

Loki Ruler

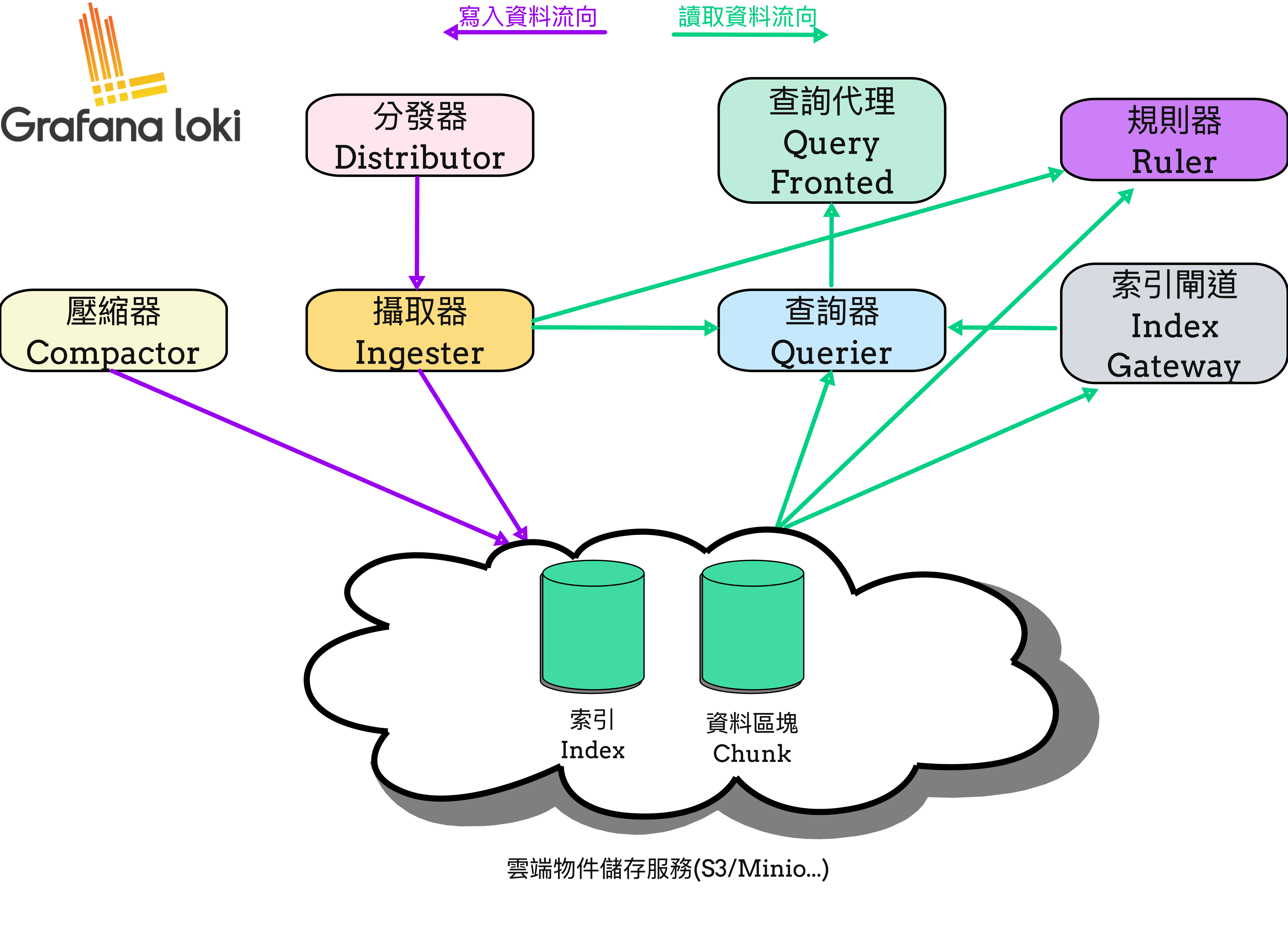
書本中 Ch10 圖10-3 提供了 Loki 每個組件的資料依賴關係。 其中 Ruler ,是 Loki v2.32.0 版本後正式提供的組件。能讓使用者從日誌中通過 LogQL 轉變成指標,可以用來觸發警報,或者評估後用來紀錄的指標。
用來觸發警報的稱為 Alerting Rules,而評估後用來紀錄的指標稱為 Recording Rules。
Grafana 雖然能設定直接對 Loki 設置 Alerting,每隔幾秒鐘就會去執行一次 LogQL 的聚合計算,而且儀表板上也可能很多圖表都是從 Loki 進行聚合近算顯示的結果。聚合計算又通常會搭配 json、count_over_time 、unwrap 或者 sum 等對 N 筆日誌進行資料轉型或運算操作。其實都這會耗費 Querier 很多資源。在這些場景下我們要的就只是簡單的指標數值,指標數值的儲存與運算恰好是 Prometheus 擅長的事情,如果我們能將這些資料的儲存與運算的職責交付給它,就能讓 Loki 的資源專注在 Log 的寫入與讀取上。
