

Day 1 系統可觀測性信號的下一步 - Profile 性能剖析

Day 1 系統可觀測性信號的下一步 - Profile 性能剖析
前幾年我們在分享關於系統可觀測性,幾乎著重在基本的三種信號類型(Logs、Metrics、Traces)。還有一種信號類型有時候會被需要,就是 Profile 性能剖析。
絕大部分工程師日常開發流程可能是開發程式 -> 紀錄事件 log -> 框架埋點監測指標與追蹤,然後佈署至具有 scalability 能力的測試環境中進行工作負載測試。這樣的流程之下,等工作負載測試發現性能問題時,只能通過基本信號來推敲性能問題。針對系統性能是有一門領域稱為系統性能工程(Performance engineering)在討論。
[iT 邦鐵人賽系列連結](https://ithelp.ithome.com.tw/users/20104930/ironman/7138)
系統性能工程
性能工程包含在系統開發生命週期中應用的技術,以確保性能的非功能需求(如吞吐量、延遲或記憶體/CPU 使用量)能夠滿足。這個術語也可能被稱為系統性能工程(在系統工程中),以及軟體性能工程或應用性能工程(在軟體工程中)。
隨著應用程序成功和業務成功之間的聯繫不斷增強,特別是在移動端領域,應用性能工程在軟體開發生命週期中已經承擔了預防性和完善性的角色。因此,這個術語通常用來描述有效測試非功能需求、確保服務水平的遵守並在部署前優化應用性能所需的流程、人員和技術。
性能工程不僅僅涉及軟體和支持基礎設施,因此從宏觀角度看,性能工程這個術語更為合適。在部署後,通過監控生產系統來驗證非功能需求的遵守,這是 IT 服務管理的一部分(參見 ITIL)。
性能工程已經成為許多大公司中的一個獨立學科,其任務與系統工程平行但獨立存在。它具有普遍性,涉及來自多個組織單位的人員,主要在資訊技術組織內部。
性能工程目標
通過確保系統能在所需時間內處理請求來增加業務收入
消除由於性能目標失敗而需要報廢和撇帳的系統開發工作
消除由於性能問題導致的系統延遲部署
消除由於性能問題引起的可避免的系統返工
消除可避免的系統調優工作
避免額外和不必要的硬體採購成本
減少由於營運環境中的性能問題而導致的軟體維護成本增加
減少由於即興性能修復對軟體的影響而導致的軟體維護成本增加
減少由於性能問題而處理系統問題的額外運營開銷
通過原型模擬識別未來瓶頸
增加伺服器能力
