

System Design Interview Ch 1

前言
這本書的重點面試中關於系統設計問題的環節。因為系統設計沒有範圍沒有固定模式,什麼都能提出來討論跟討論,問題範圍太大,整個過程非常開放,且幾乎沒有標準答案。
所以在這過程中,主要考察的是溝通與問題解決能力。評估面試者如何分析與拆解問題,並且與面試官說明想法與討論。
系統設計問題是開放式的。就像真實世界一樣,系統之間存在各種差異與變體。期望的結果是提出一個能達成系統設計目標的架構。討論方向會依面試官有所不同:有人會涵蓋所有層面的高階架構,也有人會挑出一兩個領域深入鑽研。一般而言,系統需求、限制(constraints)與瓶頸(bottlenecks)必須被充分理解,才能引導雙方後續的討論方向。
小弟的心法
不急著畫架構——先問清需求與假設。
每個決策都能說明「為什麼不是另一種」。
面試更像協作設計會議,而非單人獨白。
有條理比「炫技」重要;框架 + 邏輯推進 > 記憶片段。
討論流程
通用流程框架(需求 → 容量估算 → 高階架構 → 核心元件 → 資料流 → 優化 → 風險 & 改進)
主題化整理(儲存、Cache、索引、排程、排隊、監控)
Ch1 從 Zero 擴展到支援 Millions 的使用者
一個系統能從支援在線幾百人、幾千人、幾萬人、幾百萬人,這是一個演化的過程,幾乎不太能一步到位的。基本都從支援極少的使用者開始設計,再逐步擴展到能服務百萬使用者。
單一伺服器架構(Single Server Setup)
打造一個複雜系統也是如此。都是從最簡單開始:所有東西都跑在同一台伺服器(web service、資料庫、cache service 等全部同一主機運行。)上。目標是完成業務功能與驗證。
請求與回應
為了理解這個架構,先看「Request 流程」與「Traffic 來源」。
Request 流程︰
使用者透過網域名稱(例如:api.mysite.com)存取網站。通常 DNS 是第三方的付費服務(例如 Route53, Cloudflare DNS…),而不是由我們自己的伺服器託管。
DNS 解析後會將 IP 位址回傳給瀏覽器或手機應用。在例子中,回傳的 IP 是 15.125.23.214。
一旦取得 IP 位址,瀏覽器或行動 App 會直接向你的 Web 伺服器送出 HTTP request。
Web 伺服器回傳 HTML 頁面或 JSON 回應,供前端渲染。

接著看流量來源︰到達你 Web 伺服器的流量來自兩種來源:Web 應用與 App 應用。
Web 應用:使用Server side language(例如 Java、Python 等)處理商業邏輯、資料儲存等,再用前端技術(HTML、JavaScript)呈現。
行動應用:行動 App 與 Web 伺服器之間以 HTTP 協定溝通。
不論哪種 Web service 都要提供 Web API 例如 GET /users/12 請求.取得 JSON 內容
{
"id": 12,
"firstName": "xxx",
"lastName": "yyy",
"address": {
"city": "Taipei",
"postalCode": "100"
},
"phoneNumbers": [
"23939889",
"8825252"
]
}

分層,將資料庫獨立出去
隨著使用者數量逐漸成長,一台主機不夠用了,我們需要多台:一台處理流量,另一台作為資料庫。將流量(Web Tier)與資料庫(Data Tier)分離,可以各自獨立擴展。