而且看圖片也能發現 Ruler 並不是對 Querier 進行訪問,而是直接對 Ingester 與持久化儲存進行存取。所以 Ruler 所需的資源就能與 Querier 隔離開來。
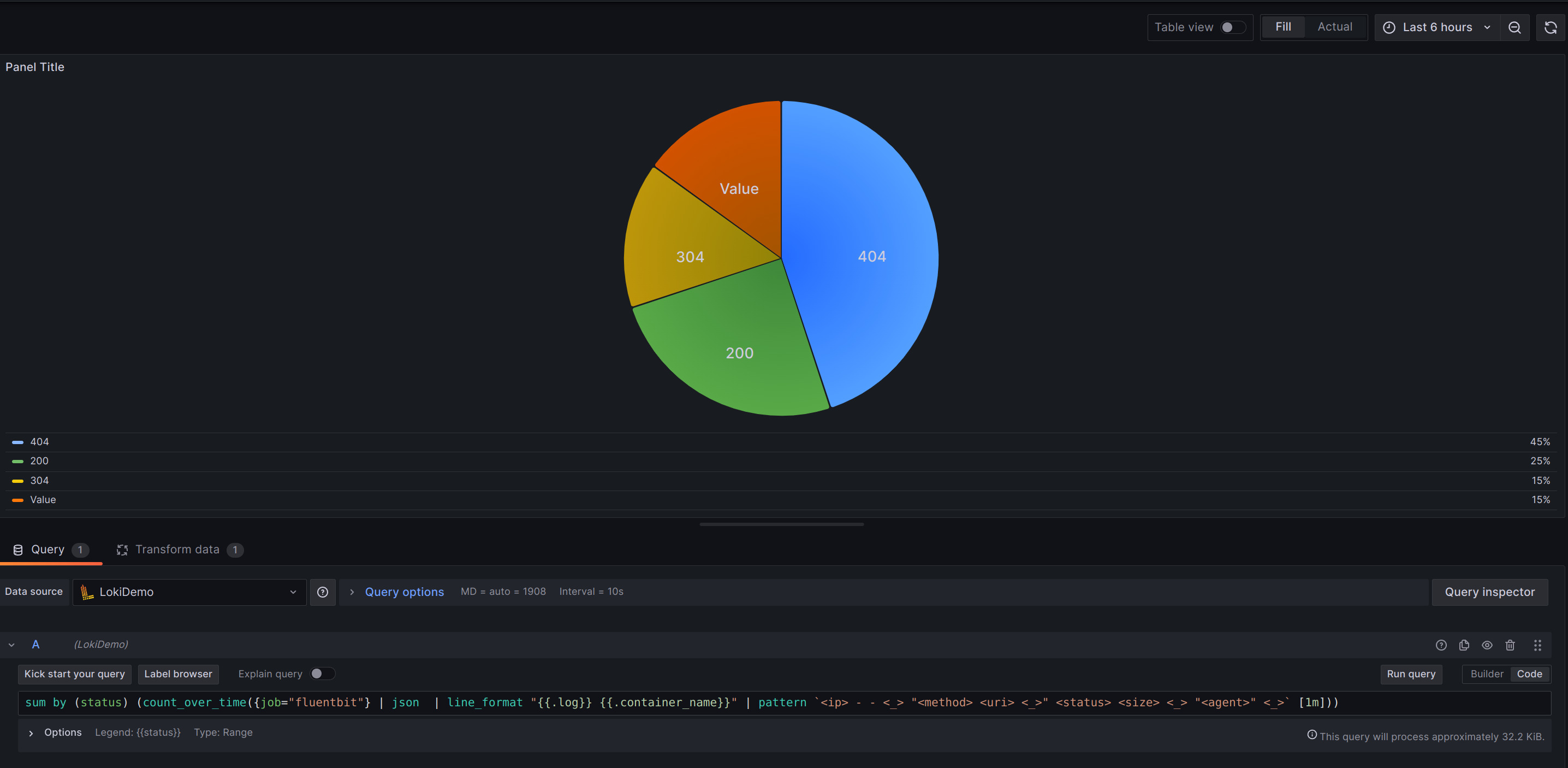
LogQL 如下︰
sum by (status) (count_over_time({job="fluentbit"} | json | line_format "{{.log}} {{.container_name}}" | pattern
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>[1m]))
通過 wrk 來壓測執行看看,觀察一下容易的資源使用情況。 wrk -t12 -c500 -d30s -s wrk_script.lua http://localhost:3101
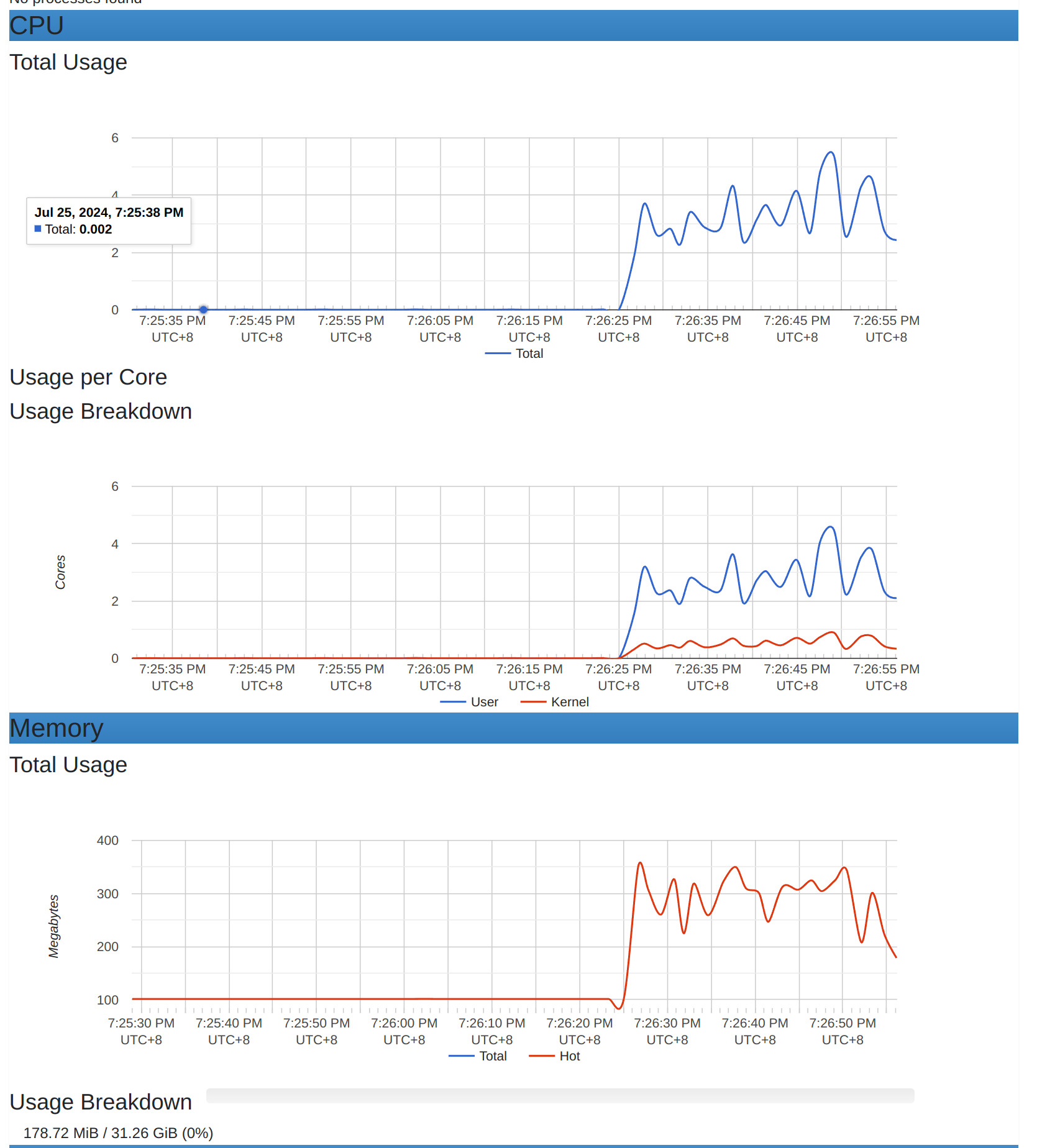
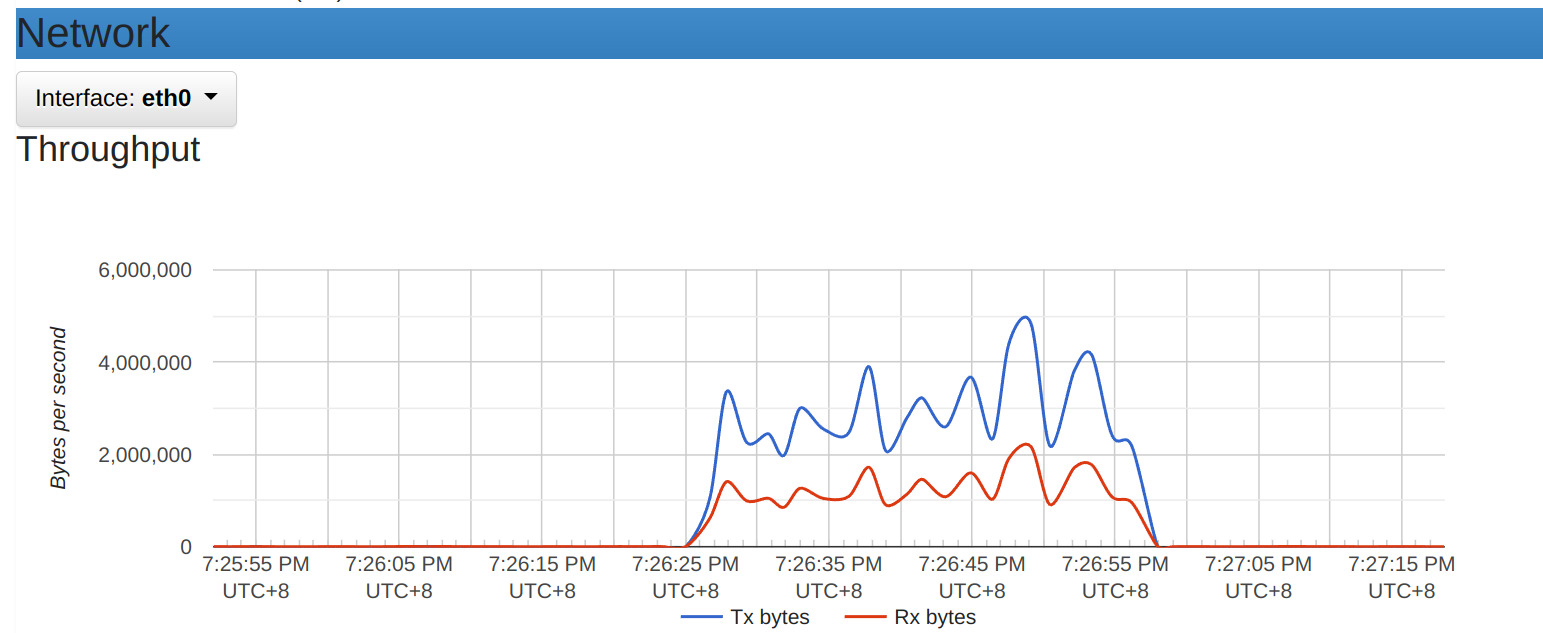
觀察上圖能發現,記憶體與網路吞楚量的使用很多。
這還建立在 Loki 讀寫分離架構的情況下。試想一下,如果單台 Loki 同時在日誌大量的寫入,加上這大量的複雜查詢操作,應該沒有機器能承受得住。