性能工程方法
由於這一學科應用於多種方法論,因此以下活動將發生在不同的指定階段。但是,如果使用合理統一過程(RUP)階段作為框架,則活動將按以下方式進行:
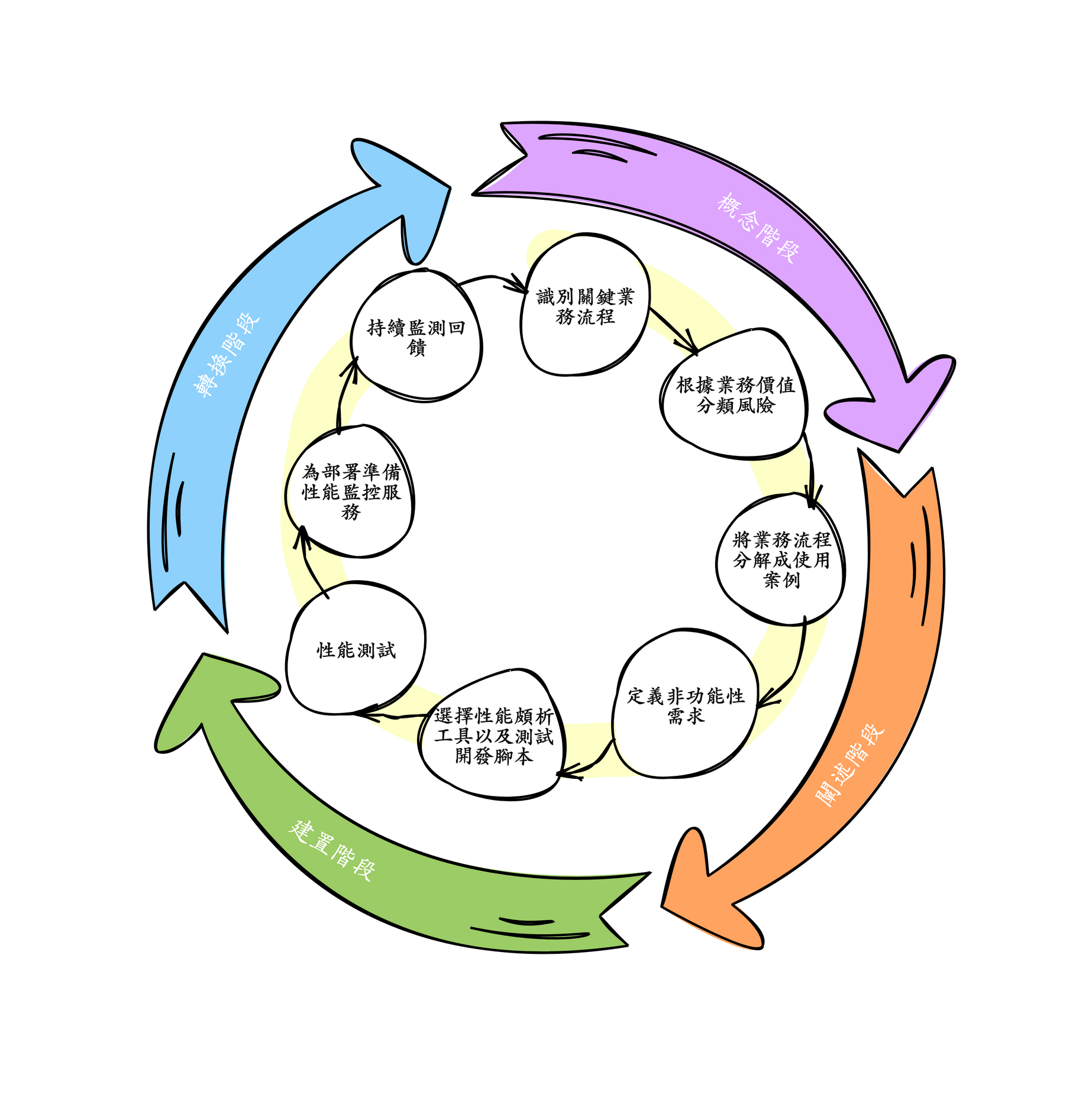
概念階段(Concept Phase)
識別關鍵業務流程:根據業務價值分類,由業務單位進行。DDD 的 EventStorming 與 Domain StoryTelling 在這階段是個很好的工作坊形式,能與業務單位合作一起完成。
識別高風險:描述可能影響系統性能的風險。
制定計劃:為後續階段制定性能活動、角色和交付物的計劃。
闡述階段(Elaboration Phase)
分解業務流程:將關鍵業務流程分解為使用案例。
定義非功能需求(NFR):與性能相關的非功能需求涉及業務操作在特定條件下的執行速度。
建置階段(Construction Phase)
選擇性能剖析工具:為開發和測試環境選擇剖析工具、自動化單元測試工具、伺服器端測試工具和多用戶腳本驅動工具。
部署和培訓:部署性能工具並為開發團隊提供培訓。
性能測試:在接近營運環境的預部署環境中進行性能測試,驗證使用案例是否符合非功能需求,並進行負載和壓力測試。
轉換階段 (Transition Phase)
部署準備:配置操作系統、網絡、伺服器和性能監控軟體。
持續運營:部署後,進行每週和每月的性能報告,識別和提交不符合 NFR 的使用案例,並進行容量規劃管理。
以上只是 Wiki 的內容翻譯成中文而已 XD
從這性能工程方法的各階段描述能理解到也是一種測試概念,將這類測試左移至系統分析與設計階段就開始規劃,並且於開發整合環境就能測試,在之後各環境也是能持續地測試取得回饋。
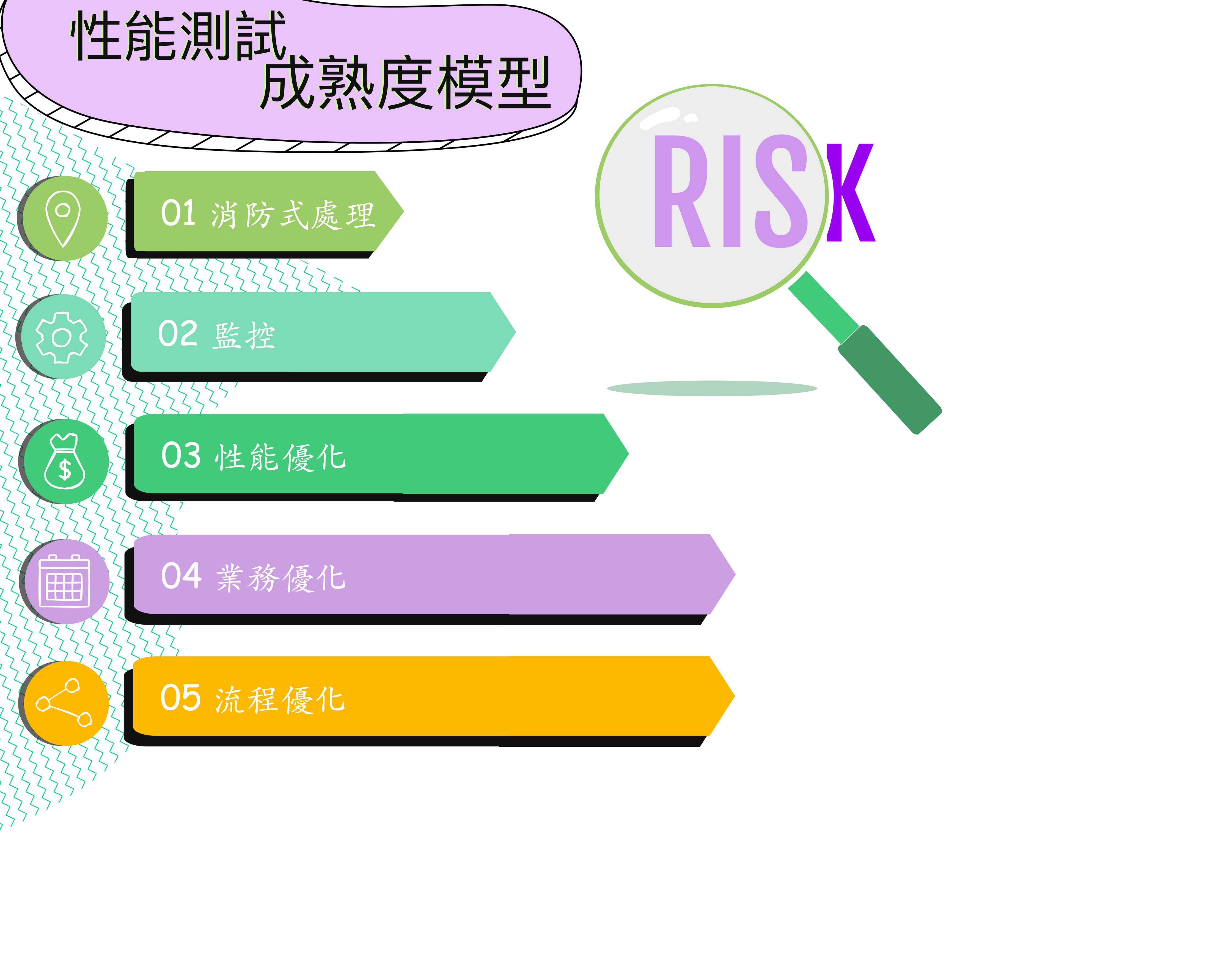
當團隊開始將這樣的工程方法引入在團隊的開發流程中時,其實也像可觀測性工程的 ODD(可觀測性驅動開發)中也有個 OMM(可觀測性成熟度模型),這裡也有 Performance Process Maturity Model (性能測試成熟度模型)。
性能測試成熟度模型
性能測試成熟度模型包含五個等級,從1到5。這些等級具有以下共同特徵:
可累積性: 性能成熟度等級具有可累積性,這意味著在較低等級中應用的性能活動和流程在較高等級中被保留並增強。這種可累積性確保了在提升成熟度等級的過程中,已有的知識和實踐不會丟失,而是作為基礎進一步發展和優化。
