作時,其他使用者仍然會看到過期的舊資料( 例如排行榜、股票的 orderbook …),該怎麼辦?
技術解法與折衷
顯示資料時間戳:
每筆 Query Model 的資料都保留最後更新時間,UI 明確顯示「資料最後更新於 XX:XX:XX」。優點:使用者知道資料新鮮度,可以自行判斷是否要刷新。
缺點:有些人覺得這是有效模式,有些人覺得這只是「補丁」。最好先做使用者測試。
其他方式:
Comet / Ajax Push(伺服器主動推送更新)
Observer 或事件訂閱(例如分散式快取、事件網格 GemFire/Coherence)
UI 提示延遲(告訴使用者「請求已接受,處理需要一些時間」)
謹慎使用 CQRS
和所有模式一樣,CQRS 帶來多種權衡。
如果 UI 不複雜,也不需要跨多個 Aggregate 查詢,那麼引入 CQRS 可能只是 額外的偶發性複雜度(Accidental Complexity)。
只有在複雜度或風險足以導致失敗時,CQRS 才是必要的解法。
🔑 CQRS 的核心流程
查詢(Query)
- Client → Query Processor → Query Model Store(快、專為 UI 最佳化)
命令(Command)
- Client → Command Processor → Command Model(聚合更新) → 發佈事件
事件(Event)
- Event Subscriber 接收事件 → 更新 Query Model(同步或非同步)
⚖️ CQRS 的取捨
優點:
查詢快、靈活(Read Model 為 UI 量身打造)。
寫模型保持乾淨(聚合只專注於業務邏輯)。
可彈性支援多角色、多視圖需求。
缺點:
增加複雜度(兩份模型、兩份資料存儲)。
可能會遇到 最終一致性 問題。
經驗法則:何時用/不用
適合:
一個畫面要整合多聚合、跨服務資料,且查詢複雜、量大、低延遲要求。
有多樣化報表/搜尋/排序/分析需求,讀寫負載比極端(讀多寫少或反之)。
不適合:系統小、用例單純;單一聚合就能滿足查詢;團隊維運成本有限。
Event-Driven Architecture
事件驅動架構(Event-Driven Architecture, EDA)是一種促進事件的產生、偵測、消費與反應的軟體架構。
事件來源:可以是業務動作(例如「訂單已建立」)、系統監控(CPU 高負載)、基礎設施通知(節點擴容)等。
核心價值:鬆耦合(Decoupling)。發布者不需要知道誰會接收,訂閱者只要對事件類型有興趣就能消費。
DA 的價值是它解耦了各系統之間的依賴,只保留了 訊息傳遞機制本身以及它們訂閱的事件類型。
下圖可以看到三角形的 client 與對應的三角形輸出機制,代表了 Bounded Context 使用的事件機制。
輸入事件(Incoming Events)會從一個專門的 Port 進來,這個 Port 與其他三個 client 使用的 Port 是不同的。
輸出事件(Outgoing Events)同樣透過另一個不同的 Port 傳出。
這些獨立的 Port 可以代表不同的事件傳遞方式,例如 AMQP(RabbitMQ),而不是一般更常見的 HTTP。無論實際採用何種事件傳遞機制,我們可以假設事件的進入與輸出皆是透過這些符號化的三角形來完成。
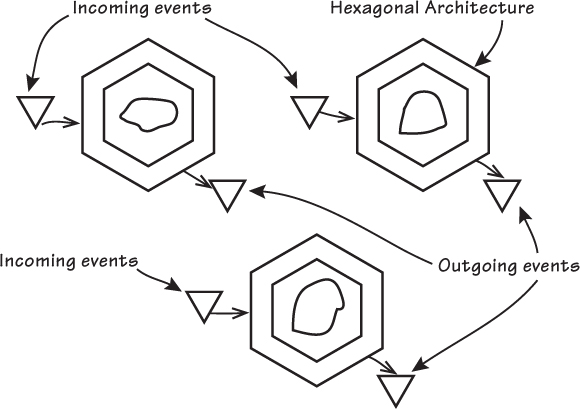
一個六邊形中可能有多種類型的事件進出,但我們特別關注的是 領域事件(Domain Events)。
應用程式也可能訂閱系統事件、企業事件或其他型別的事件,例如:
系統健康監控
記錄(logging)
動態資源配置(provisioning)
但真正需要我們建模關注的,仍是領域事件,因為它們承載了業務語境中發生的「重要事情」。
Domain Events 的傳遞與意義
某個系統透過輸出 Port 發佈的 領域事件,會被其他系統的輸入 Port 接收。
不同 Bounded Context 接收到的事件,其意義可能不同,甚至完全無意義。
若某事件類型對特定 Context 有興趣,它的屬性會被轉換並適配到該應用程式的 API,進而觸發某個操作。
這個被執行的操作會再反映到領域模型,並依循其協議(protocol)進行。
(註:若使用訊息過濾器或 routing key,訂閱者可以避免接收到對自己沒有意義的事件。)
多步驟流程與挑戰
有時候,一個接收到的領域事件只是 多任務流程(multitask process) 的一部分。
在所有預期的事件到齊之前,這個流程並不算完成。
那麼問題是:
流程如何開始?