要用哪種資料庫?
關聯式資料庫(RDBMS) vs 非關聯式資料庫(NoSQL)
RDBMS的資料以「表格 + 列」方式儲存,你可以用 SQL 跨多表做 join。
NoSQL 主要分四大類:Key-Value、Graph、Column、Document。一般不支援 join。
- 這幾乎意味著資料是非結構化,或沒有明確關聯。
關聯式(SQL) vs 非關聯式(NoSQL)深度比較
| 維度 | 關聯式 RDBMS | NoSQL(概括) | 適合情境 |
| 資料模型 | 嚴謹結構(Schema) | 彈性 / 半結構 / 無 Schema | 需求變動快用 NoSQL |
| 查詢能力 | 強大(JOIN, GROUP BY) | 依類型差異大:KV 最弱、Document 中等、Graph 強 | 多維複雜查詢 → RDBMS |
| 交易(ACID) | 原生支援 | 多數弱化(但有改良,如 DynamoDB 的條件寫入) | 金融 / 訂單 → RDBMS |
| 一致性 | 強一致(可調整隔離層級) | 多採最終一致(Eventual Consistency) | 高可用 + 容忍延遲一致 |
| 可擴展性 | 垂直為主(水平需要分片) | 多為天然水平擴展(尤其 KV / Column) | 快速擴容量 → NoSQL |
| 延遲 | 寫讀都穩定,但會因 JOIN 複雜度上升 | KV / Column 可極低延遲 | Ultra 低延遲 → NoSQL |
| 生態成熟度 | 工具、多數工程師熟悉 | 生態片段化 | 團隊熟悉度低 → 先選 RDBMS |
| 成本/維運 | 單體易維護,scale 後複雜 | 分散式一致性/備援需心智成本 | 人力不足 → 先簡單 |
NoSQL 四大類型何時選?
| 類型 | 代表 | 優勢 | 典型場景 |
| Key-Value Store | Redis, DynamoDB | 超低延遲、簡單伸縮 | Session、快取、購物車 |
| Document Store | MongoDB, CouchDB | 半結構 JSON、欄位可變 | CMS、使用者設定、活動資料 |
| Column Family Store | Cassandra, HBase | 寫入量大、時間序列、寬表 | Log、IoT、時間序列聚合 |
| Graph Store | Neo4j, JanusGraph | 圖遍歷、關係跳數 | 社交圖、推薦、欺詐關聯 |
如果你需要:
頻繁 schema 變化 → Document
海量寫入(append-only style)→ Column
超快單 key 存取 → Key-Value
多跳關係(friend of friend)→ Graph
常見「誤解」與反例
| 誤解 | 說明 | 更好思路 |
| 高併發就一定要 NoSQL | 先看 Query Pattern + 快取命中 | 加 Cache + 調索引可能足夠 |
| NoSQL 不需要設計資料模型 | 模型差仍導致查詢/儲存浪費 | 瞭解訪問模式後再定文件結構 |
| RDBMS 不可水平擴展 | 可:分片 / 分區表 / 多租戶設計 | 成本是操作複雜性 |
| Join 不支援 = NoSQL 一定快 | 可能需要在應用層多次 round-trip | 資料壓平(denormalize)需衡量更新成本 |
結構化與非結構化
什麼是「結構化(Structured)」資料?
欄位(Column)固定、類型明確(INT、VARCHAR、DATETIME…)、行(Row)格式一致。
易於使用標準化查詢(SQL)
可建立索引、加約束(UNIQUE、FOREIGN KEY、CHECK)
資料品質高,可做強一致交易(ACID)
本質:Schema-on-write(寫入時即驗證格式)
半結構(Semi-Structured)資料
有基本層次(Hierarchy)與標記(Markers / Tags),但欄位可變;每筆資料不必完全相同。
資料本身以「樹狀 / 巢狀(Nested)」方式呈現,而不是像關聯式資料表那樣固定為二維(rows × columns)。
標記(Markers / Tags)指的是附著在資料上的「自描述結構資訊(Self-describing Metadata)」,幫助系統或人來解析這份資料(白話文即欄位名稱)。
例如︰JSON、XML、YAML、Parquet
常見的有Document Store(MongoDB)、Data Lake(查詢引擎 Presto / Athena)、Columnar files(Parquet 供 OLAP)
Schema 演進成本低,因為欄位名稱與層次一起存放於記錄裡:
新增欄位:新文件直接加;舊文件沒有也不報錯
移除欄位:新文件不再寫;舊文件仍保留歷史值
讀取的程式可以設計成「有則解析,無則給預設值」(能參考 Martin Fowler 的 Tolerant Reader )
更貼近業務事件自然結構
非結構化(Unstructured)資料
缺乏可預測欄位結構,系統很難直接用行列表示語意。
例子:影片、圖片、音訊、自然語言文件(純文字)、PDF。
通常都放 AWS S3、或自己建立檔案系統(FTP)這類的。
設計上會搭配「Metadata」用來建立索引(例如:影像寬高、上傳者、標籤)
本質︰Schema-on-read(讀取 / 分析時才賦予結構)
為何區分這三者?
| 面向 | 結構化 | 半結構 | 非結構化 |
| 可查詢性 | 立即強 | 需索引策略 | 需先萃取特徵 |
| 驗證 | 寫入即驗證 | 可選(驗或放寬) | 幾乎無(靠外部流程) |
| 模型演進 | 嚴謹、成本高 | 中等 | 重度依賴額外處理層 |
| 典型操作 | OLTP | 混合(OLTP + Event) | ETL / 分析 / AI 推論 |
| 索引策略 | B-Tree、Hash | 二級索引、多鍵 | Metadata / 向量索引 |
| 分析工具成熟度 | 高 | 高(日益成熟) | 需前處理 |
不同資料型態 → 不同儲存與存取模式,而非一刀切
Join 的「表面意義」與「深層意義」
表面意義(使用層)
JOIN 是把分散在不同表格中的相關資料「在查詢時動態關聯」起來,例如:
users(使用者)
orders(訂單)
SELECT u.name, o.amount FROM users u JOIN orders o ON u.id = o.user_id
深層意義(設計層)
JOIN 存在的根本原因:你「選擇將資料 Normalization」以:
減少冗餘(避免資料重複)
降低更新異常(Update / Delete / Insert anomalies)
維持一致性(例如使用者名稱更新只改一處)
JOIN 就是「查詢時把拆散的資訊重新拼起來」的計算成本。
「為什麼要拆?拆開後怎麼正確表達『包含』語意?」、怎麼辨別「擁有 (ownership)」 vs 「參考 (reference)」 vs 「成員 (membership)」。
| 層面 | 說明 | 關鍵洞察 |
| 表面(操作層) | SQL 語法:動態關聯多表資料 | 「拼接」分散的資訊片段 |
| 深層(設計層) | 正規化的代價:查詢時重組被拆散的業務實體 | 「為什麼要拆?拆了如何表達完整語意?」 |
正規化 ↔ JOIN 的權衡循環
業務實體 → 正規化拆表 → 減少冗餘 → 需要 JOIN 重組 → 查詢成本 → 考慮反正規化
↑ ↓
←←←←←←←←←← 效能 vs 一致性的永恆拉鋸 ←←←←←←←←←←←←←←←←←←←←←←←
什麼是「包含」語意?
「包含」(X contains Y) 指:X 代表一個聚合整體 (whole),Y 為其組成部分 (parts),Y 的存在或意義與 X 有緊密依附關係(生命週期、識別、權限、保存策略)。
對比:
單純引用 (reference):Post 引用 User(作者),User 不屬於 Post。
成員關係 (membership):Playlist 與 Song,Song 可同時在多個 Playlist。
真正組成/擁有 (composition):Order 與 OrderItem;OrderItem 沒有 Order 就不應存在。
三層視角:語意層 → 結構層 → 實作層
| 層次 | 問題 | 表達工具 |
| 語意層 (Domain) | 這是擁有?聚合?共享資源? | DDD Aggregate、語意語彙 |
| 結構層 (Logical / Relational) | 怎麼拆表與定鍵? | 主鍵/外鍵、唯一約束、級聯 |
| 實作層 (Physical) | 怎麼索引、分片、避免昂貴 JOIN? | 索引、分區、快取、反正規化 |

