

Day 8 透過 Go Tool Trace 看見問題
昨天我們通過作業系統提供的工具看見程式在發生 context switching 並吃到 CPU 的負載。今天能看看這隻 Go 撰寫的程式怎麼通過其生態圈提供的工具來看見問題。

Go Trace
在 Go 的診斷工具中,Tracing 是一種用於分析程式碼延遲和執行路徑的重要工具。透過追蹤程式碼的執行,可以深入了解應用程式在處理請求或任務時的各個階段的延遲情況,識別出效能瓶頸。































Trace 概述
Tracing 是一種透過對程式碼進行追蹤,從而分析整個呼叫鏈中的延遲的技術。它不僅能幫助我們理解單一請求的執行時間,還能用於分析複雜系統中分散式請求的效能。
Trace 在 Go 中的實現
Go 提供了一個執行時間執行追蹤器(runtime execution tracer),用於在指定時間段內擷取各種執行時間事件,如排程、系統呼叫、垃圾收集(GC)、Heap 大小等。這些事件可以透過 go tool trace 進行視覺化和分析。透過 Trace,可以識別 CPU 使用率、網路或系統呼叫是否導致了 goroutine 的搶佔,以及系統的整體並行執行情況。
Trace 的用途
分析應用程式延遲:透過追蹤和分析應用程式的延遲,可以了解每個元件對整體延遲的貢獻,從而識別效能瓶頸。
理解 goroutine 的執行方式:Trace 提供了對 goroutine 執行的詳細分析,幫助識別哪些 goroutine 有延遲或阻塞問題。
檢查並行執行問題:Trace 能幫助偵測程式是否有併發化不足的問題,例如是否有因 Lock 競爭而導致的串列執行。
因此將範例程式新增 runtime/trace 。
package main
import (
"flag"
"fmt"
"log"
"net/http"
"os"
"runtime"
"runtime/pprof"
"runtime/trace"
"sync"
"time"
)
// 模擬一個從 Message Queue 中接收任務並處理的 Worker
func worker(id int, tasks <-chan int, wg *sync.WaitGroup) {
defer wg.Done()
for task := range tasks {
// 模擬 I/O 操作 (寫入和讀取文件)
filename := fmt.Sprintf("/tmp/testfile_%d_%d", id, task)
data := make([]byte, 1024*1024*2) // 生成 2MB 的數據
// 模擬寫文件 I/O
err := os.WriteFile(filename, data, 0644)
if err != nil {
log.Printf("Error writing file: %v\n", err)
}
// 模擬讀文件 I/O
_, err = os.ReadFile(filename)
if err != nil {
log.Printf("Error reading file: %v\n", err)
}
// 刪除文件
os.Remove(filename)
// 模擬其他 CPU 任務
sum := 0
for i := 0; i < 100000; i++ {
sum += i
}
}
}
func main() {
// 使用 flag 來設置 worker 的數量
numWorkers := flag.Int("workers", 10, "number of workers to start")
numTasks := flag.Int("tasks", 1000, "number of tasks to process")
procs := flag.Int("procs", 1, "number of go max procs")
flag.Parse()
// 設置最大 CPU 核心數,這裡可以嘗試不同的設定來觀察效果
runtime.GOMAXPROCS(*procs)
// 啟動 pprof 監控
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// 設置 Trace 和 CPU Profile
cpuFile, err := os.Create("cpu.prof")
if err != nil {
log.Fatalf("could not create CPU profile: %v", err)
}
defer cpuFile.Close()
if err := pprof.StartCPUProfile(cpuFile); err != nil {
log.Fatalf("could not start CPU profile: %v", err)
}
defer pprof.StopCPUProfile()