因此如果能把這些從 Log 轉成指標形式的操作,放在適合的後端系統(如 Prometheus),那能使得 Loki 資源能放在寫入日誌以及簡易查詢日誌用。
Ruler Recording Rules 的配置
Ruler 簡易配置最主要的有wal、storage、rule_path、ring、enable_api和remote_write。
範例如下︰
ruler:
wal:
dir: /tmp/rules/wal
storage:
type: local
lcaol:
directory: /etc/loki/rules
rule_path: /tmp/loki/rules
ring:
kvstore:
sotre: inmemory
enable_api: true
remote_write:
enable: true
client:
url: http://prometheus:9090/api/v1/write
storage
用來儲存和存取 Rule 的媒介。內建能使用configdb, azure, gcs, s3, swift, local, bos, cos。
local 的話就是看自定義的 rules 檔案能從哪裡給 Ruler 取得並加載到記憶體中生成對應的程式物件來執行。
rule_path
Ruler 有提供 HTTP API 能動態新增或刪減 Rules。
POST /loki/api/v1/rules/{namespace}DELETE /loki/api/v1/rules/{namespace}/{groupName}DELETE /loki/api/v1/rules/{namespace}
Ruler 若配置的是 localstorage 將無法動態新增刪除 rules。所以這次範例改用 AWS s3 示範。 新增的規則通常用於臨時新增或實驗用。但最後還是要寫成 Rules 檔案持久化,才能作到版本控制。
更詳細的 HTTP API 能參考 Loki HTTP API
enable_api
則是啟用 Ruler HTTP API。預設是true。
wal
Ruler 計算時生成的暫時資料。當 Ruler 崩潰時,並保證重啟後資料不會遺失,並且可以恢復運行中的狀態。
dir
指定用於儲存多租戶 WAL 文件的目錄。每個租戶將在此目錄下有自己的子目錄。
min_age/max_age
設置樣本在WAL中存在的最小/最大時間,只有超過這個時間的樣本才會被截斷。以確保WAL文件不會無限增長並佔用過多儲存空間。
remote_write
用來將指標寫入到指定的 Prometheus。
client
Prometheus remote-write endpoint
add_org_id_header
用於多租戶場景,會在 header 中攜帶 X-Scope-OrgID 的資訊。
ring
Ruler 配置成 Cluster 場景才有實際作用。有機會在深入講解。
Rules
Prometheus 也有 Alerting rules的功能,所以網站上有文件與範例。
而 Loki Rules 也是仿照這格式。
group
groups:
[ - <rule_group> ]
rule_group
# The name of the group. Must be unique within a file.
name: <string>
[ interval: <duration> | default = global.evaluation_interval ]
[ limit: <int> | default = 0 ]
[ query_offset: <duration> | default = global.rule_query_offset ]
rules:
[ - <rule> ... ]