第一層:語意層(Domain Layer)
核心問題: 這個關係在現實世界中代表什麼?
專注於 業務語意 和 現實世界關係
定義四種關係類型:擁有/組成、引用、成員、依賴
決定資料的 生命週期 和 耦合程度
| 關係類型 | 特徵 | 範例 | 設計含義 |
| 擁有/組成 (Composition) | 強依附、共生命週期 | Order ← OrderItem | 應聚合設計、級聯操作 |
| 引用 (Reference) | 弱耦合、獨立存在 | Post → User (author) | 外鍵約束、但不級聯刪除(生命週期不同) |
| 成員 (Membership) | 多對多、共享資源 | Playlist ↔ Song | 中介表、獨立生命週期 |
| 依賴 (Dependency) | 單向依賴、可替換 | Order → PaymentMethod | 可能需要歷史快照 |
第二層:結構層(Logical/Relational Layer)
核心問題: 如何用關聯式模型正確表達語意?
將語意轉換為 資料庫結構
設計主鍵、外鍵、約束和級聯規則
確保資料的 完整性 和 一致性
| 語意 | 主鍵設計 | 外鍵約束 | 級聯規則 | 唯一性 |
| 組成關係 | 複合鍵 (parent_id, seq) | NOT NULL + FK | ON DELETE CASCADE | 子項在父項內唯一 |
| 引用關係 | 獨立主鍵 | FK (可 NULL) | NO ACTION / RESTRICT | 全域唯一 |
| 成員關係 | 中介表雙 FK | 雙向 FK | SET NULL | 組合唯一 |
第三層:實作層(Physical Layer)
核心問題: 如何在效能與一致性間取得平衡?
針對 效能需求 選擇實作策略
在一致性與效能間做 權衡
考慮索引、分片、快取等技術手段
| 策略 | 適用場景 | 優勢 | 代價 |
| 標準 JOIN | 中等規模、高一致性需求 | 即時、準確 | 跨表查詢成本 |
| 反正規化 | 讀多寫少、可接受最終一致 | 單表查詢快 | 更新複雜、儲存冗餘 |
| 物化視圖 | 複雜聚合、定期刷新可接受 | 查詢極快 | 刷新延遲、儲存倍增 |
| 應用層 JOIN | 分片環境、微服務架構 | 靈活路由 | 網路往返、程式複雜 |
| 事件溯源 | 高變更頻率、需完整歷史 | 可重放、審計完整 | 查詢需重建狀態 |
「包含語意」判斷框架
快速評估表(7 個維度)
| 維度 | 組成關係 (Composition) | 引用關係 (Reference) |
| 獨立價值 | 子項無獨立商業意義 | 被引用方有獨立價值 |
| 生命週期 | 與父項同生共死 | 獨立的創建/銷毀 |
| 權限繼承 | 繼承父項權限 | 有自己的權限體系 |
| 數量特性 | 可預期上限(1-100s) | 可能無上限或極大 |
| 共享性 | 專屬於單一父項 | 可被多方引用 |
| 查詢模式 | 通常與父項一起查詢(跟第一點一樣意思) | 經常獨立查詢 |
| 一致性要求 | 強一致性 | 可接受最終一致 |
判斷結果 → 設計策略
| 評估結果 | 推薦策略 | 實作要點 |
| 5+ 個「組成」特徵 | 聚合根設計 | 複合主鍵、級聯刪除、事務邊界 |
| 3-4 個「組成」特徵 | 強外鍵約束 | NOT NULL FK、部分級聯 |
| 2 個以下「組成」特徵 | 引用設計 | 獨立主鍵、軟約束、可 NULL |
RDBMS 中的「包含」表達手法
常見實作:
父表 + 子表(FK NOT NULL + ON DELETE CASCADE)
子表複合主鍵 (parent_id, line_no) 強化「從屬」語意
有些小且穩定的子集合(例如 User 的設定集)可用 JSON/ARRAY 欄位(減少 JOIN)
視圖 / 物化視圖 將常用父子聚合預先展開(讀快、寫複雜)
NoSQL(以Document DB為例)對應模型
| 建模方式 | 語意 | 優點 | 風險 |
| 嵌入 (Embed) | 強組成、一起讀 | 單查取整體、少網路往返、單文件原子性 | 子集合無上限會膨脹;部分更新成本高;熱點文件鎖 |
| 參考 (Reference) | 弱關聯 / 重用 | 文件小、子項可獨立成長 | 需要多次 round-trip 或應用層 Join;一致性自己管 |
| 預先展開 (Denormalize Copy) | 為讀優化 | 查詢快 | 重複數據同步難 |
| 預計算 / 物化文件 | 聚合快取 | 讀非常快 | 延遲一致 / 重建流程必要 |
MongoDB 有 $lookup 但非傳統 cost-based optimizer;Cassandra 無 JOIN(需建反向查詢表)。
何時在 NoSQL「嵌入」 vs 「引用」
嵌入 (Embed) 適用:
子項集合大小「小且有上限」(例如 <= 50 或數百內)
讀操作幾乎總是「父 + 全部子」一起要
子項更新頻率低或批次
需要單文件原子性
不會被多個父共享
無需跨子項複雜查詢(例如不單獨以子項條件大範圍搜尋)
引用 (Reference) 適用:
子集合「可能無上限」或高速成長(留言、日誌)
子項要被多個父使用或交叉分析