traceFile, err := os.Create("trace.out")
if err != nil {
log.Fatalf("could not create trace file: %v", err)
}
defer traceFile.Close()
if err := trace.Start(traceFile); err != nil {
log.Fatalf("could not start trace: %v", err)
}
defer trace.Stop()
// 定義不同的 Worker 數量來測試
//for numWorkers := 10; numWorkers <= 100; numWorkers += 10 {
//numWorkers := 125
start := time.Now()
// 控制任務數量
//numTasks := numTasks
// 創建一個 Channel 作為任務隊列
tasks := make(chan int, *numTasks)
var wg sync.WaitGroup
// 啟動多個 Worker
for i := 0; i < *numWorkers; i++ {
wg.Add(1)
go worker(i, tasks, &wg)
}
// 模擬向 Message Queue 中發送事件
for i := 0; i < *numTasks; i++ {
tasks <- i
}
close(tasks)
// 等待所有 Worker 完成
wg.Wait()
elapsed := time.Since(start)
fmt.Printf("Workers: %d, Elapsed Time: %s\n", *numWorkers, elapsed)
//}
}
一樣編譯後執行該程式,會發現產生了 trace.out這檔案。
Go Tool Trace
Go 有提供幾個工具,都能在 go/cmd 底下找到︰
go tool trace Go 提供的一個工具,用於檢視和分析程式的 Trace 檔案。這個工具可以幫助開發者深入理解程式的執行時間行為,特別是在並發程式的調度、系統呼叫、Atomic Primitives(如鎖定和通道)以及網路 I/O 等方面。以下是 go tool trace 的主要功能和使用方法的詳細說明:
go tool trace 需要 Trace來進行分析,而產生Trace 有三種方式︰
runtime/trace.Start
net/http/pprof package
go test -trace
我們主要展示的是第一種,能看見上述的範例 import runtime/trace。
查看 Trace 檔案
產生 Trace 檔案後,你可以使用以下命令在瀏覽器中查看 Trace 檔案的詳細內容:
# 假設檔名是 trace.out
go tool trace trace.out

然後瀏覽器就會被自動開啟了。細節等等在介紹。
產生 Pprof 類似的 Profile
除了查看 Trace 檔案外,你還可以使用 go tool trace 從 Trace 資料中提取類似 pprof 的 Profile。這些 Profile 可以幫助你分析程式的效能瓶頸。
支援的 Profile 類型包括:
net: 網路阻塞
Profile sync: 同步阻塞
Profile syscall: 系統呼叫阻塞
Profile sched: 調度延遲 Profile
go tool trace -pprof=sync trace.out > sync.pprof
這個指令會從 Trace 檔案中提取調度延遲的 Profile,並將其儲存為 sched.pprof 檔案。
由這些範例不難發現,trace 檔案的副檔名我們習慣使用 .out,而 pprof檔案的副檔名則是 .pprof,與標準習慣一致是比較好的。
net:網路阻塞 Profile
用途:
net Profile 用於分析程式中 Goroutine 因為網路 I/O 操作(如網路請求、資料傳輸等)而導致的阻塞情況。這個 Profile 可以幫助識別網路操作中導致程式延遲的瓶頸,例如網路連線、資料讀取或寫入時的延遲。
典型場景:
當一個 Goroutine 發起網路請求(例如透過 net/http 套件進行 HTTP 請求),如果網路較慢或目標伺服器回應時間較長,Goroutine 就會因為等待網路 I/O 操作完成而阻塞。 如果程式經常進行網路通訊,網路延遲或頻寬限制可能會顯著影響程式的回應時間和吞吐量。
如何使用:
產生 Trace 資料後,可以使用下列命令產生 net Profile:
go tool trace -pprof=net trace.out > net.pprof
然後使用 go tool pprof net.pprof 進行分析,查看哪些網路操作引起了最長時間的阻塞。
net Profile 分析的具體內容:
連線阻塞:當 Goroutine 嘗試建立網路連線(如透過 Dial 方法)時,可能會因為網路不通或連線耗時過長而阻塞。 net Profile 會記錄這些情況。 資料讀取阻塞:Goroutine 從網路連線讀取資料時,若網路傳輸速度較慢或對端回應時間長,Goroutine 會等待資料流完成,導致阻塞。 資料寫入阻塞:Goroutine 透過網路連線傳送資料時,如果網路頻寬有限或對端接收速度慢,也會導致寫入操作的阻斷。
典型使用場景
Web 服務:對於需要處理大量 HTTP 請求的 Web 服務,透過 net Profile 可以識別哪些請求處理因網路延遲而受阻,從而優化網路請求的分發或增加連線池。
分散式系統:在分散式系統中,節點之間的通訊至關重要。使用 net Profile 可以幫助開發者找到網路通訊中的瓶頸,並優化節點之間的資料傳輸效率。
API 用戶端:對於需要頻繁呼叫外部 API 的用戶端應用,透過分析 net Profile,可以優化請求的策略(如 Timeout、Retry 等)以減少網路延遲的影響。
如何利用 net Profile 進行最佳化
Connection pool 最佳化:如果發現大量連線阻塞,可以考慮使用 Connection pool以減少建立新連線的開銷。
逾時設定:在網路請求中設定合理的逾時,可以避免因網路問題導致的長時間阻塞。
並發請求控制:透過限制並發請求數,防止網路頻寬被耗盡,從而減少請求間的相互影響。
快取和負載平衡:對於頻繁存取的資源,使用快取或負載平衡技術可以降低單點的網路負擔,提升整體效能。
sync:同步阻塞 Profile
用途:
sync Profile 用於分析程式中因使用同步原語(如 Mutex、RWMutex、Cond、WaitGroup、Channel 等)而導致的 Goroutine 阻塞情況。這個 Profile 可以幫助開發者辨識鎖定競爭、mutex 爭用等問題,從而優化同步機制,減少不必要的阻斷。
典型場景:
鎖定競爭:當多個 Goroutine 同時嘗試取得一把鎖(如 Mutex 或 RWMutex),如果鎖的持有時間過長,其他 Goroutine 就會在取得鎖定時被阻塞,這可能導致程式的整體效能下降。 Channel 阻塞:Goroutine 在等待從 Channel 接收或發送資料時,如果 Channel 被填滿或為空,Goroutine 可能會被阻塞,直到操作能夠繼續進行。 條件變數(Cond)阻塞:使用條件變數時,Goroutine 可能會等待某個條件滿足而被阻塞。
如何使用:
產生 Trace 資料後,可以使用下列命令產生 sync Profile:
go tool trace -pprof=sync trace.out > sync.pprof
然後使用 go tool pprof sync.pprof 進行分析,查看哪些同步原語導致了最長時間的阻塞。
sync Profile 分析的具體內容:
鎖(Mutex/RWMutex)阻塞:在多 Goroutine 環境下,鎖是用來保護共享資源的常用機制。當一個 Goroutine 持有鎖時,其他嘗試取得鎖的 Goroutine 將被阻塞,直到鎖被釋放。 sync Profile 能夠幫助你辨識出這些鎖爭用的情況,並查看這些鎖阻塞了哪些 Goroutine 以及阻塞時間有多長。
Channel 阻塞:Channel 是 Go 中用於 Goroutine 之間通訊的主要機制。如果一個 Goroutine 嘗試向一個已滿的 Channel 發送資料,或從一個空的 Channel 接收資料,那麼它就會被阻塞。 sync Profile 可以顯示這些阻塞情況,幫助你理解程式的瓶頸所在。
條件變數阻塞:條件變數(sync.Cond)允許 Goroutine 等待某個條件滿足。多個 Goroutine 可能會同時等待相同的條件,因此可能會導致阻塞。 sync Profile 可以顯示這些等待的 Goroutine 及其等待的時長。
典型使用場景 高並發 Web 服務:
在處理大量並發請求時,鎖的設計和使用至關重要。透過 sync Profile,可以發現哪些部分有嚴重的鎖爭用,從而優化鎖的粒度或使用無鎖資料結構。 多執行緒資料處理:在並發資料處理任務中,多個 Goroutine 可能需要協調處理共享資料。 sync Profile 可以幫助你辨識這些協調中的瓶頸,例如 Channel 阻斷或條件變數等待。 資源管理:在需要嚴格同步的場景中,例如管理共享資源池,透過 sync Profile 可以找到資源取得和釋放的瓶頸。
如何利用 sync Profile 進行最佳化
減少鎖的持有時間:如果發現鎖爭用嚴重,可以考慮縮短鎖的持有時間,盡量將鎖的範圍限制在必要的最小程式碼區塊內。
分解鎖:將一個大鎖拆分為多個小鎖,降低鎖的競爭粒度,使不同的 Goroutine 可以並發執行而不互相阻塞。
使用 lock-free 資料結構:在某些場景下,可以使用無鎖的資料結構(如 atomic 操作、CAS 等)來替代鎖,從而減少阻塞。