例如: 等級1:僅進行基本的故障排除和應急修復。 等級2:在等級1的基礎上,增加了持續監控和數據收集。 等級3:在等級2的基礎上,整合了性能優化工具和方法,並將性能考慮融入開發過程。 等級4:在等級3的基礎上,強化了對業務效能的理解,並考慮系統變更對業務生產力的影響。 等級5:在等級4的基礎上,進一步延伸到整個企業的流程優化,全面檢視成本和利潤可能性。 這樣的累積性確保了每個等級的進步都建立在前一等級的基礎上,使整個流程變得更加穩健和高效。
不同應用的差異性: 不同的應用程序可能在性能成熟度等級上表現出差異。這是由於各個應用程序的需求、開發過程和運行環境不同所致。然而,相同的企業或部門文化會使大多數系統表現出類似的成熟度等級。這意味著,雖然單個應用程序可能處於不同的成熟度等級,但整體企業文化和方法論會影響這些應用程序,使其在性能成熟度上趨於一致。
例如:
某些應用可能在性能監控方面做得很好(等級2),但在性能優化和容量規劃方面仍需改進(等級3)。 另一個應用程序可能已經將性能考慮融入了開發過程(等級3),但尚未全面理解和優化業務效能(等級4)。 企業或部門文化的統一性有助於推動所有應用程序朝著更高的性能成熟度等級邁進,形成一致的流程和標準。
學習和反饋: 在性能成熟度的提升過程中,學習和反饋是關鍵。隨著工作的進展,組織會應用不同程度的學習和反饋機制,以提高性能和優化流程。較高等級的組織更傾向於使用有效且具有戰略性的反饋方法。
例如:
等級1:主要依賴於個別事件的反應,缺乏系統性的學習和反饋。 等級2:開始定期收集性能數據,並根據這些數據進行基礎的性能調整。 等級3:將性能評估和規劃融入開發過程,開發團隊和性能工作者持續交流和反饋。 等級4:基於用戶生產力和業務效能的數據進行深入分析和優化,建立更具戰略性的反饋機制。 等級5:企業高層全面理解並推動性能和流程優化,形成自上而下的學習和反饋文化。 這種學習和反饋機制確保了組織能夠持續改進和優化,並在面對新的挑戰時具備更強的應對能力。
成熟度等級 1:消防式處理
在等級1,開發人員在創建系統時對操作考慮(包括性能)缺乏意識。他們所得到的需求僅指定最基本的性能需求(如果有的話)。如果在試點或早期部署中暴露出性能問題,則通過「調優」來解決,即對程式邏輯進行小幅調整,只能帶來增量改善。系統交付生產後,實際上是「扔過牆」。