rule
# The name of the time series to output to. Must be a valid metric name.
record: <string>
# The PromQL expression to evaluate.
expr: <string>
# Labels to add or overwrite before storing the result.
labels:
[ <labelname>: <labelvalue> ]
valid metric name 這是蠻重要的訊息,不然的話在某些 PromQL 操作時會出現以下警告提示metric might not be a counter, name does not end in _total/_sum/_bucket。
rule naming
rule 的命名格式是level:metric:operations。level、metric 和 operations 是非常重要的組成部分。這些組成部分確保了規則名稱的一致性和可讀性,使其在大規模系統中更容易管理和理解。
level
level 代表規則輸出結果的聚合層級和標籤。它指的是指標數據在某個特定層級上的聚合狀態,例如 instance(實例)、path(路徑)或 job(作業)。這些層級標籤能幫助你理解數據的來源以及它們的聚合方式。
實例層級:instance 標籤通常用於區分不同的服務實例。例如,instance_path:requests:rate5m 表示按實例和路徑聚合的每五分鐘請求速率。
路徑層級:path 標籤用於按路徑聚合數據。例如,path:requests:rate5m 表示按路徑聚合的每五分鐘請求速率。
作業層級:job 標籤則用於按作業(整個應用或服務)聚合數據。例如,job:request_failures_per_requests:ratio_rate5m 表示按作業聚合的請求失敗率。
metric
metric 是指標名稱,它應保持不變,除了在使用 rate() 或 irate() 時去除計數器的 _total 後綴。這樣做的目的是使指標名稱更加簡潔和一致,便於理解和查找。
保持一致性:指標名稱保持不變,確保我們能夠輕鬆地識別和理解指標。例如,requests_total 使用 rate() 計算後,去除 _total,變為 requests,這樣可以避免冗長的名稱並保持一致性。
- _total 用於計數器(Counter),表示累積總量。計數器通常會隨時間不斷增加,因此在使用 rate() 或 irate() 計算速率時,需要去除 _total 後綴。例如,
http_requests_total使用 rate() 後變為http_requests。
- record: instance:http_requests:rate5m
expr: rate(http_requests_total{job="myjob"}[5m])
- _sum 用於累積總和(例如,Summary 和 Histogram),表示總和數據。累積總和指標也可以與 rate() 或 irate() 一起使用,但不需要去除
_sum後綴,因為它表示的是累積總和數據。例如,http_request_duration_seconds_sum可以用來計算平均值。
- record: instance:http_request_duration_seconds:mean5m
expr: |2
rate(http_request_duration_seconds_sum{job="myjob"}[5m])
/
rate(http_request_duration_seconds_count{job="myjob"}[5m])
