

OTel 一些概念筆記

因為最近在準備 OpenTelemetry 第一張證照 OTCA,把一些不太熟的筆記紀錄在此,最近會持續補完。
OTel Metrics Data Model
OTel 網站 Metrics Data Model 章節連結
Log 跟 Trace 其實都好理解,Metrics 水超深。模擬考我這塊錯的比例相對高,趁這次把之前不懂的部份給補齊。
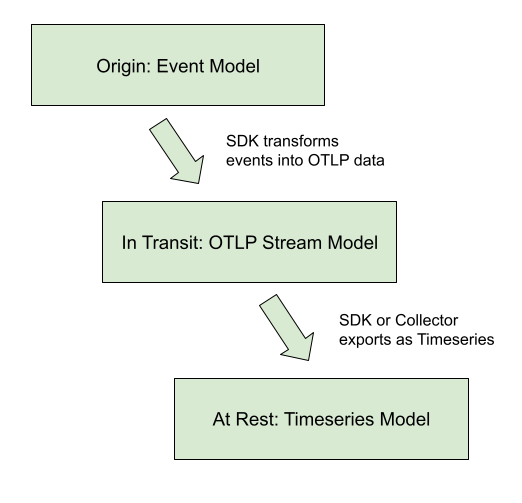
Metrics SDK 會把 instrument 到的事件(event)先以原始事件形式紀錄在記憶體中,再轉成 OTLP stream model,此模型是用來儲存和分析的一種 stream model(包含多個 data point),要匯出時如果是直接匯出到遙測後端,exporter會直接轉成 timeseries model。而如果傳遞給 collector,則是以OTLP stream model形式傳遞給 collector,再由 collector轉成 timeseries model 給遙測後端。
OTLP stream Model
Cumulative and Delta
https://sodkiewiczm.medium.com/opentelemetry-parameter-that-might-ruin-your-flexibility-edf3aa0d290a
https://opentelemetry.io/docs/specs/otel/metrics/supplementary-guidelines/
https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/cumulativetodeltaprocessor/README.md
https://grafana.com/blog/2023/09/26/opentelemetry-metrics-a-guide-to-delta-vs.-cumulative-temporality-trade-offs/
https://opentelemetry.io/docs/specs/otel/metrics/sdk_exporters/otlp/
Temporality
在 OpenTelemetry 中,「Temporality(時間性)」是一個關鍵概念,用來描述指標數據(Metrics)如何隨時間累積或更新。具體來說,Temporality 指的是加法性量(additive quantities)與時間的關係,即報告的值是否包含之前的測量結果。這對於正確理解和處理指標數據非常重要,特別是在進行聚合、轉換或分析時。以下將詳細說明 Temporality 的相關概念、類型及其應用。
一、Temporality 的基本概念
Temporality 描述的是指標數據如何隨時間變化,具體體現在數據點的累積方式上。每個 OTLP(OpenTelemetry Protocol)指標數據點都包含兩個時間戳:
TimeUnixNano(檢測時間戳):這是必填的時間戳,表示該指標數據點的觀察時間,即測量結果變為當前有效的瞬間。 StartTimeUnixNano(起始時間戳):這是可選的時間戳,用來表示一系列數據點的開始時間,確保數據流的連續性,並能正確處理系統重啟或數據流中斷的情況。 這兩個時間戳的結合使得 OpenTelemetry 能夠精確地解釋和處理指標數據,特別是在進行 rate 計算或聚合操作時。
二、Temporality 的類型
OpenTelemetry 支持兩種主要的 Temporality 類型:
- 累積 Temporality(Cumulative Temporality) 定義: 累積 Temporality 表示後續的數據點會重複使用相同的起始時間戳(StartTimeUnixNano)。 例如,從起始時間 T0 開始,累積數據點覆蓋的時間範圍為 (T0, T1]、(T0, T2]、(T0, T3],依此類推。
特性: 持續累加:每個新的數據點都是從初始時間開始累計的總和。 示例系統:Prometheus 是使用累積 Temporality 的典型代表。
優點: 簡化了系統的可靠性設計,因為累積數據點能自然地處理間歇性收集失敗的情況,通過累積測量自動平均缺失的數據。
缺點: 發送端需要記住所有之前的測量結果,這會帶來與 Cardinality 成正比的記憶體成本。
應用場景: 適用於需要持續追踪累計值的場景,例如總請求數、總錯誤數等。
- 增量 Temporality(Delta Temporality) 定義: 增量 Temporality 表示後續的數據點會更新起始時間戳,使其不斷前進。 例如,從起始時間 T0 開始,增量數據點覆蓋的時間範圍為 (T0, T1]、(T1, T2]、(T2, T3],依此類推。
特性: 分段累加:每個數據點僅表示自上一次數據點以來的增量。 示例系統:Statsd 是使用增量 Temporality 的典型代表。
優點: 減少了發送端的記憶體成本,因為不需要保存所有歷史數據,只需記錄上一次的增量。 支持抽樣(sampling),將 Cardinality 的成本轉移到下游系統。
缺點: 需要下游系統來處理增量數據點的累積,這增加了下游系統的負擔。
應用場景: 適用於高 Cardinality 的場景或資源受限的發送端,例如大量短生命週期的計數器。
三、Temporality 的轉換
OpenTelemetry 支持在不同的階段(如 SDK 或 Collector)進行 Temporality 的轉換。例如:
從增量轉換為累積:在發送端使用增量 Temporality,然後在 Collector 中將增量數據點累加成累積數據點,以便下游系統(如 Prometheus)能夠正確處理。
從累積轉換為增量:在發送端使用累積 Temporality,然後在 Collector 中轉換為增量數據點,以便下游系統(如 Statsd)能夠有效處理。
這種靈活性使得 OpenTelemetry 能夠適應不同的系統需求和資源限制,並在不同的部署環境中提供最佳的性能和可靠性。
四、Temporality 的應用案例
- 使用 Prometheus 的累積 Temporality Prometheus 使用累積 Temporality 來處理指標數據。例如,監控一個 Web 服務的總請求數:
每次請求到達時,計數器會累加。 Prometheus 定期拉取這些累積的計數器數據。 通過相減相鄰的累積值,Prometheus 計算出每個拉取間隔內的請求數,進而計算出請求速率。 這種方法簡單且高效,特別適合需要高可靠性的監控場景。
- 使用 Statsd 的增量 Temporality Statsd 使用增量 Temporality 來處理指標數據。例如,追踪一個應用程序中每秒的錯誤數:
每次錯誤發生時,錯誤計數器會增加 1。 Statsd 客戶端會定期將這些增量值發送到後端。 後端系統(如 Graphite)根據這些增量值來計算錯誤速率。 這種方法減少了發送端的記憶體使用,適合處理高頻率或高 Cardinality 的度量數據。
- Temporality 轉換的實際應用 在一些複雜的監控系統中,可能需要同時支持累積和增量 Temporality。例如:
發送端使用增量 Temporality 以減少記憶體消耗。 Collector 端將增量數據轉換為累積數據,便於下游系統(如 Prometheus)處理。 這樣既能保持發送端的輕量化,又能滿足下游系統的需求。
五、Temporality 的選擇考量
在選擇使用累積 Temporality 還是增量 Temporality 時,需要考慮以下幾個因素:
系統資源: 累積 Temporality:需要發送端保存所有歷史數據,適合資源充足的系統。 增量 Temporality:不需要保存歷史數據,適合資源受限或高 Cardinality 的系統。
可靠性要求: 累積 Temporality:在數據收集中斷時,能夠自動平均缺失的數據,適合需要高可靠性的場景。 增量 Temporality:需要下游系統來處理數據的連續性,對於數據中斷的處理需要更複雜的邏輯。
下游系統的需求: 累積 Temporality:適合需要累積數據的監控系統,如 Prometheus。 增量 Temporality:適合需要增量數據的監控系統,如 Statsd。
數據處理的複雜度: 累積 Temporality:簡化了下游系統的數據處理,但增加了發送端的負擔。 增量 Temporality:降低了發送端的負擔,但增加了下游系統的處理複雜度。
| 特性 | Cumulative Temporality(累積時間性) | Delta Temporality(增量時間性) |
| 累加方式 | 從固定的起始時間累積到當前時間 | 每個數據點代表自上一報告周期以來的增量 |
| Data point 重複使用 | 起始時間戳相同,Data point包含累計值 | 起始時間戳隨著每個Data point前進 |
| 適用場景 | 需要持續追蹤總量的場景,如總請求數 | 高頻率或高基數的場景,如每秒錯誤數 |
| 記憶體成本 | 高,需保存所有累計值 | 低,只需保存上一個增量值 |
| 下游處理負擔 | 較低,因為數據點已經是累計值 | 較高,需在下游系統累加增量值 |
累積 Temporality 與 Cardinality 的關係
Cardinality(基數) 指的是度量數據中不同維度組合的數量。舉例來說,如果你有一個度量指標,並且它有兩個屬性:region 和 service,那麼不同的 region 和 service 組合會增加 Cardinality。
需要保存初始值和所有累計值 由於每個數據點都需要以 T0 為起始時間進行累加,發送端必須:
記住起始時間 T0:確保所有數據點的起始時間一致。 保持當前累計值:隨著時間推移,持續更新並保存累計值。
高 Cardinality 的影響 每個維度組合需要單獨保存累計值:例如,假設有 100 個不同的 region 和 50 個不同的 service,那麼總共有 100 × 50 = 5000 個不同的維度組合。對於每一個組合,發送端都需要保存其獨立的累計值。
記憶體需求線性增長:隨著 Cardinality 增加,每個新的維度組合都需要額外的記憶體來存儲其累計值。這意味著系統的記憶體需求會隨著 Cardinality 的增加而線性增長。
例子一:StatsD 使用 'delta' Temporality
StatsD 是一個廣泛使用的度量收集系統,默認使用 'delta' Temporality 來處理計數器數據。例如,追蹤每秒的錯誤數:
錯誤發生時:每發生一次錯誤,計數器增加 1。
定期報告:每秒鐘,StatsD 客戶端會報告自上次報告以來的增量值。
第一秒:增量值為 5。
第二秒:增量值為 7。
第三秒:增量值為 8。
後端處理:後端系統(如 Graphite)根據這些增量值計算錯誤速率。
例子二:高基數場景下的應用
假設有一個電商平台,需要追蹤每個用戶的購物車添加行為:
指標指標:
cart_additions維度屬性:
user_id高基數:假設有 1,000,000 個用戶,每個用戶都有獨立的
user_id。
使用 'delta' Temporality:
發送端僅需保存每個用戶上一個增量值,降低記憶體需求。
每個報告周期僅傳輸自上一周期以來的增量數據。
Q: What does the Aggregation Temporality of 'delta' indicate for a Sum metric in OTLP?
It includes optional min and max values within the sum metric.
It represents the total sum accumulated since the start of the process.
It represents the sum calculated over specific, non-overlapping time windows.(O)
It ensures that the sum values are always increasing.
Aggregation
Aggregation Temporality(聚合時間性) 是用來描述 Metrics 數據如何隨時間累積或更新的重要概念。當你需要監控並偵測應用程式的process重啟時,選擇合適的 Aggregation Temporality 對於準確捕捉和分析數據至關重要。以下將詳細說明為何 Cumulative Temporality 是適合用於此場景的選擇,以及其運作機制和優缺點。
什麼是 Aggregation Temporality?
Aggregation Temporality 描述的是 metrics 數據如何隨時間累積或更新。主要有兩種類型:
- 累積時間性(Cumulative Temporality):
每個新的 data point 表示從某個固定起始時間點(通常是應用程式啟動時間)到當前時間的累計值。 隨著時間推移,累計值不斷增加(對於單調遞增的 metrics,如請求數、錯誤數等)。
- 增量時間性(Delta Temporality): 每個 data point 僅表示自上一個報告周期以來的增量值。 data point 之間互不重疊,彼此獨立。
Cumulative Temporality 用來分析的優勢︰
提高數據可靠性: 即使在數據收集過程中出現間歇性失敗,累積數據能夠自動平均缺失的部分,保持數據的一致性。
便於速率計算: 累積 Sum 指標可以輕鬆計算出速率(例如每秒請求數),只需對相鄰數據點進行差分運算即可。
Q: You want to monitor and detect process restarts in your application. Which Aggregation Temporality should you use for Sum metrics in OTLP?
Use Histogram metrics with any temporality.
Use Gauge metrics instead of Sum for this purpose.
Cumulative Temporality, to track counts since the process started.(O)
Delta Temporality, as it resets counts after each interval.