伺服器可能在對其大小缺乏理解或定量科學的情況下指定、購買和安裝,導致意外停機,隨後進行緊急(昂貴)的升級或更換,甚至需要重新開發應用。由於應用過慢而需要返工的成本很高(包括超支),並且會導致顯著的延遲。用戶群體或應用集的變化對操作人員來說是驚喜,導致停機或極差的性能。
主要重點在於故障排除和反應模式,這主要在操作領域。一個缺乏性能專業知識的支持團隊成員可能會被指派「快速運行一個 PerfMon」或使用其他臨時工具進行檢查。每次新危機都會產生另一個特別研究,並可能從中獲得一些預防措施,但很少試圖產生戰略價值或計劃長期穩定的流程。
管理層對系統性能如何促進企業成功的理解很少,只知道停機(極端性能差)會花費金錢。性能在這個成熟度等級是黑暗藝術。
成熟度等級 2:監控
在等級2,一個性能工作者設置了一些自動化水平,從營運系統中收集性能數據,理想情況下是24x7。系統地處理超出既定閾值的資源測量(如 CPU 使用率、I/O 頻寬、內存可用性或磁盤空間)的努力有所增加。性能工作者可能會定期發布報告,但管理層可能仍然認為這些數據及其意義超出了他們的興趣或專業範疇。
接受監控的系統至少在某種程度上已被合理化,考慮到用戶數量和由此產生的停機和響應不良成本。應用系統在部署前仍然受到很少的性能審查,因此用戶群體或系統負載的意外水平仍然會破壞響應時間和穩定性。修復或防止性能缺陷的努力可能僅限於操作系統(OS)或硬件配置調整、系統軟體更新等。
性能工作者可能使用一個打包的監控系統,如 BMC Patrol Perform 或 Heroix eQ Management Suite。或者,性能工作者可能從免費組件中組裝一個系統,由腳本和操作系統級別的任務調度鏈接起來。監控系統可能會捕捉關鍵的超出閾值的測量。警報有兩種可能的級別:
近乎實時,為操作支持團隊提供解決異常所需的信息。
批量,提供更具戰略性或戰術性的支持。
成熟度等級 3:性能優化
在等級3,性能評估和規劃融入了開發過程。開發人員和性能工作者使用全套方法和工具來解決性能需求。例如:
軟體性能工程(SPE)模型從設計階段開始就預測系統響應和資源競爭,隨著設計和實施的細節逐漸清晰,SPE 模型也會進行調整和完善。
回應時間預算將複雜或多層應用程序的時間分解,以建立內部處理時間限制,並在專案早期確立和隨著組件的開發進行完善。
IDE 型剖析器評估執行路徑和路徑長度,開發人員使用計算機輔助軟體工程(CASE)工具或 SQL 伺服器分析路徑長度、I/O 計數和其他性能行為。