- _bucket 用於直方圖(Histogram),表示分佈區間的計數。直方圖中的 _bucket 後綴表示的是數據分佈在不同區間的計數,可以用來計算每個區間的速率。例如,
http_request_duration_seconds_bucket用於表示 HTTP 請求持續時間的分佈區間。
- record: instance:http_request_duration_seconds_bucket:rate5m
expr: rate(http_request_duration_seconds_bucket{job="myjob"}[5m])
operations
operations 是應用於指標的一系列操作,最新的操作放在命名最前面。這些操作描述了如何從原始數據計算出最終的指標值。
操作順序:操作的順序從最新到最舊。例如,requests:rate5m 表示對 requests 指標計算五分鐘速率的操作,其中 rate5m 是最新的操作。 常見操作:
rate():計算速率。例如,rate(requests_total[5m]) 表示計算每五分鐘的請求速率。
sum():求和。例如,sum without (instance)(requests) 表示對所有實例的請求數據求和。
mean():計算平均值。例如,mean(request_latency_seconds_sum{job="myjob"}) 表示計算特定作業的平均請求延遲。
例如︰
- 聚合每秒請求數
- record: instance_path:requests:rate5m
expr: rate(requests_total{job="myjob"}[5m])
這條記錄規則的名稱是 instance_path:requests:rate5m:
level 是 instance_path,表示按實例和路徑聚合。 metric 是 requests,從 requests_total 中去掉了 _total 後綴。 operations 是 rate5m,表示計算五分鐘內的速率。
- 計算請求失敗率
- record: instance_path:request_failures_per_requests:ratio_rate5m
expr: |2
instance_path:request_failures:rate5m{job="myjob"}
/
instance_path:requests:rate5m{job="myjob"}
這條記錄規則的名稱是 instance_path:request_failures_per_requests:ratio_rate5m:
level 是 instance_path,表示按實例和路徑聚合。 metric 是 request_failures_per_requests,表示請求失敗的比率。 operations 是 ratio_rate5m,表示計算五分鐘內的比率。
|2
| 是 YAML 的多行字串的用法,而 2 則表示每行都縮排空格數量為2。
參考 best practices for naming metrics created by recording rules
以下是一個Nginx rule 的群組。裡面包含2條rule。
groups:
- name: NginxRules
interval: 1m
rules:
- record: nginx:requests:rate1m
expr: |
sum(
rate({container="nginx"}[1m])
)
labels:
cluster: "us-central1"
- record: nginx:error:sum1h
expr: |
sum(