子項更新頻率高 / 局部更新為主
需要基於子項條件分頁、排序、統計
權限或壽命不完全跟父同步
需要避免文件熱點(高併發寫同一父)
常見錯誤對應
| 誤解 | 風險 | 建議 |
| 看到「包含」就一律在 RDBMS 拆表 | 過多 JOIN、過早複雜化 | 子集合小且不查詢可考慮 JSON |
| NoSQL 一律嵌入 | 文件爆炸、熱點寫鎖 | 監控文件大小/寫頻率,必要拆 |
| 以為引用 + 應用層 join 等同 RDBMS JOIN 成本 | 多 round-trip 延遲高 | 用批量查詢 / pipeline / 預計算 |
| 任意反正規化未設同步策略 | 資料漂移不一致 | 有來源版本號 / 重建流程 |
| Mongo $lookup 當成 RDBMS JOIN 大量使用 | 性能不可預期 | 控制資料量,適度寫入時展開 |
但除了正規化避免冗餘,還常因為它們屬於不同的業務主題(Domain / Subject)或擁有不同的更新頻率、保存期限、合規要求與存取模式;當某個使用場景需要把這些原本獨立演化的資料拼在一起時,就需要 JOIN。
為什麼「不同主題 / 生命週期」會驅動分表?
| 拆分驅動因素 | 說明 | 常見做法 | 影響 JOIN 需求 |
| 主題邊界(Domain Boundary) | User、Order、Payment、Inventory 各自業務語意 | 按領域建獨立表(甚至獨立 schema) | 報表或聚合時跨域 JOIN |
| 更新頻率(Update Velocity) | Profile 更新少;交易流水高頻 | 熱表與冷表分離 | 查詢展示時再 JOIN |
| 生命週期 / 保存期限(Retention) | 訂單主檔保留 7 年;暫存計算只要 30 天 | 歷史表(history/archive) | 需要歷史 + 現況視圖時 JOIN 或 UNION |
| 安全 / 權限(Security Classification) | PII 與一般行為資料分離 | 敏感表設更嚴 ACL | 需遮罩或脫敏後再 JOIN |
| 存取模式(Access Pattern) | OrderItems 高寫入、Product 靜態 | 針對高寫入表獨立調優 | 下單詳情頁面 JOIN |
| 資料粒度(Granularity) | Fact(交易事實) vs Dimension(維度) | 星狀/雪花模型 | OLAP 查詢多 JOIN |
| 資料版本 / 緩變(Slowly Changing Dimension, SCD) | 需要保留歷史屬性 | 維度表多版本(Type 2) | 回放歷史分析需依時間 JOIN |
| 擴展 / 分片策略 | 不同表按不同 key 分片 | 垂直分片 + 水平分片 | 跨分片 JOIN 成本升高 |
為什麼要「應用層 / 資料層」分離?
| 面向 | 分離前(單機) | 分離後(雙層) | 好處 |
| 資源競爭 | App 與 DB 搶 CPU / RAM / I/O | 各自獨立 | 效能穩定 |
| 擴展模式 | 垂直擴充為主(易到頂) | App 可水平加機,DB 可做複寫/調優 | 成本更彈性 |
| 可靠性 | 一崩全崩 | 單層故障影響範圍縮小 | 可用性提升 |
| 部署風險 | 部署 App 可能拖累 DB | App 可頻繁部署,DB 較少改動 | DevOps 友善 |
| 監控精度 | 難拆指標 | 分 tiers 監控 (QPS, Slow Query, CPU) | 除錯快 |
這一步是系統走向 Layered Architecture 的第一個拆分,也是之後能加快取、CDN、讀寫分離、分片的基石。
垂直擴充(Vertical Scaling)與水平擴充(Horizontal Scaling)
垂直擴充(又稱 Scale Up)是指替現有伺服器增加更多資源(例如 CPU、記憶體等)。在流量較低的階段,垂直擴充是一個很好的選擇,其最大優點是簡單(不需修改架構、部署流程;常只是調整雲端實例規格。)。但它也存在嚴重的限制。
垂直擴充存在硬體上限——不可能無限制地為單一伺服器添加 CPU 與記憶體。
垂直擴充本身不提供容錯與冗餘能力;若唯一的伺服器故障,整個網站/應用會完全無法服務(會有Single point of failure問題)。
So…在業務有賺錢且請求數才 C10K 上下時,其實垂直擴充還是很不錯的解決方案的。
水平擴充(又稱 Scale Out)則是透過新增多台伺服器進入資源池來提升整體處理能力。在更大請求數的系統中,水平擴充往往是更可取的方案。又因為有多台伺服器所以水平擴充方案通常會導入負載平衡器(Load Balancer)是最合適的技術手段。
負載平衡器(Load Balancer)
負載平衡器會將進入的流量平均(或依特定演算法)分配到設定於「負載平衡伺服器組」中的多台 Web 伺服器。如下圖所示。
使用者直接連到負載平衡器的 Public IP。採用這種架構後,外部用戶無法再直接存取後端 Web 伺服器。為了提升安全性,伺服器之間的通訊方式改用 Private IP。所謂Private IP,是只能在同一網路(例如同一 VPC / 子網)內互相存取的IP address,無法透過公開網際網路被直接訪問。