它如何分散在整個企業中?
我們又該如何追蹤進度直到流程完成?
管線與過濾器(Pipes and Filters)
最簡單的 Pipes and Filters 形式之一,就是在 shell/console 命令列使用:
$ cat phone_numbers.txt | grep 303 | wc -l
3
用 Linux bash,來找出在 phone_numbers.txt 這個個人資訊管理檔案中,有多少聯絡人是科羅拉多州的電話號碼(區碼 303)。
雖然這不是一個很可靠的方式來實作此需求,但它確實示範了 Pipes and Filters 的運作方式:
cat:將
phone_numbers.txt的內容輸出到標準輸出(stdout)。通常這會連到 console,但當使用|時,輸出會被導向到下一個程式的輸入。grep:從標準輸入讀取(也就是 cat 的輸出),參數指定要比對包含字串
303的行。每個符合的行會輸出到自己的 stdout,接著再被 pipe 到下一個程式。wc:從 stdin 讀取(也就是 grep 的輸出)。
-l參數告訴 wc 要數輸入的行數。最後結果是3,因為 grep 輸出了三行。由於沒有再 pipe,這次的 stdout 會顯示到 console。
基本概念
在這個例子中:
每個工具(cat、grep、wc)都 接收資料集 → 處理 → 輸出新的資料集。
每個工具的輸出和輸入都不同,因為它們扮演了 Filter 的角色。
最終輸出已經完全不同:從原始的聯絡人檔案,變成了一個數字
3。
這就是 Pipes and Filters 的核心原理。
Pipes and Filters 的基本特性
| 特性 | 說明 |
| Pipes 是訊息通道 | Filter(過濾器/處理器)會在輸入管道接收訊息,並將訊息送往輸出管道。Pipe 實際上就是一個訊息通道。 |
| Ports 連接 Filters 與 Pipes | Filters 透過 Port 連接到輸入與輸出管道。這使得六邊形架構(Ports and Adapters)成為一個合適的總體風格。 |
| Filters 是處理器 | Filter 可能只處理訊息而不一定真的做「過濾」。 |
| 獨立處理器 | 每個 Filter 處理器是一個獨立元件,適當的元件粒度需透過良好的設計來達成。 |
| 鬆耦合 | 每個 Filter 處理器獨立組合在整體流程中,不依賴其他處理器。Filter 的組成方式可以透過設定定義。 |
| 可替換性 | 處理器接收訊息的順序可以根據需求重新安排,通常透過設定組合來完成。 |
| Filters 可以多管道處理 | 不像命令列 Filter 僅能讀/寫單一管道,訊息 Filter 可以讀取或寫入多個管道,這意味著可以進行平行或並行處理。 |
| 同類型 Filters 可平行使用 | 最忙碌、可能最慢的 Filter,可以以多個實例平行部署來增加處理量。 |
將這種 Pipeline 原理套用到 事件驅動架構的設計上。
假設我們把 cat、grep、wc 想像成 EDA 元件:
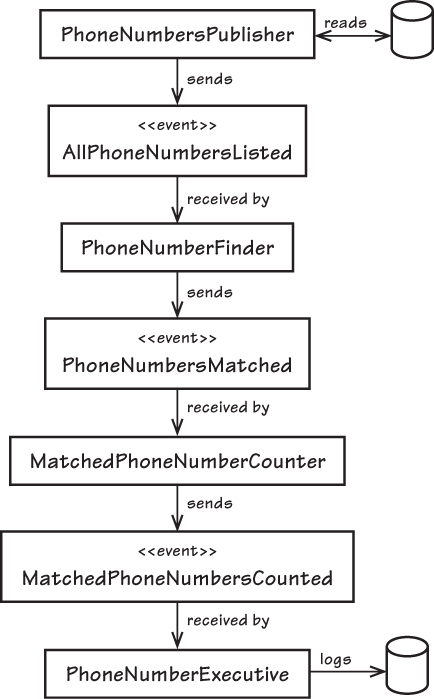
PhoneNumbersPublisher
從
phone_numbers.txt讀取所有行發佈事件
AllPhoneNumbersListed(包含所有資料)管線開始
PhoneNumberFinder(第一個 Filter)
訂閱
AllPhoneNumbersListed,接收事件搜尋含有「303」的行
發佈事件
PhoneNumbersMatched,內容包含比對到的完整行
MatchedPhoneNumberCounter(第二個 Filter)
訂閱
PhoneNumbersMatched,接收事件計算電話號碼數量(例:3 筆)
發佈事件
MatchedPhoneNumbersCounted,屬性 count=3
PhoneNumberExecutive(終端處理器)
訂閱
MatchedPhoneNumbersCounted,接收事件負責紀錄 log,例如:
3 phone numbers matched on July 15, 2012 at 11:15 PM
彈性與限制
這種管線是 相對靈活的:
如果要加新的 Filter,只需建立新的事件並調整訂閱關係。
必須設定小心地改變管線的順序。
但不像命令列一樣簡單,通常事件管線不會頻繁修改。
在真正的企業系統中,我們會用這種模式把大問題分解成更小的步驟,使 分散式處理 更容易理解與管理。同時,它還允許多個系統各自專注於自己最擅長的事情。
在實際的 DDD(領域驅動設計)情境下,領域事件(Domain Events) 的命名都反映了對業務有意義的內容。
