

了解 Go Map

GO map shrink 最近同事給了我這篇文章, 文章想證明 Go 的 map 哪怕改成 swisstable 版本, 在元素都刪除後且 GC 發生後, map 的大小依然不那麼小, 好像不會 shrink. 但這問題的根本我們得先了解 map 的組成.
1.23 版本的 Map
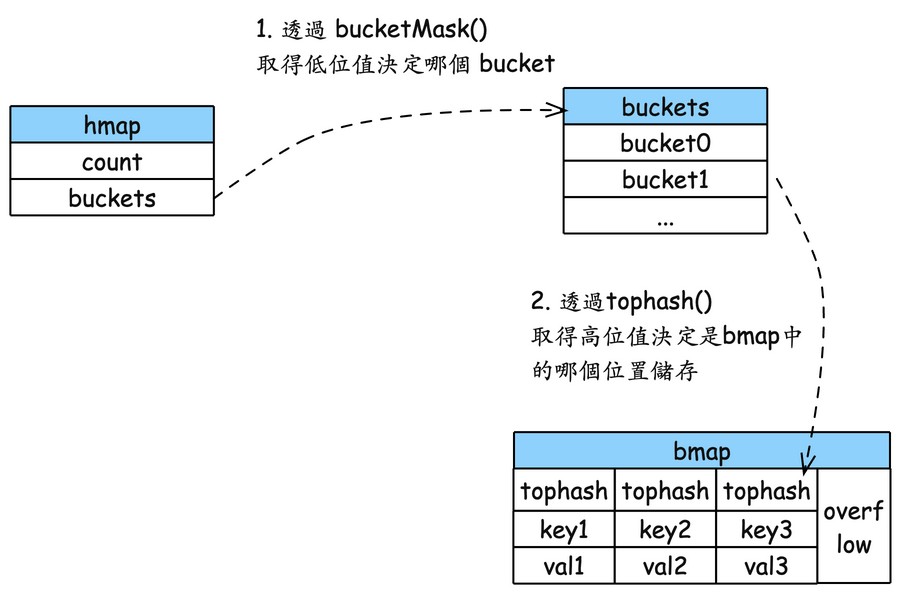
Source Code Go 的 map 實際上是基於 hash table 的資料結構。資料存儲在一個 bucket 的array 中,每個 bucket(Go的map中叫 bmap) 可以存放 8 個key value pair 。 選擇bucket的方式是透過 hash value 的低位值來選擇對應的bucket。如果要存入新的元素時, 所處的 bucket 元素個數已經 8 個了, 則會進行 overflow 的處理, 會使用額外的 bucket 來存儲這些額外的key value。新的overflow bucket 會被鏈接到本來的 bucket,形成一個linked list結構。當然 overflow bucket 只去臨時性的應對方案, 當 overflow bucket 太多時會進行 groupup 擴容.