ReAggregation
所謂「Reaggregation(再聚合)」通常包含兩個主要面向:
Temporal Reaggregation(時間上的再聚合)
Spatial Reaggregation(維度上的再聚合)
這兩者皆是「語意不變 (semantics-preserving) 的資料轉換」手段,意即在進行聚合動作後,測量指標在統計或意義上仍與原始資料相符,沒有失去或扭曲原本的含意。以下將分別對這兩種再聚合方式做更詳細的說明:
一、Temporal Reaggregation(時間上的再聚合)
1. 基本概念
Temporal reaggregation 是指對「時間區間」進行再聚合。例如,如果原本的 Metrics 以 1 秒為間隔收集,則可以將多筆資料合併成較長的間隔(比如 5 秒或 1 分鐘)來進行彙整。
目的:
降低資料量與傳輸成本
提供更平滑、更長時間範圍的指標觀察
在需要快速檢視長時間趨勢時,更容易讀取彙總後的趨勢圖
2. 實作方式
累加 (Cumulative) 型測量的再聚合:
若已經以累加方式收集指標,可將原先較細的時間區間內的累加值繼續做合併。例如,將每秒收集的累加值,合併成每分鐘的累加值。
在計算過程中,必須確保相鄰時段的累加值能正確相減或相加,以避免重複計算或遺漏。
增量 (Delta) 型測量的再聚合:
若是增量型資料(每次上報代表該區間的「新增量」),可以將多筆增量相加,得到更長時間區間的增量值。
例如,每秒的增量值加總成每分鐘的增量,即可得到「該分鐘總增量」;或進一步轉換成累加值。
3. 注意事項
時區間對齊 (Boundary alignment):在合併時,需要注意將時間區間對齊(例如,從整點開始計算 1 分鐘,或從整秒開始計算),以避免重疊或空白區間。
原始頻率掌握:再聚合後,由於頻率降低,若需要回溯「較細的時間間隔」訊息,可能喪失這部分解析度。故有時會同時儲存「高頻」與「低頻」兩種資料以備用。
二、Spatial Reaggregation(維度上的再聚合)
1. 基本概念
Spatial reaggregation 是對「維度屬性 (Attributes)」做再聚合,意思是將多維度的 b指標按照需求重新聚合成較少的維度。例如,若原先收集了地區 (region)、版本 (version)、客戶 (customer) 等多種屬性,卻發現只需要針對「地區」做分析,就可以將其他屬性捨棄、合併或重新分類,最終得到僅以「地區」區分的指標數據。
目的:
降低資料的維度複雜度與儲存成本
聚焦於特定關注屬性(如只想看「地區」或「服務」層級的指標)
移除不必要或過多的高維度屬性,減少後台儲存及計算壓力
2. 實作方式
合併多屬性:
- 例如,原始資料以
(region, version, customer)作為屬性鍵,若要聚合成僅依照(region)區分,就需要把同一個region但不同version、customer的資料加總在一起。
- 例如,原始資料以
刪除或重新分類屬性:
若不需要使用的屬性,可以移除。
若是需要做較粗的分類,例如把所有
version=1.x當成一類,version=2.x當成另一類,也是一種再聚合的過程。
3. 注意事項
避免重複或遺漏:在進行屬性合併時,需要確保對同一個屬性區段的資料做完整加總,而非重複或遺漏計算。
語意維護:必須確保合併後的資料仍然能夠代表原本度量指標的意義,不因為合併而破壞了原有的區分度或語意。
高維到低維的不可逆:一旦將多個屬性合併後,就無法再從結果中區分出詳細的屬性(除非保留了所有原始資料)。
三、使用再聚合的案例
更細到更粗:用於長期趨勢分析
- 例如,你有一個高頻率的 CPU 使用率指標資料(每秒收集一次)。當你只想觀察一整天、每小時的平均使用率走勢時,可以對這些每秒資料進行 Temporal reaggregation,聚合為每小時一筆指標,使走勢更易讀、資料量更小。
減少維度:降低儲存與運算成本
- 例如,你收集了多個服務版本、部署地區、客戶群等屬性。後來發現你只需要按照地區區隔的資料即可,便可將其他維度屬性進行 Spatial reaggregation,合併成僅按地區分組的指標,減少數據爆炸並降低儲存成本。
Delta-to-Cumulative 的轉換
- 有些資料以 delta(增量)形式呈現,若在系統後端或在 OpenTelemetry Collector 中進行再聚合,可以將這些分散的小區間增量合併成較大區間,或轉換成累加值 (cumulative)。如此可在下游更容易計算速率或直接觀察整體累計情況。
在 OpenTelemetry 中,Reaggregation 不管是時間上(Temporal)或維度上(Spatial),核心目的都是為了在不改變資料語意的前提下,讓資料處理更有效率、更容易分析或更易於儲存。由於 OpenTelemetry Metrics 資料模型先天支援這些再聚合操作,因此可以在多個階段(例如在 SDK 端或 Collector 端)自由地對資料做再聚合處理,根據需求不同彈性調整資料的粒度與維度。
換句話說,Reaggregation 能夠幫助你:
降低維度與時間解析度,取得更小體量或更符合需求的長期度量資料。
保留測量意義 (Semantics),確保再聚合過程不失真、不重疊、也不破壞指標的統計邏輯。
在不同階段(SDK/Collector)進行:可以在資料源頭就先聚合,或在後端再聚合,因應不同環境的資源考量與使用情境。
這些優勢讓 OpenTelemetry 在測量指標系統上更具備靈活性與可擴展性,為使用者及後續分析工具提供多層次的觀測能力與選擇。
Q: Which of the following best describes temporal reaggregation in the OpenTelemetry data model?
Reducing the number of metric attributes.
Converting Delta metrics to Cumulative metrics.
Merging multiple metric streams into one.
Aggregating high-frequency metrics into longer time intervals.(O)
Q: You are configuring the OpenTelemetry Collector to handle metrics with a resolution of 10 seconds and need to aggregate them into 60-second intervals without altering their attributes. Which use-case from the core use cases applies?
Collector re-aggregates into longer intervals without changing attributes.(O)
Collector passes-through original data to an OTLP destination.
Collector re-aggregates to eliminate the identity of individual SDKs.
Collector converts delta to cumulative temporality.