最佳化 Channel 使用:如果 Channel 阻塞嚴重,可以考慮增加 Channel 緩衝區的大小,或重新設計 Goroutine 通訊的策略。
syscall:系統呼叫阻塞 Profile
用途:
syscall Profile 用來分析程式中 Goroutine 因為系統呼叫(Syscall)而導致的阻塞情況。系統呼叫是程式與作業系統核心互動的主要方式,例如檔案 I/O、網路 I/O、處理程序控制等操作。 syscall Profile 可以幫助開發者辨識出哪些系統呼叫導致了 Goroutine 阻塞,以及這些阻塞如何影響程式的效能。
典型場景:
檔案 I/O:當 Goroutine 進行檔案讀取或寫入操作時,如果硬碟效能較差或 I/O 操作耗時較長,Goroutine 就會在系統呼叫處阻塞,等待操作完成。
網路 I/O:網路通訊涉及的系統呼叫(如 send, recv, connect 等)如果遇到網路延遲、頻寬限製或對方伺服器回應緩慢,Goroutine 也會阻塞,等待網路操作完成。
處理程序控制:例如呼叫 fork, exec 或其他與處理程序管理相關的系統呼叫時,Goroutine 可能會因為系統資源或操作的複雜性而阻塞。
如何使用:
產生 Trace 資料後,可以使用下列命令產生 syscall Profile:
go tool trace -pprof=syscall trace.out > syscall.pprof
然後使用 go tool pprof syscall.pprof 進行分析,查看哪些系統呼叫導致了最長時間的阻塞。
syscall Profile 分析的具體內容:
系統呼叫阻塞:Goroutine 在執行系統呼叫時,通常會交出控制權給作業系統 kernel,等待系統執行完成並傳回結果。在此期間,Goroutine 會處於阻塞狀態,無法執行其他操作。 syscall Profile 記錄了這些阻塞的發生位置和持續時間。
I/O 阻塞:檔案和網路 I/O 是最常見的系統呼叫操作。如果系統 I/O 效能不佳或資源競爭嚴重,Goroutine 可能會長時間等待,syscall Profile 可以協助識別這些問題。例如,在檔案寫入時,硬碟效能下降或檔案鎖定競爭激烈都會導致 I/O 阻斷。
資源爭用:某些系統呼叫涉及作業系統資源的爭用,例如檔案鎖、Port 綁定等。 syscall Profile 可以幫助你找到這些爭用點,進而最佳化系統資源的使用。
典型使用場景
高負載 Web 服務:在 Web 服務中,頻繁的網路請求處理和 log 檔案寫入操作可能會導致系統呼叫阻塞。透過 syscall Profile,可以找出哪些系統呼叫是效能瓶頸,並進行對應的最佳化。
分散式系統:在分散式系統中,各個節點之間的通訊通常依賴網路 I/O。如果網路效能不佳,可能會導致大量的系統呼叫阻塞,影響整體系統的效能和回應時間。
高效能運算:在需要大量資料處理和檔案 I/O 的高效能運算任務中,syscall Profile 可以幫助識別哪些系統呼叫導致了效能瓶頸,從而優化資料讀取和寫入的策略。
如何利用 syscall Profile 進行最佳化
非同步 I/O:如果某些系統呼叫導致了嚴重的阻塞,可以考慮使用非同步 I/O 操作(如 select, epoll, kqueue 等),以減少阻塞時間,提高並發處理能力。
增加快取:在檔案或網路 I/O 中引入緩存,可以減少直接與系統互動的頻率,從而減少系統呼叫的阻塞時間。
最佳化資源分配:如果阻塞是由於系統資源(如檔案鎖、連接埠等)爭用導致的,考慮調整資源的分配策略,或透過增加資源數量來降低競爭。
分析並最佳化 I/O 效能:對於檔案 I/O 阻塞,可能需要進一步分析磁碟效能或檔案系統配置,以提高整體 I/O 效能,減少系統呼叫阻塞。
sched:調度延遲 Profile
用途:
sched Profile 用於分析 Go 程式中 Goroutine 調度中的延遲情況。調度延遲是指 Goroutine 已經準備好運行,但因為沒有可用的 CPU 或其他原因而沒有立即得到調度執行的時間。這種延遲可能是系統負載過高、CPU 資源緊張、或調度器策略導致的。 sched Profile 可以幫助開發者識別這些調度延遲的根源,從而優化程式的並發效能。
典型場景:
高併發環境下的 CPU 爭用:當系統中存在大量 Goroutine 競爭有限的 CPU 資源時,部分 Goroutine 可能會因為沒有可用的 CPU 而被延遲調度。這種情況在 CPU 密集型任務或系統負載較高時尤其明顯。
調度器策略:Go 的調度器負責在多個 Goroutine 之間分配 CPU 時間片。如果調度器分配不均衡或策略有問題,可能會導致某些 Goroutine 被延遲調度。
系統資源爭用:某些系統資源(如記憶體、I/O 等)的爭用也可能間接導致 Goroutine 調度延遲,因為這些資源的爭用會影響到 Goroutine 的執行和調度。