而當 hash table 的大小達到一定的負載因子(load factor) 時,會將 bucket 的數量成倍增加,通常是將 bucket array 的大小擴展為原來的兩倍。在擴展過程中,舊的 bucket array 中的 bucket 會被逐步複製到新的、更大的 bucket array中(hashGrow+growWork+evacuate )。
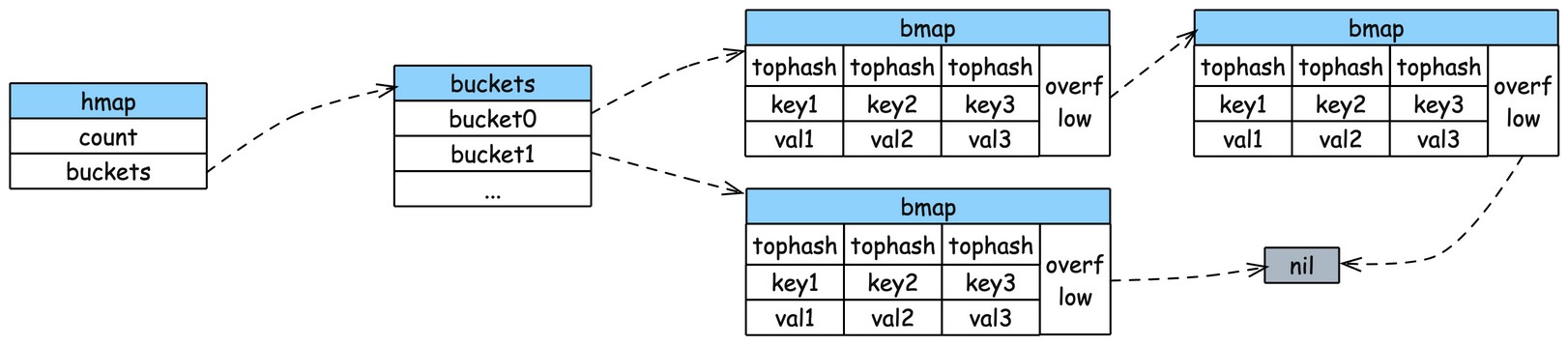
// map 的主要結構,包含了關於整個 map 的 metadata
type hmap struct {
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// 用於儲存與 map 相關的額外資訊,特別是與 overflow bucket 管理相關的內容。
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
// 每個 bucket 的結構,實際儲存 key-value pair 的數據
// 但因為元素的key與value 的類型其實是動態執行時期才會得知的, 所以編譯時期如下
type bmap struct {
tophash [abi.MapBucketCount]uint8
}
// 當宣告好 map 的類型時, 就會產生如下的結構
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
Tophash
bmap 中的 tophash設計很有意思, 因為這樣的設計一定會有不同的 key, 經過hash後的低位值, 選擇在同一個bucket中儲存, 但為了能快速找到空位, 如果一個一個位置慢慢走訪這樣在新增與查詢的場景效率會很差.
所以設計了 tophash 來快速的定位是放在bucket 的哪個位置, 但還是有可能該位置有人, 所以設計了以下的值用來快速代表一些語意, 不同的 tophash 值代表了不同的含義,讓我們一起來看看:
其中evacuatedX, evacuatedY和evacuatedEmpty都與migration有關.
emptyRest = 0 // 整個都空的, bucket是初始的狀態, i.e. 沒overflow。
emptyOne = 1 // 這個 cell 是空的。後面不知道.
evacuatedX = 2 // key/elem 是有效的。這個 entry 已經遷移到了新的 hashtable 的前半部分。
evacuatedY = 3 // key/elem 是有效的。這個 entry 已經遷移到了新的 hashtable 的後半部分。
evacuatedEmpty = 4 // 這個 cell 是空的,但是 bucket 已經被 migrated了。
minTopHash = 5 // 這是一個正常填充 cell 的最小 tophash 值。
// tophash calculates the tophash value for hash.