因為metrics的解析度是10秒一個,但我們要的是每60秒的,此時 collector 可以 re-aggreate成60秒解析度的metrics。Use-cases #4就是這情境。
TImeseries model
基本屬性有 metric name、attributes、date value type、unit
類型有 Counter、Gauge、Histogram和Exponential histogram。Timeseries model 可以被視為是 Prometheus remode write。
Metric object 對象
Metric object表示的是隨時間變化的 data point 序列,每個data point都有一個時間戳,這與Timeseries Model的特性完全一致。因此Metric object 屬於 **Timeseries Model。**被定義在 OTel protocol 的proto中。
Metric object的結構如下:
message Metric {
string name = 1;
string description = 2;
string unit = 3;
oneof data {
Gauge gauge = 5;
Sum sum = 7;
Histogram histogram = 9;
ExponentialHistogram exponential_histogram = 10;
Summary summary = 11;
}
repeated opentelemetry.proto.common.v1.KeyValue metadata = 12;
}
Metric object的識別屬性主要用於唯一區分不同的 metric stream。這些屬性確保每個metric stream能夠被準確識別、聚合和處理。以下屬性被視為識別屬性:
Metric name
Metric datat type,包括
Gauge、Sum、Histogram、ExponentialHistogram和Summary。Unit
Attributes,
attributes是識別屬性的重要組成部分,通過不同的屬性組合來區分不同的metric stream。例如,method=GET和method=POST將創建兩個不同的 metric stream。Aggregation Temporality,指示 metric 是如何隨時間累積的,例如
Cumulative或Delta。Monotonicity,是否單調遞增
Q: In the OpenTelemetry Protocol (OTLP) data model, which of the following properties is considered identifying for a Metric object?
Metric stream’s unit(O)
Scale of an ExponentialHistogram data point
Metric stream’s description
Bucket boundaries of a Histogram data point
Histogram
Histogram 的 min 和 max 屬性 Histogram 指標用於表示數據的分佈情況,min 和 max 屬性分別記錄該時間區間內觀測到的最小值和最大值。
為何 Delta Temporality 更適合 min 和 max
反映即時分佈: Delta Temporality 下的 min 和 max 僅涵蓋當前報告周期內的數據,因此能夠即時反映該時間窗口內的數據分佈情況。 例如,每分鐘的最小值和最大值可以幫助快速識別該分鐘內的異常情況或性能瓶頸。
避免數據累積帶來的失真:
Cumulative Temporality 下,min 和 max 是自應用啟動以來的整體最小值和最大值。隨著時間推移,這些值可能會變得穩定,無法反映近期數據的變化。 如果應用程式在某個時刻出現異常數據,累積 min 和 max 不會立即反映這些變化,因為它們被歷史數據所稀釋。
- 簡化異常偵測:
使用 Delta Temporality,當某個報告周期內的 min 或 max 發生劇烈變化時,可以快速判斷出該時間段內的異常事件,如系統重啟、突發流量增長等。 在 Cumulative Temporality 下,這類變化可能不易察覺,因為 min 和 max 已經包含了大量歷史數據。
- 提升可觀測性與響應速度:
Delta Temporality 提供了更細粒度的數據,使得監控系統能夠更快地響應和處理當前的數據趨勢。 對於需要即時響應的應用場景,如實時性能監控和警報系統,Delta Temporality 的 min 和 max 更具價值。
Q: In which Aggregation Temporality are the min and max fields of a Histogram metric more useful in OTLP?
Both Delta and Cumulative Temporality equally utilize min and max.
Min and max are not used in Histogram metrics.
Delta Temporality, because min and max represent values within each interval.(O)
Cumulative Temporality, because min and max represent values since the start.
ExponentialHistogram
ExponentialHistogram 是一種專門用於表示數值分佈的數據結構。與傳統的直方圖相比,ExponentialHistogram 通過指數級別的桶(buckets)來分組數據,使其能夠高效地表示廣泛範圍內的數據分佈,尤其適用於高基數(Cardinality)或大範圍的度量數據。
ExponentialHistogram 的組成部分
Zero Bucket(零桶):專門用於統計值為零的數據點。當初小弟的書 5-3 也特別提到 Zero bucket。
Positive Buckets(正向桶):用於統計大於零的數據點,按照指數級別分組。
Negative Buckets(負向桶):用於統計小於零的數據點,通常不常用於某些應用場景。
Zero Threshold(零閾值):定義在合併過程中如何處理零桶及其相鄰桶的邊界。
Zero Threshold 的定義 Zero Threshold 是一個關鍵參數,用於確定在合併 ExponentialHistograms 時,如何處理不同直方圖之間的零桶及其相鄰桶的邊界。具體而言,zero_threshold 決定了零桶的寬度以及如何將具有不同零閾值的直方圖進行對齊和合併。
不同的應用場景和數據分佈特性可能需要不同的 zero_threshold。例如:
高精度需求:某些應用可能需要更精細的零桶,以準確捕捉接近零的微小變化。 資源限制:在資源受限的環境中,可能需要較寬的零桶以減少記憶體和計算成本。 這些差異導致了在不同的 ExponentialHistograms 中存在不同的 zero_threshold。
合併具有不同 Zero Threshold 的 ExponentialHistograms 的挑戰
當嘗試合併具有不同 zero_threshold 的 ExponentialHistograms 時,可能會遇到以下挑戰:
桶對齊問題:不同的 zero_threshold 會導致桶的邊界不一致,直接合併可能導致數據重複計算或遺漏。 數據失真風險:不正確的合併策略可能會扭曲原始數據的分佈,影響後續的分析和報告。 複雜的處理邏輯:需要額外的邏輯來調整和對齊不同的 zero_threshold,增加實現的複雜度。 為了解決這些問題,OpenTelemetry 提出了具體的合併策略。
- 採用最大的 Zero Threshold 在合併具有不同 zero_threshold 的 ExponentialHistograms 時,應採用其中最大的 zero_threshold 作為合併後的共用零桶閾值。這樣做的原因包括:
包含性:較大的 zero_threshold 能夠包含所有較小 zero_threshold 的數據範圍,避免數據丟失。
簡化合併過程:統一的 zero_threshold 簡化了後續的桶對齊和數據合併邏輯。
- 合併較小 Zero Threshold 的低桶至共用更寬的零桶 具體步驟如下:
確定最大的 Zero Threshold:在待合併的 ExponentialHistograms 中,選擇最大的 zero_threshold 作為合併後的零桶閾值。
調整較小 Zero Threshold 的桶: 將那些 zero_threshold 小於最大值的直方圖的低桶(靠近零的桶)合併到新的更寬的零桶中。 這意味著,原本由較小 zero_threshold 定義的多個低桶將被整合到一個更大的零桶中,確保不會重複計算或遺漏數據。
合併數據:在統一的零桶閾值基礎上,合併所有直方圖的桶數據,包括調整後的零桶。
假設有兩個 ExponentialHistograms: Histogram A: Zero Threshold:1 Buckets:0, (1,2], (2,4], (4,8], ...
Histogram B: Zero Threshold:2 Buckets:0, (2,4], (4,8], (8,16], ...
合併步驟:
選擇最大 Zero Threshold:2
調整 Histogram A 的低桶: 將 (1,2] 這個桶的數據合併到新的零桶中,形成一個更寬的零桶 (0,2]。
3 統一桶結構: 新的零桶 (0,2] 之後的桶保持一致:(2,4], (4,8], (8,16], ...