專門的主機工具檢查應用程序性能行為,I/O 追蹤實用程序捕捉輸入/輸出模式和計時,操作系統特定工具從測試運行中捕獲廣泛的性能測量。
應用程序響應測量(ARM)API 用於捕捉應用程序在執行中的響應時間。監控系統支持 ARM API,收集並分析這些響應時間數據。這些數據可用於以下目的:
系統響應性的直接測量: 通過 ARM API 捕捉應用程序的響應時間,可以直接測量系統在處理請求時的響應速度。
到達率分析: 分析請求到達系統的頻率和模式,以便了解系統在不同負載情況下的表現。
體積分析: 分析系統處理的請求數量,幫助確定系統在高負載情況下的容量需求。
趨勢分析: 通過長期收集響應時間數據,可以分析系統性能的趨勢,預測未來的性能瓶頸和資源需求。
成熟度等級 4:業務優化
在等級4,系統對業務有效性的貢獻得到了更充分的理解,尤其是在以下方面:
用戶生產力對應用程序的理解,如通話時長、每小時的電話營銷銷售等。
系統的業務價值—不僅僅是對用戶生產力的好處—被充分理解。
對系統變更的提議進行徹底評估,以了解其對用戶生產力和資源利用的影響。
系統響應性、用戶生產力、硬件投資和系統壽命之間的權衡被充分理解和合理化。
這一階段需要廣泛協調的技能,包括性能、人為因素、管理和系統分析領域。企業目標對所有人都是可見的,並形成衡量設計和性能決策的標尺。
成熟度等級 5:流程優化
在等級5,管理層完全理解性能和流程優化的好處,重點是進一步擴展這些好處:
仔細檢查與計算機系統相關的成本與利潤可能性。
對每個潛在優化的好處與實現該優化的成本進行理性化,例如,考慮投資回報率(ROI)。
這一成熟度等級幾乎完全採用管理科學,但不忽視系統性能的潛在貢獻,從 I/O 到資產負債表進行徹底檢查。流程文化確保所有人都能看到企業目標,並將他們的努力與流程效能對照。企業架構已被合理化,應用程序系統及其上的業務系統的性能優化已經實現並持續改進。
在 Thoughtworks 今年也有一篇關於性能工程成熟度模型的文章,分享給各位閱讀。
小結
總結來說,性能測試成熟度模型為企業提供了一個系統化的框架,使其能夠逐步提升性能測試和優化實踐。這不僅提高了單個應用程序的性能,還推動整個企業的性能文化,最終實現業務效能的全面提升。這一模型的價值在於它提供了一條清晰的路徑,幫助企業在日益複雜和動態的技術環境中保持競爭力和可持續發展。