func tophash(hash uintptr) uint8 {
// 從輸入的哈希值 hash 中取出高位 8 位,作為 top 變數的初始值。
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
// 如果 top 的值小於 minTopHash 常數
// ,則將 top 加上 minTopHash 的值。這是為了確保 tophash 值不會太小。
top += minTopHash
}
return top
}
tophash 函數的目的是為了在 map 的查找過程中提高效率。在 mapaccess1 函數中,我們看到會先比較 tophash 值,如果不匹配就可以快速跳過當前 bucket。這樣可以減少不必要的遍歷,提高查找速度。
負載因子 Load factor
在 Go 語言的哈希表設計中,負載因子(load factor)是一個關鍵參數,它影響 hash table 的性能和記憶體的使用。以下是對於負載因子及其影響的詳細說明:
負載因子的選擇:
適當的負載因子可以平衡 hashtable 的性能和記憶體使用。
如果負載因子設置得太大,會導致許多 overflow buckets,增加查找和插入操作的開銷。
如果設置得太小,則會浪費記憶體空間,因為會有很多空桶。
統計數據解釋:
以下是 Go 團隊對不同負載因子的統計數據的解釋:
| 負載因子 | 溢出桶百分比 (%). 表示有多少百分比的桶擁有溢出桶。這是一個指標,顯示hashtable的擁擠程度。 | bytes/entry 這個數字越小,表示記憶體使用越高效。 | 命中探查次數 查找已存在key時需要檢查的資料數量。這個數字越小,表示查找效率越高。 | 命中探查次數 |
| 4.00 | 2.13 | 20.77 | 3.00 | 4.00 |
| 4.50 | 4.05 | 17.30 | 3.25 | 4.50 |
| 5.00 | 6.85 | 14.77 | 3.50 | 5.00 |
| 5.50 | 10.55 | 12.94 | 3.75 | 5.50 |
| 6.00 | 15.27 | 11.67 | 4.00 | 6.00 |
| 6.50 | 20.90 | 10.79 | 4.25 | 6.50 |
| 7.00 | 27.14 | 10.15 | 4.50 | 7.00 |
| 7.50 | 34.03 | 9.73 | 4.75 | 7.50 |
| 8.00 | 41.10 | 9.40 | 5.00 | 8.00 |
因此選擇適當的負載因子對於確保 Go hashtable的性能至關重要。透過上述統計數據,可以更好地理解如何選擇負載因子,以達到最佳的性能和記憶體使用效果。
透過 load factor 計算 hashtable 是不是用於擁擠而過載的公式如下.
const (
loadFactorDen = 2
loadFactorNum = loadFactorDen * abi.MapBucketCount * 13 / 16
)
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > abi.MapBucketCount && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
但我看不懂, 白話點就是,
$$Load Factor = \frac{Number of Elements}{Number of bucket}$$
網路很多文章說算出來超過 6.5 就會擴容, 6.5 還是寫死的, 這我就不懂了.
Aleksandr Kochetkov : some-insights-on-maps-in-golang
Group up 擴容與遷移Migration
當 load factor 過載時, 就會觸發 map 的擴容以及對應的migration機制.
首先觸發的是`growWork` 負責在成長過程中進行桶的清理和合併。它會檢查當前桶是否需要進行清理,並將舊桶的內容移動到新的桶中。
在搬遷到新bucket的過程中, evacuate負責將舊桶中的元素移動到新的桶中,確保元素按照 hash value 正確分配到新的位置, 這步驟就是在做 Rehash.
這個過程其實成本很高的, 像是在 evacuate 就需要把所有元素都走訪一次並且 rehash, 需要大量 CPU 資源. 然後同時又會需要兩份的bucket空間, 這當下會需要不少記憶體.
migration過程中, hmap結構中的oldbuckets 此時就會把原本的bucket做個備份在此. 也能看到有個判斷是不是正在遷移中的函數, 就是直接判斷 oldbuckets 是否為空.
// growing reports whether h is growing. The growth may be to the same size or bigger.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
結論
我講一堆還是沒講到為什麼 map 儲存的元素明明都刪除了(不管value是實值類型還是指標), 手動呼叫 GC 了, 但記憶體配置的大小還不如預想中的小. 是因為 hmap 的各種bucket, 並不會被 GC 回收 XD, 要等到該map變數被重新allocate或沒變數在參考到該map時才會真的被回收乾淨.
因為上面我們隱約能發現, 擴容跟migration其實很耗資源成本, 好不容易已經被擴容完成的map, 就不會刻意在減少bucket 的大小了.
但也因此如果我們能很精準地宣告出map的元素個數的話, 那其實這一切的擴容行為都能避免. 如下:
m := make(map[string]int32, 10000)
不過1.24 應該會改用 Swiss table, 但hmap的本質是不變的, 很多概念應該還是會沿用.
能參考資料[Go map使用Swiss Table重新实现,性能最高提升近50%](https://tonybai.com/2024/11/14/go-map-use-swiss-table/)