4 合併數據: 零桶 (0,2] 包含 Histogram A 的 (0,1] 和 (1,2] 兩個桶的數據,以及 Histogram B 的 (0,2] 桶的數據。 其他桶按照相同的範圍進行數據合併。
ps. 合併過程可能涉及大量數據的處理,尤其是在高基數(Cardinality)場景下。因此,實現合併策略時需要考慮性能優化,如批量處理和並行計算。
實際應用案例
多服務合併指標數據 假設一個大型分散式系統中有多個服務,每個服務使用不同的 zero_threshold 來收集其指標數據。在這種情況下,當需要將這些指標數據合併到一個中央監控系統(如 OpenTelemetry Collector)時:
識別最大的 zero_threshold:確定所有服務中最大的 zero_threshold,例如 4。 調整其他服務的低桶:將其他服務(如使用 zero_threshold=2)的低桶合併到新的零桶 (0,4] 中。 合併數據:根據統一的桶結構將所有服務的數據進行合併,確保最終的 ExponentialHistogram 能準確反映整個系統的數據分佈。
處理系統重啟或配置變更 當系統配置變更,導致某些服務的 zero_threshold 從較小值調整為較大值時,採用上述策略可以確保在變更前後數據的無縫整合,避免因配置變更導致的數據異常或丟失。
ExponentialHistogram 的桶映射機制
桶索引與邊界
ExponentialHistogram 使用指數級別的映射來劃分數據桶。每個桶由一個整數索引標識,並且對應於一個具體的數值範圍。具體來說:
正範圍(Positive Range):
- 桶索引
i表示數值大於base^i且小於或等於base^(i+1)的範圍。
- 桶索引
負範圍(Negative Range):
對於負數,將其絕對值映射到正範圍,並使用相同的指數級別進行劃分。
在負範圍中,桶的下邊界是包含的(lower-inclusive)。
映射函數的作用
映射函數(Mapping Function)負責將測量值(Measurement)映射到對應的桶索引。具體步驟包括:
確定測量值的範圍:判斷測量值是屬於正範圍還是負範圍。
計算對應的指數:基於
base,計算測量值應該落在哪個指數級別。映射到桶索引:將指數級別轉換為具體的桶索引。
為何精確映射困難
實現精確的映射函數存在多重挑戰,主要包括:
浮點數表示的限制:
許多指數級別的邊界無法被精確表示為二進制浮點數(如 IEEE 754 標準的雙精度浮點數)。
這導致在計算
base^i時,可能出現微小的誤差,從而影響測量值的精確映射。
實現複雜性:
精確映射需要複雜的數學計算和處理,以確保每個測量值都能被正確且精確地映射到相應的桶索引。
這不僅增加了實現的難度,還可能影響性能,特別是在高頻率的度量數據處理中。
推薦的精度要求
鑑於上述挑戰,ExponentialHistogram 設計中推薦:
這意味著映射函數在大多數情況下應能將測量值正確地映射到相鄰的桶索引之間,確保映射結果與精確映射結果的差異不超過 1。
為何接受最多差異為 1 的不精確映射?
平衡精度與實現可行性
接受最多差異為 1 的映射精度,實現了一種在精度和實現可行性之間的平衡:
實現簡單:
減少了映射函數的複雜度,使其更容易實現和維護。
減少了對高精度數學運算的依賴,提升了性能。
足夠的實用性:
對於大多數應用場景,這種程度的精度足以捕捉數據分佈的整體趨勢和特徵。
減少了因微小誤差導致的數據偏移或異常,確保了度量數據的穩定性和可靠性。
保證數據的一致性和可靠性
即使存在少量的映射誤差,ExponentialHistogram 仍能保持數據的一致性和可靠性:
統計上的穩健性:
- 微小的桶索引差異不會對整體的數據統計結果產生顯著影響,尤其是在大量數據點的情況下。
容錯能力:
- 系統能夠容忍少量的映射誤差,避免因微小偏差導致的系統不穩定或數據錯誤。
zero_threshold 與 zero_count 桶
在 OpenTelemetry 的 ExponentialHistogram 中,zero_count 桶扮演著重要的角色,特別是在處理接近零或無法被標準指數映射公式精確表示的數值時。當 zero_threshold 被設置為 0 時,zero_count 桶的具體含義和功能如下:
精確值為零的數據點
當
zero_threshold設置為 0 時,zero_count桶會統計所有精確等於零的測量值。這意味著任何測量值如果其絕對值為零,將被計入此桶中。無法通過標準指數映射公式表示的Data point
ExponentialHistogram使用指數級別的映射來劃分數據桶。然而,某些極小或極大的數值可能無法被精確地通過這種指數映射公式表示。這些無法被精確映射的數值也會被歸類到zero_count桶中。被四捨五入為零的數據點
在實際應用中,由於浮點數表示的限制或其他數值處理過程,某些接近零的數值可能會被四捨五入為零。這些被四捨五入為零的數值同樣會被計入
zero_count桶中。
zero_threshold 的作用
定義範圍:
zero_threshold定義了哪些數值應被歸類到zero_count桶中。具體來說,所有絕對值小於或等於zero_threshold的數值都會被計入該桶。設置為 0 的意義:當
zero_threshold設置為 0 時,zero_count桶僅包含絕對值為零的數據點,以及上述提到的無法精確映射或被四捨五入為零的數據點。
實際應用中的影響
1. 數據完整性
zero_count 桶確保了即使在極端情況下(如接近零的數值或無法精確表示的數值),所有測量值都能夠被統計和處理,從而保證了數據的完整性。
2. 數據分析的準確性
通過將無法精確映射或被四捨五入為零的數值集中在 zero_count 桶中,數據分析和後續的可視化處理可以更準確地反映實際情況,避免因數值處理誤差導致的偏差。
3. 性能優化
將這些特殊數值集中處理有助於優化存儲和計算效率,因為不需要為每個極小或無法映射的數值單獨維護一個桶,而是統一處理,提高了系統的性能。
Q: When merging ExponentialHistograms with different zero_threshold values, what is the recommended approach?
Convert all zero_thresholds to zero before merging.
Take the smallest zero_threshold and merge wider zero buckets into smaller ones.
Histograms with different zero_threshold cannot be merged.
Take the largest zero_threshold and merge lower buckets of histograms with smaller zero_thresholds into the common wider zero bucket.(O)
Q” According to the ExponentialHistogram design, what is the recommended precision for producers when using an inexact mapping function?