在真正的企業系統中,我們會用這種模式把大問題分解成更小的步驟,使 分散式處理 更容易理解與管理。同時,它還允許多個系統各自專注於自己最擅長的事情。
在實際的 DDD(領域驅動設計)情境下,領域事件(Domain Events) 的命名都反映了對業務有意義的內容。
步驟 1 可以發布一個領域事件,這個事件來自某個 Bounded Context 中某個 聚合(Aggregate) 的行為結果。
後續步驟可能會發生在一個或多個不同的 Bounded Context 中,它們接收初始事件並發布後續的事件。這三個步驟可能會在各自的上下文中建立或修改新的 Aggregate。
具體要怎麼做要依賴領域本身,但這些就是在 Pipes and Filters 架構 下處理領域事件時的常見結果。
這些事件並不是單薄的技術性通知。它們明確地建模了「業務流程中的活動發生」,對整個領域的訂閱者來說是有用的訊號。而且它們會包含唯一識別資訊,以及足夠的屬性來完整傳達其意義。
然而,這種「同步、逐步」的風格也能被擴展,使其同時完成不只一件事情。
Bonus Section
與 CQRS 常搭配的模式
Event Sourcing(事件溯源):寫模型以事件做唯一真相(source of truth),讀模型由事件「投影(projection)」生成。優點是重建/回補方便;缺點是事件演進與版本化要做得很嚴謹。
寫模型不存「當前狀態 Gauge」作為權威,而是把每次變更記成不可變的事件,追加到針對某個 Aggregate 的事件串(stream)中。
狀態=事件重播的結果:
需要當前狀態時,將該 Aggregate 的事件依序重播(rehydration)即可。讀模型(Read Model/Projection)=事件的投影:
將事件「投影」成為查詢友善的資料(表格、索引、快取),服務 UI/報表;這些讀模型通常是最終一致。以加密貨幣交易機制為例.
Outbox / CDC(變更資料擷取):避免「雙寫」不一致。寫模型在同一交易把「事件」寫進 outbox table,再由背景程序或 CDC 可靠地發佈到訊息匯流排。
- 細說 Outbox Pattern 的實作方式
Saga / Process Manager:跨聚合、跨服務的長事務流程與補償(取消、退款等)由流程管理器負責協調。
Materialized Views(實體化檢視):讀模型可以是彙總/聚合後的快取表或搜尋索引(如 Elastic、Redis、Cassandra)。
一致性與體驗策略(Read-Your-Writes)
Session Cache:命令成功後,先用本地/前端快取回填剛提交的值,直到讀模型同步完成。
Sticky Reads:短時間內把該使用者的查詢導向同一資料分片/同一區域Main資料庫,以提高「讀到自己剛寫的」機率。
延遲回應 / 非同步完成:命令回傳 202(接受),前端顯示「處理中」,待讀模型更新以推播/輪詢呈現結果。
一致性開關:在少數 必需強一致 的用例(如付款確認頁),可臨時改走 同步投影 或直接讀寫模型(慎用)。
併發與遞送保證
樂觀鎖(Optimistic Concurrency):Aggregate 帶 version;命令以期望版本寫入,衝突則重試或回報。
- 可減少資料鎖定時間,但會有大量衝突retry在消耗連線處理的情況
冪等性(Idempotency):命令與事件要能以 Idempotency Key 去重;訂閱者也要能「至多一次 / 至少一次」都安全。
事件順序:對「同一 AggregateId」要保序(partition by AggregateId);跨 Aggregate 則設計上避免強相依序。
一樣已加密貨幣交易為例
讀模型投影實務
投影器(Projector)設計:
小而專一,一個投影器負責一種 view/table。
能「重播」與「快轉到最新(catch-up)」。
失敗要可重試、可跳過(含死信佇列)。
重建策略:
有事件倉:全量重播或以時間窗增量重播。
無事件倉:用 ETL 從寫庫批次回填(初始化階段);之後靠事件持續更新(差異變更)。
讀庫選型:依需求挑選(查全文、排序/分頁、地理查詢、分析聚合);多種RO資料庫並存很常見。
安全與授權(Read Side)
投影即分權:把 租戶 / 角色 / 權限 直接烙印在讀模型裡(欄位或分表),查詢過濾更快、更簡單。
資料最小化:GDPR/刪除請求要能在各讀模型一併抹除(保持索引同步刪除的機制)。
維運與可觀測性
落後量(Lag)度量:以「事件序號或時間戳」監控每個讀模型的滯後;超閾值告警。
對帳檢核:定時抽樣比對讀/寫模型一致性,發現偏差就重播修復。
灰度發佈:新增讀模型時先影子寫入(dual-projection),穩定後切流量。