Load Balnacer 常見的負載平均策略
服務方的服務發現(Server Side Discovery)
根據地理位置導流量去不同 Region 的服務

資料庫複寫機制
剛剛提到水平擴展是請求量較大的系統場景時較好的技術方案。又因為大多數場景資料的讀寫比例差異也不小,幾乎都是讀取資料的次數跟筆數遠比寫入修改的高。
因此我們就想著能否將資料庫讀取資料的請求與寫入修改的請求分開,因此有了複寫機制這架構,在這架構中最主要的兩個角色分別是 Primary/Main(資料來源)以及 Replica(資料副本)。

資料庫複寫架構的優點:
效能提升:在複寫模型中,寫入與更新集中於主節點,而讀取請求分散到各從節點,達到並行處理更多查詢的效果。
資料可靠性:若某一資料庫伺服器遭受天災(如颱風、地震)損毀,資料仍保存在其他節點,不致遺失,因為複寫將資料散佈在多個位置(能想成 Git server 與自己local的 Git 副本)。
高可用性:資料跨節點複寫後,即使其中一台資料庫離線,系統仍可向其他節點存取相同資料,服務不致中斷(目前此架構僅針對讀取場景具備高可用性)。
! 提出問題 !
若系統只有一台 Replica 資料庫而它離線了,此時 client 發出的讀取請求你會怎處理?
若主資料庫離線呢?
引入 Cache 機制
Cache 的目的將「計算代價高」或「被頻繁存取」的資料結果存放於記憶體,使後續請求能更快回應。每次網頁載入時,通常會觸發一次或多次資料庫查詢(例如取得遊戲排行榜、後台列表清單、取得企業用戶的昨日報表等),反覆打資料庫會顯著影響效能,而快取可減輕此問題。