Producers should ensure that the mapping function difference is at most 2 from the correct result for all inputs.
Producers should use a mapping function with an expected difference of at most 1 from the correct result for all inputs. (O)
Producers should use an exact mapping function for all inputs.
Producers can use any mapping function as precision does not matter.
Q: In which Aggregation Temporality are the min and max fields of a Histogram metric more useful in OTLP?
Both Delta and Cumulative Temporality equally utilize min and max.
Min and max are not used in Histogram metrics.
Delta Temporality, because min and max represent values within each interval. (O)
Cumulative Temporality, because min and max represent values since the start.
Q: What is the primary role of the Event Model in OpenTelemetry's metrics data architecture?
Storing metric data in a database.
Recording raw data observations via instruments. (O)
Aggregating metrics for export.
Defining how metric data is transmitted.
Q: Which of the following use-cases is considered out of scope for the OpenTelemetry metrics data model?
OTel SDK exporting data to an OpenTelemetry Collector.
Collector applying a distinct external label to metrics.
Collector re-aggregating metric data into longer intervals.
Importing Prometheus endpoint scrape data into OTLP.(O)
Q: In the OpenTelemetry metrics data model, which component defines the structure and properties such as metric name, attributes, value type, and unit of measurement?
Metric Stream
Event Model
Instrument Model
Timeseries Model**(O)**
Q: Which of the following transformations is used in OpenTelemetry to reduce the number of attributes in metric data?
Histogram normalization
Spatial reaggregation(O)
Temporal reaggregation
Delta-to-Cumulative
Q: Your system needs to export metric data to Prometheus Remote Write while automatically handling attribute removal and histogram resolution reduction. How can OpenTelemetry facilitate this?
Implement custom exporters within the application code.
Translate metrics manually before exporting to Prometheus.
Configure the OpenTelemetry Collector with a Prometheus Remote Write exporter and enable automatic transformations.(O)
Use only the OpenTelemetry SDK without a collector.
Metrics SDK
OTel Collector Deployment
更多的佈署模式介紹能參考這裡 collector-deployment-patterns。
Agent 模式(Collector as an Agent)
Agent 模式 是將 Collector 部署在每個應用程序所在的主機上,通常作為一個 Sidecar 或 local 服務運行。這種模式適用於分布式系統和微服務架構。
特點
本地部署:Collector 與應用程序運行在同一主機或同一容器中。
低延遲:由於數據收集和處理在 local 完成,減少了網路傳輸的延遲。
高可用性:每個應用程序實例都有自己的 Collector,不會因為單點故障影響整體系統。
Gateway 模式(Collector as a Gateway)
Gateway 模式 是將 Collector 部署為一個集中式服務,通常運行在數據中心、Kubernetes 集群或雲端平台上,負責接收來自多個 Agent Collector 或直接來自應用程序的數據。
特點
集中管理:所有遙測數據通過中心化 gateway 進行處理和導出。
高吞吐量:集中式部署能夠處理來自多個來源的大量數據。
Q: What is the main advantage of deploying the OpenTelemetry Collector as an Agent alongside each application instance?
It allows for in-process data collection and minimizes network latency.(O)
It provides advanced data aggregation features that are not available in Gateway mode.
It centralizes data processing and reduces the need for multiple Collector instances.
It simplifies the configuration by using a single Collector for all applications.
Q: Which deployment strategy involves running an OpenTelemetry Agent alongside each application container within a Kubernetes pod?
Host-Level Installation
DaemonSet
Cluster-Level Deployment
Sidecar Pattern(O)
Q: Your organization is running multiple containerized microservices in Kubernetes. Each service needs to collect telemetry data with minimal configuration changes. Which OpenTelemetry deployment strategy should you implement to achieve this?
Gateway Mode
DaemonSet
Host-Level Installation
Sidecar Pattern(O)
Q: Which of the following is NOT an advantage of using OpenTelemetry Agents in specific scenarios?
Simplified Deployment due to their lightweight nature.
Tight Integration with application runtime.
Reduced Network Overhead through local data processing.
Advanced data transformation and enrichment capabilities.(O)
Q: Which deployment pattern involves running a standalone OpenTelemetry Collector service that aggregates telemetry data from multiple agents before exporting it?
Agent Deployment
DaemonSet Deployment
Gateway Deployment(O)
Sidecar Deployment
Q: What is a key advantage of deploying the OpenTelemetry Collector as a DaemonSet in a Kubernetes cluster?
It simplifies the Collector configuration by centralizing it in one location.
It deploys Collectors on every node, ensuring comprehensive coverage and uniform data collection. (O)
It ensures that a single Collector handles all telemetry data from the cluster.
It allows Collectors to be dynamically scaled based on telemetry data volume.
DaemonSet 是 Kubernetes 中的一種控制器,用於確保集群中的每一個節點上都運行一個特定的 Pod。當有新的節點加入集群時,DaemonSet 會自動在該節點上部署一個 Pod;當節點被移除時,DaemonSet 也會相應地刪除該節點上的 Pod。
Q: What is a primary benefit of using the agent collector deployment pattern in OpenTelemetry?
Increased flexibility in configuring telemetry pipelines
Simplified initial setup with a clear 1:1 mapping between application and collector (O)
Reduced latency by processing telemetry data within the application
Enhanced scalability across multiple hosts
Q: Which deployment model allows the OpenTelemetry Collector to handle telemetry data from multiple sources and perform advanced processing before exporting?