count_over_time({container="nginx"} | json | status >= 400 [1h])
)
labels:
cluster: "us-central1"
Demo
讓我們在ch10/loki_ruler下執行docker compose up -d,然後執行以下命令以新增以下的 rule 於 Loki Ruler 中。 這些 HTTP API 在有簡單提到。
curl --location 'http://localhost:3100/loki/api/v1/rules/tenant1' \
--header 'X-Scope-OrgID: tenant1' \
--header 'Content-Type: application/yaml' \
--data 'name: nginx_rules
interval: 5s
rules:
- record: nginx:status_total:count1m
expr: sum by (status) (count_over_time({job="fluentbit"} | json | line_format "{{.log}} {{.container_name}}" | pattern `<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>` [1m]))
labels:
- record: scalar
expr: 10
labels:
soure: "static"'
建立成功會取得以下結果。
http status : 202
{
"status": "success",
"data": null,
"errorType": "",
"error": ""
}
然後能通過以下命令來確認是否rule新增成功。
curl --location 'http://localhost:3100/loki/api/v1/rules/tenant1' \
--header 'X-Scope-OrgID: tenant1' \
--data ''
會取得這樣樣回傳結果
tenant1:
- name: nginx_rules
interval: 5s
rules:
- record: nginx:status_total:count1m
expr: sum by (status) (count_over_time({job="fluentbit"} | json | line_format "{{.log}} {{.container_name}}" | pattern `<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>` [1m]))
- record: scalar
expr: "10"
labels:
soure: static
接著來到 Prometheus WebUI 就能看到剛剛新增的兩個指標了nginx:status_total:count1m與scalar。這樣我們就能進行最早的實驗。執行以下wrk命令來產生大量對nginx的請求。 wrk -t12 -c400 -d30s -s wrk_nginx_script.lua http://localhost:8000
一樣的效果改成從 Prometheus 撈取資料顯示。
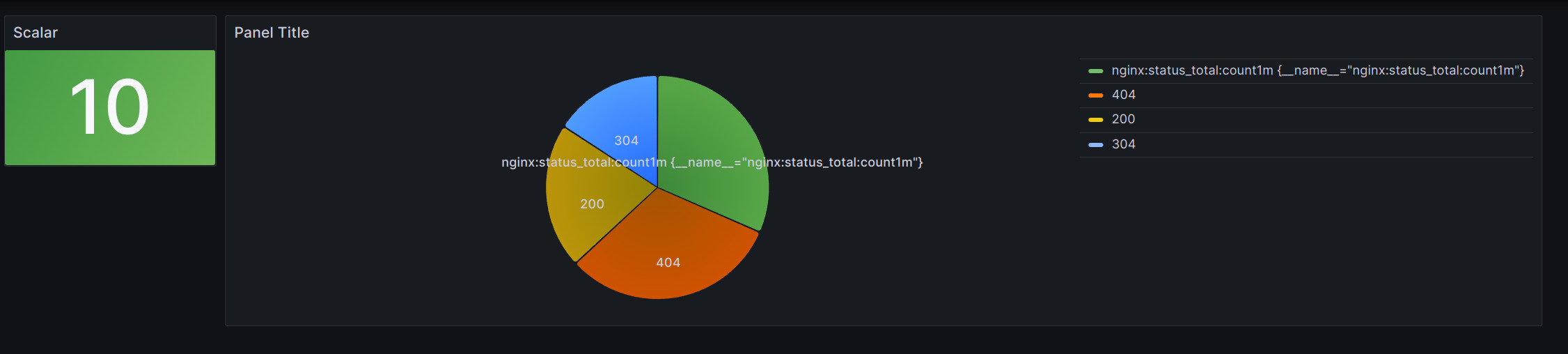
Loki_reader 的資源相較之前也降低非常的多。因為它只需要定期的去撈取日誌並計算就好。
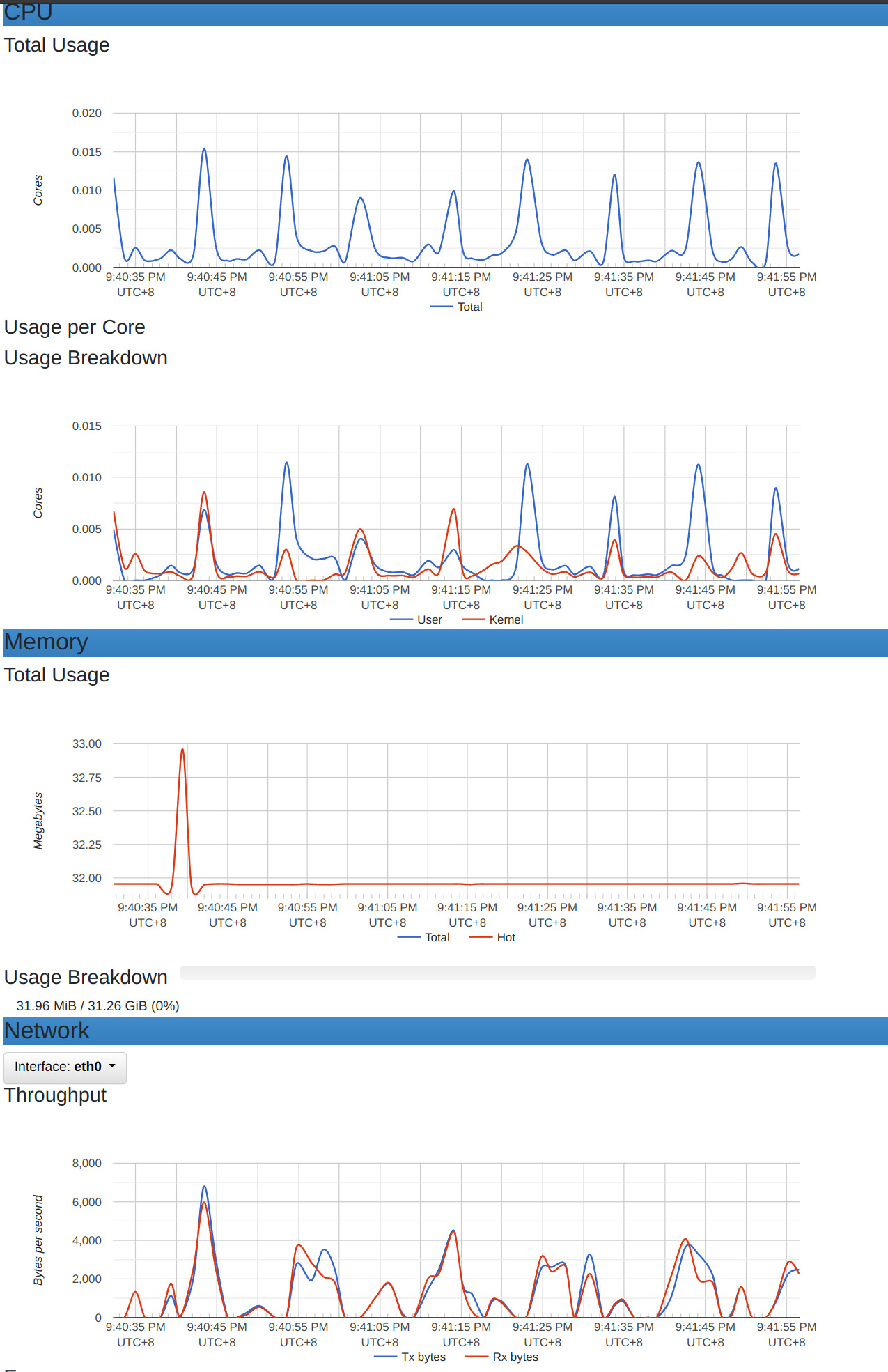

最主要的是指標的資料大小是遠小於日誌的。這在雲端上像是 S3 或一些服務都以流量計費的,會省非常多,且不用吃到太多Loki主機的資源。