Caching Strategies
被動式 vs 主動式
被動式︰都是在讀取階段才判斷。
主動示︰資料寫入修改階段跟著作動。
- Cache Aside(最常見)
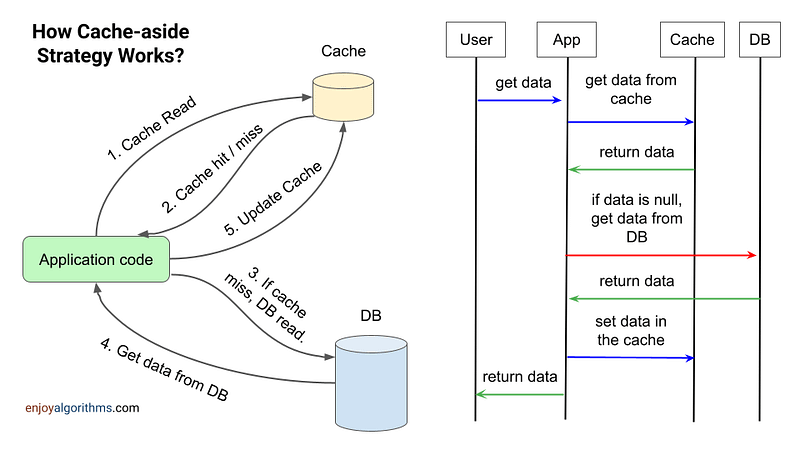
Read through
令一個是 Write through,有 through 的都是 application 只認識一個端點,由該服務來執行跟資料庫中間的同步。
- Write Around(小弟個人比較常搭配這個)
使用 Cache 的一些提醒事項
適用於「讀多、改少」的資料。
Cache 存於Memory,重啟即失,並不適合作為最終持久層。因此關鍵資料必須寫入永久性儲存(如資料庫、物件儲存)。
應設定到期時間。沒有過期機制會導致記憶體永遠被占用。
TTL 太短 → 頻繁回源查 DB
TTL 太長 → 資料可能陳舊失真。需依一致性與負載取平衡。
資料一致性問題,需維持主資料存放(DB)與快取同步。由於更新快取與更新資料庫通常非同一原子交易,可能產生不一致。多區域部署時(跨資料中心)一致性更難
淘汰(Eviction)策略:當快取已滿,新加入資料會觸發舊資料被移除,稱為「快取淘汰」。最常見策略為 LRU(最近最少使用)。其他如 LFU(最少使用頻率)、FIFO(先進先出)等,可依使用情境選擇。
故障緩解:單一快取伺服器可能成為單點故障(SPOF)。建議多台、甚至跨資料中心部署以避免全失。另可超額配置記憶體(預留成長緩衝),降低突增導致的淘汰壓力。
CDN
CDN(內容傳遞網路)是由地理上分散的伺服器所組成,用來加速傳送靜態內容。CDN 節點會快取圖片、影片、CSS、JavaScript 等靜態資源。
使用者造訪網站時,離他最近的 CDN 節點提供靜態資源。直覺上,使用者距離 CDN 節點越遠,載入越慢。例如節點在舊金山,洛杉磯使用者會比歐洲使用者獲得更快回應。

使用 CDN 的常見注意事項
成本:CDN 由第三方營運,需付出外送/回源流量費。快取極少被用的資源效益低,可移出 CDN。
適當快取到期(TTL):對時效性內容要設定適當期限,過長會陳舊,過短會頻繁回源。
失效(Invalidate)檔案:可在到期前移除或更新:
透過 CDN API 主動失效(Purge/Invalidate)。主動刪除
Client(需要調整 Client) 透過物件版本化(URL 增加版本參數,如 image.png?v=2)
CDN Fallback:當 CDN 發生暫時性故障(例如整個網域解析不到、邊緣節點異常、TLS 失敗、連線超時),你的網站或應用不應立即「崩潰」或讓使用者卡住,而是應該能進行切換,或者直接到 Origin server。
Stateful vs Stateless
之前都是考慮資料層的分層、擴容。但 Web/API Server ,一些應用服務 呢?
如果我們想把 Web/API server 做水平擴充。要達成這點,必須把狀態(例如:使用者 Session 資料)移出 Web 層。好的做法是把 Session 資料(常見的狀態之一)存放在持久化或共享型儲存(例如:關聯式資料庫或 NoSQL)。叢集中的每一台 Web 伺服器都能從該資料庫存取狀態資料。這種設計稱為「stateless Web 層 (stateless web tier)」。

問題在於:同一個客戶端的每次請求都必須導向同一台伺服器。多數負載平衡器可以透過「 Session (sticky sessions)」達成,但這會帶來額外開銷。以這種方式擴充或縮減伺服器更困難,也較難處理伺服器故障。
討論︰為什麼stateful server 我們即使擴充或縮減伺服器,書上也是說困難?
下圖是採用無狀態 Web 層後的更新設計。在這種 stateless 架構中,使用者的 HTTP 請求可以被送往任意 Web 伺服器;這些伺服器會到共享資料儲存取回狀態。狀態資料放在共享儲存(該儲存可以是RDBMS、Memcached / Redis、或 NoSQL 等。)中,而不是留在 Web 伺服器。stateless 系統更簡單、更穩健且易於擴充(僅限於方便擴充 Web server)。