Gateway Mode(O)
Sidecar Pattern
Agent Mode
Host-Level Installation
語義約定(Semantic Conventions)與 Telemetry Schemas語義約定的核心作用
語義約定的核心作用
標準化屬性名稱和取值
語義約定為遙測數據中的各種屬性(如 Span 屬性、指標名稱、事件類型等)提供了標準化的名稱和取值範圍。例如,HTTP 請求的屬性可能包括 http.method、http.status_code 等,這些名稱和取值在不同的遙測源和消費者之間保持一致。
確保數據一致性和可理解性
通過統一的語義約定,不同的遙測源生成的數據能夠被遙測消費者正確解釋和處理,避免因屬性名稱不一致或取值範圍不同導致的數據混淆和誤解。
OTel Schema
定義與目的
在 OpenTelemetry 中,語義約定(Semantic Conventions) 定義了遙測數據中屬性的標準名稱和取值,確保不同遙測源(如應用程序、服務)和遙測消費者(如觀測後端、分析工具)之間的一致性和兼容性。然而,隨著時間的推移,需求的變化和技術的進步,語義約定可能需要進行調整和更新。這種變更在實施時面臨多重挑戰。
Telemetry Schemas 的引入
Telemetry Schemas 用於定義遙測數據(如追蹤、指標、日誌)的結構和屬性的規範,確保遙測數據的一致性,並使遙測數據來源和消費者之間能夠有效協同工作。隨著系統的演進,遙測數據的結構和屬性可能會發生變化。如果沒有明確的 schema 規範,這些變化可能會導致數據消費者無法正確解析或處理遙測數據,進而引發兼容性問題。因此,Telemetry Schemas 提供了一個明確的規範,使不同版本的遙測數據能夠被正確處理和轉換。
Schema URL 與版本管理
Schema URL 的定義
schema_url 是一個唯一的標識符,用於指向特定版本的 Telemetry Schema 文件。這個 URL 必須是可通過 HTTP 或 HTTPS 訪問的完整地址,確保遙測數據消費者能夠根據這個 URL 下載並應用相應的 schema 轉換規則。
Schema 版本號與 Schema URL 的對應關係
在 Telemetry Schemas 中,每個 schema 文件都包含一個 versions 部分,列出了該 schema 所有支持的版本。根據 OpenTelemetry 的設計規範,schema_url 必須對應於 versions 部分中定義的最高版本號。這樣做的原因包括:
最新特性支持:最高版本通常包含最新的特性和修正,確保遙測數據能夠利用最新的 schema 規範。
向後兼容性:通過明確指定最高版本,遙測數據消費者可以根據需要將數據轉換到所需的版本,保持向後兼容性。
一致性與可靠性:確保所有生成的遙測數據都遵循一致的規範,減少因版本不一致導致的錯誤。
官方文檔中的說明
在 OpenTelemetry 的官方文檔中,有關 schema_url 與版本管理的詳細說明可參考以下部分:
在該文檔中,特別提到了 schema_url 的用途和版本管理機制。根據描述:
Schema URL 是 Telemetry Schema 的唯一標識符,指向具體版本的 Schema 文件。每個 Schema Family 的最高版本號應與
schema_url中指定的版本號一致,確保遙測數據的正確轉換和兼容性。
這段描述強調了 schema_url 必須與 versions 部分中的最高版本號相對應,以確保遙測數據能夠正確轉換和解析。
變更語義約定帶來的挑戰
消費者對既定屬性的依賴
遙測消費者(如監控後端、分析工具)通常依賴於既定的語義約定來解析和處理遙測數據。例如,一個後端系統可能期望 http.status_code 屬性存在並具有特定的取值範圍來進行錯誤率分析。如果語義約定發生變更,導致屬性名稱改變或取值範圍調整,這些消費者將無法正確識別和處理數據,從而影響整個觀測流程的準確性和可靠性。
版本兼容性的管理
為了減少破壞性變更帶來的影響,語義約定需要引入版本控制機制。然而,這增加了管理的複雜性:
版本識別:需要為每個語義約定版本分配唯一的標識符(如
schema_url),以便消費者能夠識別和處理不同版本的數據。轉換規則:需要定義不同版本之間的轉換規則,確保數據在不同版本之間的兼容性和一致性。
解決挑戰的策略
Telemetry Schemas 的引入
為了應對語義約定變更帶來的挑戰,OpenTelemetry 引入了 Telemetry Schemas。這些 Schemas 定義了遙測數據的結構和轉換規則,具備以下特點:
版本化管理:每個 Schema 版本都有唯一的
schema_url,並且不可變更,確保版本之間的穩定性。轉換規則:明確定義了不同版本之間的轉換操作,確保數據在版本升級過程中的兼容性。
獨立演進:允許遙測來源和消費者在不影響對方的情況下獨立演進,只需通過
schema_url來識別和處理不同版本的數據。
使用 Schema Translator
遙測消費者可以使用 Schema Translator 將接收到的數據轉換為目標 Schema 版本,從而保持對不同版本數據的兼容性。例如:
後端系統升級:後端系統升級到新版本的 Schema,不需要立即要求所有遙測源同步更新。Schema Translator 可以在後端系統和遙測來源之間進行數據轉換,實現平滑過渡。
遙測源逐步更新:遙測來源可以逐步更新到新版本的 Schema,同時保持對舊版本數據的支持,確保消費者能夠正確處理不同版本的數據。
強化版本控制與參考文件
為了有效管理 Schema 版本,OpenTelemetry 建議:
明確的版本號規範:採用類似 semver 的版本號規範,確保版本號具有明確的意義和排序。
詳細的變更記錄:每個 Schema 版本都應有詳細的變更記錄,說明引入的變更和相應的轉換規則。
易於訪問的 Schema 存儲:通過穩定的 URL 來存儲和訪問 Schema 文件,方便遙測源和消費者查詢和下載。易於訪問的 Schema 存儲:通過穩定的 URL 來存儲和訪問 Schema 文件,方便遙測源和消費者查詢和下載。
Telemetry Schemas 的使用案例
完全 Schema 感知的系統
情景描述:
Telemetry Source 發出符合版本 1.2.0 Schema 的 spans,其中包含
deployment.environment屬性來標識 span 來自營運環境。Telemetry Consumer 希望將這些 spans 存儲為符合版本 1.1.0 Schema。
Schema Translator 比較接收到的 spans 的 Schema URL 與目標 Schema,發現需要進行轉換,將
deployment.environment屬性重命名為environment,然後存儲轉換後的 span。
優點:
支持不同版本 Schema 的並存與轉換。
保證數據的兼容性和一致性。
通過 Collector 協助 Schema 轉換
情景描述:
Telemetry Consumer 不具備 Schema 感知能力,依賴 OpenTelemetry Collector 來轉換遙測數據到後端期望的 Schema。
配置 Schema Translate Processor 指定目標 Schema URL,Collector 將接收到的數據轉換為目標 Schema 後發送到後端系統。
優點:
使後端系統無需具備 Schema 感知能力即可處理多版本 Schema 的數據。
集中式管理 Schema 轉換,簡化後端系統的實現。
Telemetry Schemas 的實施細節
Schema URL 的結構
格式:
http[s]://server[:port]/path/<version>
Schema Family:
- URL 的前部分(除版本號外)稱為 Schema Family identifier,同一族的所有 Schema 具有相同的 Family identifier。
版本號:
- 使用
MAJOR.MINOR.PATCH格式,按照 semver 2.0 規範排序。
- 使用
Schema 的不可變性
一旦 Schema 文件發布後,不可更改。
新版本需作為新的 Schema 文件發布,確保舊版本的數據仍可被正確處理。
API 支持
- OpenTelemetry API 允許獲取與 Schema URL 關聯的 Tracer/Meter,確保發出的遙測數據包含正確的 Schema URL。
第三方支持
第三方套件和應用:
- 建議第三方套件、檢測庫或應用程序定義並發布自己的 Schema,若其遙測數據與 OpenTelemetry Schema 完全不同,並在發出遙測數據時包含相應的 Schema URL。
Telemetry Schemas 的實際應用
在 Kubernetes 環境中的應用
Agent 與 Gateway 模式結合:
Agent Collector 作為 DaemonSet 部署在每個節點上,負責本地數據收集和初步處理,並包含 Schema URL。
Gateway Collector 集中處理來自所有 Agent Collector 的數據,根據目標 Schema 進行轉換和導出。
多租戶環境中的應用
租戶隔離:
- 為每個租戶定義獨立的 Schema,並在發出數據時包含相應的 Schema URL,確保不同租戶的數據不混淆。
版本升級與數據遷移
平滑過渡:
- 當需要升級 Schema 版本時,通過定義轉換規則,確保舊版本數據能夠平滑過渡到新版本,避免系統中斷或數據不一致。
具體配置示例
schemas/1.26.0 開頭就給了範例,首先給了schema_url以及file_format,然後還有給轉換規則 rename_metrics。
file_format: 1.1.0
schema_url: https://opentelemetry.io/schemas/1.26.0
versions:
1.26.0:
metrics:
changes:
# https://github.com/open-telemetry/semantic-conventions/pull/966
- rename_metrics:
db.client.connections.usage: db.client.connection.count
db.client.connections.idle.max: db.client.connection.idle.max
db.client.connections.idle.min: db.client.connection.idle.min
db.client.connections.max: db.client.connection.max
db.client.connections.pending_requests: db.client.connection.pending_requests
db.client.connections.timeouts: db.client.connection.timeouts
配置說明
file_format:指定 Schema 文件的格式版本。
schema_url:指向具體版本的 Schema 文件的 URL。
versions:
- 1.26.0:定義此版本的 Schema 變更,包括指標的重命名規則。
如何使用這個 Schema
配置 OpenTelemetry Collector:
- 在 Signal to Metrics Connector 或其他相關連接器中,設置
schema_url指向最新版本的 Schema。
- 在 Signal to Metrics Connector 或其他相關連接器中,設置
Schema Translator:
- Collector 使用轉換規則,將舊版本的數據轉換為新版本,確保數據的一致性和兼容性。
生成和轉換 Metric:
- 當遙測數據源發出符合
checkout_service的checkoutSpan 時,Collector 根據 Schema 定義生成相應的 Metric,並應用必要的轉換規則。
- 當遙測數據源發出符合
Collector Processor
Transform Processor
是 OpenTelemetry Collector 提供的一個強大處理器,主要用於對遙測數據進行動態轉換。它允許用戶在數據流中通過條件語句、上下文設定和轉換規則,根據需求修改遙測數據的屬性或結構。
功能特點
上下文感知處理:
Transform Processor支援基於不同上下文(如 resource、scope、span、metric、log 等)的轉換。可以根據上下文層級進行高效數據處理,例如只修改資源屬性而不影響 span 細節。
條件處理(Conditional Transformation):
使用
conditions和where語句定義條件。條件支持複雜的邏輯判斷,例如檢查屬性的類型、值或結構。
語句式轉換(Statement-Based Transformation):
支援對屬性進行操作,如新增、新增預設值、覆蓋、刪除屬性等。
支援將某一屬性的值賦值給另一個屬性。
多信號支援:
- 可以處理 Trace、Metric 和 Log 數據,為不同類型的信號設置專屬轉換邏輯。
在 OpenTelemetry 的架構中,遙測數據的層次結構反映了不同級別的上下文範圍。這些層次通常從最廣泛的資源層開始,逐漸細化到具體的數據單元(如 span、metric datapoint、log entry 等)。以下是具體層次的排序及其作用:
1. Resource(資源層級)
定義:資源層級表示整體系統或服務的上下文,例如運行的應用程序、容器、主機或雲環境等。
範例屬性:
service.name:服務名稱。host.id:主機唯一標識。cloud.region:雲環境的區域。
用途:提供與所有遙測數據相關的全局上下文,例如標識數據來自哪個服務或環境。
層次範圍:最高層級,影響所有信號(logs、metrics、traces)。
2. Scope(範疇層級)
定義:範疇層級描述生成遙測數據的具體模組或套件(通常是 SDK)。
範例屬性:
instrumentation.library.name:使用的 SDK 或套件名稱。instrumentation.library.version:版本號。
用途:提供生成遙測數據的工具相關資訊,便於理解和調試。
層次範圍:位於 Resource 之下,但適用於所有信號。
3. Signal-Specific Context(信號特定上下文)
每種遙測信號都有其專屬的上下文,適用於更細化的數據範圍:
Trace(追蹤層級)
定義:追蹤層級包含分布式請求的詳細上下文。
範例屬性:
trace_id:追蹤的唯一標識。span_id:當前 span 的唯一標識。
層次排序:位於 Scope 之下。
應用範圍:分散式請求和性能分析。
Metric(指標層級)
定義:指標層級專注於數據點和相關上下文。
範例屬性:
metric.name:指標名稱。datapoint.value:具體數值。
層次排序:位於 Scope 之下。
應用範圍:性能和資源利用率監控。
Log(日誌層級)
定義:日誌層級專注於單一事件的記錄。
範例屬性:
log.severity:事件的嚴重性(INFO、WARN 等)。log.body:具體的日誌內容。
層次排序:位於 Scope 之下。
應用範圍:事件記錄和故障排除。
4. Data Point(數據單元層級)
定義:數據單元層級描述單一的數據點,例如單個 span event、metric data point 或 log entry。
範例屬性:
Span Event:時間戳和事件名稱。
Metric Data Point:具體值和標籤。
Log Entry:日誌的內容和時間。
層次範圍:最低層級,僅影響具體數據單元。
層次的排序和關係
從最高層到最低層:
Resource:影響所有信號的全局屬性。
Scope:提供生成數據的模組或工具上下文。
Signal-Specific Context:根據信號類型(Trace、Metric、Log)定義特定的上下文。
Data Point:具體的數據單元,細化到最小粒度。
Q: In the transform processor, what is the effect of setting a context's statements to transform resource attributes rather than using a span context?
It accesses higher-level resource attributes directly, improving performance.(O)
It is less efficient because it processes lower-level contexts first.
It allows accessing individual spans within the resource.
It restricts transformations to only the first span.