「狀態」是什麼?
在這裡的狀態指的是:
為了正確處理使用者接下來的請求,某台特定伺服器必須保存在自己本地(記憶體/本地檔案/連線)的資料或上下文。
只要「下一個請求必須回到同一台伺服器才能正常運作」,那份資料就是造成有狀態的因素。
簡化判別句:
如果我把這台 Web 機器砍掉重建,使用者的體驗或流程會不會壞?會 → 那些就是『狀態』。
狀態常見分類
| 類型 | 說明 | 是否常見造成黏著 |
| 使用者身份 / 認證狀態 | Session、登入 token、權限上下文 | 是 |
| 使用者互動流程進度 | 多步驟表單進度、購物車、結帳流程 | 是 |
| 使用者偏好 / UI 狀態 | 語系、佈局模式、A/B variant | 若存在伺服器本地就會 |
| 暫存的業務資料 | 尚未提交的草稿、臨時計算結果、購物車:若存放在某機器記憶體,請求換機器就消失、股票撮合服務 Orderbook 上掛的買賣單 | 是 |
| Cache | 本機計算結果 / 熱資料 | 一般屬「軟狀態」,但設計不當會依賴 |
| 檔案暫存 | 上傳中碎片、影像處理中間檔案 | 是 |
| 連線層狀態 | WebSocket 連接對應的使用者、推播訂閱 | 是(如綁在單機記憶體) |
| 排程 / 工作佇列內記錄 | In-memory job queue / delayed tasks、背景批次 Job 進度 | 是 |
| Rate limiting / 計數器 | 以記憶體紀錄使用者請求數 Map<IP, counter>。 | 是(各機不一致導致錯誤限制) |
| 防重 / Idempotency 狀態 | 保存在單機的紀錄是否已處理某訂單/交易 | 是(若僅存在本機) |
| Feature Flag 解析結果 | 每個使用者被分派的組別 | 是(若本機才知) |
| TLS / 加密交握 / session ticket | 傳輸層協商(通常由 LB 處理) | 通常不視為應用黏著 |
| ML 推論上下文 | 使用者個別暫存特徵向量 | 可能 |
「軟狀態 vs 硬狀態」
| 類別 | 定義 | 失去後影響 | 例子 |
| 硬狀態 (Authoritative) | 系統必須正確保存 | 遺失 = 資料錯誤/使用者體驗壞 | Session、交易紀錄、購物車 |
| 軟狀態 (Reconstructable) | 可以重新計算或重抓 | 遺失 = 暫時變慢 / 重新生成 | Cache、預算好的推薦結果 |
建議:
硬狀態永遠不要只放在單機記憶體。
軟狀態可放本機:但要接受可隨時清空 (cache invalidation OK)。
什麼情況「不必過度追求完全無狀態」?
| 條件 | 可接受局部本地狀態 |
| 早期原型、單節點 | 快速迭代比彈性更重要 |
| 本地緩存的這些資料不是系統的「authoritative source」,而是從別地方的資料加工、計算、查詢、組合後得到的暫存結果。 | 清掉僅造成效能下降 |
| 臨時開發工具介面 | 非生產流量 |
Message Queue
Message Queue 是一種支援非同步通訊的「具備持久性(durable)」元件,同時以記憶體為基礎進行暫存。它扮演 buffer 的角色(消峰),分散並傳遞非同步請求。
其基本架構相當簡潔:輸入端服務(稱為 Producer / Publisher)產生訊息並發佈到佇列;其他服務或伺服器(稱為 Consumer / Subscriber)連接到佇列,依訊息所定義的內容執行對應動作。

「解耦(Decoupling)」特性使訊息佇列成為構建可擴展且可靠應用的常用架構。使用訊息佇列時,當消費者暫時無法處理請求,生產者仍然可以把訊息送進佇列;反之,即使生產者暫時離線,消費者仍能從佇列中取出既有訊息處理。Decoupling 白話的說,生產者不必管有沒有消費者,也不用管消費者是誰。消費者也是如此。
資料庫的擴展
最簡單的是垂直擴展(Vertical Scaling),前面講過了不再提。
而資料庫也有水平擴展(Horizontal Scaling),又稱「分片(Sharding)」,是透過新增更多伺服器來擴充。分片是把大型資料庫切成較小且更易管理的單元(稱為「分片」)。各分片共享相同 Schema,但存放的實際資料互不重複。
圖示範一個分片資料庫:使用者資料依使用者 ID 分配到不同伺服器。每次存取資料都會用雜湊函式尋找對應分片。本例採用 user_id%4 作為hash:結果為 0 則用 shard 0;為 1 則 shard 1;其餘類推。
實作分片策略時最重要的考量是「分片鍵」(Sharding Key,又稱 Partition Key)。分片鍵由一或多個欄位組成,決定資料如何分佈。良好的分片鍵可讓查詢正確路由到對應資料庫以有效存取。關鍵準則之一是能「均勻分散」資料(避免 hot spot)。

Sharding 是有效擴展資料庫的技術,但並非完美,會引入新的複雜度與挑戰:
資料再分片(Resharding):在以下情況需要:1) 單一分片因成長過快已放不下。2) 資料分佈不均造成部分分片較快「耗盡」(容量或效能)。此時須更新分片函式並搬遷資料。第 5 章將提到的一致性雜湊(Consistent Hashing)是常用解法。
名人問題(Celebrity Problem / Hotspot Key):過多請求集中於特定分片導致過載。若多位超高人氣帳號落在同一分片,其讀取壓力會壓垮伺服器。可能需為每位名人單獨配置分片,甚至再細分。
Join 與去正規化:跨分片進行 Join 困難,常見替代作法是「去正規化」,讓查詢可在單表完成。
Sharding 架構下的 JOIN 挑戰
挑戰分類
| 挑戰類型 | 具體問題 | 影響程度 |
| 跨分片 JOIN | 資料分散在不同物理節點 | 高:需網路聚合 |
| 分片鍵不一致 | 關聯表用不同分片策略 | 極高:可能全掃描 |
| 聚合計算 | SUM、COUNT 需跨分片合併 | 中:可並行處理 |
| 排序分頁 | ORDER BY + LIMIT 跨分片複雜 | 高:需全域排序 |
解法對照
| 解法 | 適用場景 | 實作複雜度 | 效能影響 |
| 應用層 JOIN | 簡單關聯、可控資料量 | 中 | 多次網路往返 |
| 分片鍵對齊 | 強關聯實體(如 User-Order) | 低 | 可能分佈不均 |
| 反正規化 | 讀多寫少、可接受冗餘 | 高(同步機制) | 讀快寫慢 |
| CQRS 分離 | 複雜查詢 vs 簡單寫入 | 高 | 查詢極快 |
| 搜尋引擎 | 全文檢索、複雜篩選 | 中 | 近即時延遲 |
| 資料倉儲 | 分析型查詢、歷史資料 | 中 | 批次延遲 |
實務案例分析
案例 1:電商訂單系統
| 實體關係 | 語意判斷 | 設計決策 | 理由 |
| Order ← OrderItem | 組成關係 | 複合主鍵 (order_id, line_no) | OrderItem 無獨立意義 |
| Order → User | 引用關係 | 獨立 FK,不級聯 | User 有獨立生命週期 |
| Order → Product | 引用關係 | FK + 快照欄位 | Product 可能變更,需歷史記錄 |
案例 2:社交媒體平台
| 實體關係 | 語意判斷 | 設計決策 | 理由 |
| Post ← Comment | 組成關係 | FK + 級聯刪除 | Comment 依附於 Post |
| Post → User | 引用關係 | FK,不級聯 | User 獨立存在 |
| User ↔ User (Follow) | 成員關係 | 中介表 follows | 多對多關係 |
案例 3:分片環境挑戰
| 場景 | 問題 | 解法 | 權衡 |
| 跨用戶統計 | 無法按 user_id 分片 | 定期 ETL 到分析庫 | 延遲 vs 效能 |
| 商品搜尋 | 商品與訂單不同分片策略 | Elasticsearch 同步 | 一致性 vs 查詢能力 |
| 實時推薦 | 需要用戶行為 + 商品資訊 | Redis 快取 + 應用層合併 | 記憶體成本 vs 延遲 |
監控與優化指標
| 層面 | 關鍵指標 | 告警閾值建議 | 優化方向 |
| JOIN 效能 | 查詢執行時間、掃描行數 | P95 > 500ms | 索引優化、查詢重寫 |
| 跨分片成本 | 網路往返次數、資料傳輸量 | 單查詢 >3 次往返 | 批次查詢、快取 |
| 一致性延遲 | 反正規化同步延遲 | \>10 秒 | 事件驅動、並行處理 |
| 快取命中率 | JOIN 結果快取效率 | <80% | 快取策略調整 |
總結
架構演進路線
| 場景特徵 | 推薦方案 | 關鍵考量 |
| QPS < 1K, 資料 < 1GB | 單機 | 簡單優先 |
| QPS 1K-10K, 讀多寫少 | 讀寫分離 + 快取 | 成本效益 |
| QPS > 10K, 多地域 | CDN + 分片 | 延遲與一致性 |
// 使用 pg_database_size() 看資料庫的資料大小
SELECT
datname as database_name,
pg_size_pretty(pg_database_size(datname)) as size
FROM pg_database
WHERE datname = 'your_database_name';
要怎知道讀多寫少? 或者啟用 Metrics 做監控。
-- 查看資料庫整體讀寫統計
SELECT
datname as database_name,
tup_returned as total_reads, -- 總讀取行數
tup_fetched as fetched_reads, -- 實際取得行數
tup_inserted as total_inserts, -- 總插入行數
tup_updated as total_updates, -- 總更新行數
tup_deleted as total_deletes, -- 總刪除行數
(tup_inserted + tup_updated + tup_deleted) as total_writes,
CASE
WHEN (tup_inserted + tup_updated + tup_deleted) = 0 THEN 'READ_ONLY'
ELSE ROUND(
tup_returned::numeric /
(tup_inserted + tup_updated + tup_deleted)::numeric,
2
)
END as read_write_ratio
FROM pg_stat_database
WHERE datname = current_database();