如何使用:
產生 Trace 資料後,可以使用下列命令產生 sched Profile:
go tool trace -pprof=sched trace.out > sched.pprof
然後使用 go tool pprof sched.pprof 進行分析,查看哪些 Goroutine 因為調度延遲而受到了影響。
sched Profile 分析的具體內容:
調度延遲:sched Profile 記錄了 Goroutine 準備好運作與實際得到 CPU 調度執行之間的延遲時間。這種延遲時間如果過長,可能會導致程式的回應時間增加,特別是在即時性要求較高的系統中。
調度頻率:sched Profile 還可以幫助你分析 Goroutine 的調度頻率,也就是某個 Goroutine 被調度執行的頻率如何。如果某個 Goroutine 的調度頻率過低,可能表示它受到其他高優先任務的壓制,或是系統資源緊張。
context switching:在高並發環境中,頻繁的 context switching也可能導致調度延遲。調度器需要在不同的 Goroutine 之間切換執行,這個過程會帶來開銷。如果context switching 過於頻繁,反而會影響整體效能。
典型使用場景
高並發伺服器:對於處理大量請求的伺服器應用程序,調度延遲可能會導致請求處理時間增加。透過 sched Profile,你可以辨識出哪些 Goroutine 的調度延遲較長,從而優化伺服器的資源分配策略。
即時性應用:在需要即時回應的系統中,調度延遲可能會導致回應時間超出預期。使用 sched Profile 可以幫助你分析和最佳化 Goroutine 的調度策略,以確保關鍵任務能夠及時執行。
CPU 密集型任務:對於 CPU 密集型應用,Goroutine 之間的調度競爭可能非常激烈。 sched Profile 可以幫助你辨識並優化這些競爭,減少排程延遲。
如何利用 sched Profile 進行最佳化
優化 Goroutine 的數量:減少同時活躍的 Goroutine 數量,以減少調度器的負擔,避免因過多的 Goroutine 導致調度延遲。
調整 GOMAXPROCS:透過調整 runtime.GOMAXPROCS 的值,優化 CPU 核心的使用率。確保程式在多核心 CPU 上能充分利用所有核心,以減少調度延遲。
減少不必要的 Goroutine 創建:避免過度創造 Goroutine,尤其是在高並發環境中。可以透過使用 Goroutine 池或限制 Goroutine 的同時數量來減少調度延遲。
優化 context switching:減少頻繁的 context switching,例如避免使用頻繁的鎖定/解鎖操作,或在可能的情況下使用無鎖演算法,減少調度器的負擔。
Go Trace Event Viewer
在產出 trace.out後,我們執行go tool trace trace.out。
此時會出現這樣的訊息。Port號不一定。
2024/08/29 23:07:14 Preparing trace for viewer...
2024/08/29 23:07:14 Splitting trace for viewer...
2024/08/29 23:07:15 Opening browser. Trace viewer is listening on http://127.0.0.1:42345
此時我們會打開一個瀏覽器視窗如下圖。跟網路上很多文章看到的似乎有點變化對吧?因為在 Go 1.22 版本更新了 Trace View,增加了每個子頁面的內容。

以下是 go tool trace 中各個功能的詳細說明:
Event Timelines for Running Goroutines︰
Goroutines 的事件時間軸,展示了在 Go 程式執行期間,每個 Goroutine 的運行時間軸。你可以選擇以邏輯處理器(proc)或作業系統執行緒(thread)的視角來查看這些事件。
by proc:展示每個
GOMAXPROCS邏輯處理器的時間線,顯示在某一時刻哪個 Goroutine 在該處理器上運作。這個視圖有助於分析 Goroutine 在不同處理器之間的遷移,以及它們的運行時長。by thread:如果可用,顯示每個作業系統執行緒的時間線,顯示某個 Goroutine 在哪個執行緒上執行。這對於理解 Goroutine 如何映射到作業系統的實際執行緒上非常有用。
STATS 統計資訊︰稍後細講。
Runtime-Internal Events 執行時期的內部事件︰
GC
Network、Timer、Syscall
Goroutine Analysis︰用於分析一組共享相同主函數的 Goroutine 的行為。可以查看與這一組 Goroutine 相關的四種阻塞 Profile(網路阻塞、同步阻塞、系統呼叫阻塞、調度延遲)。每個 Goroutine 實例的具體執行統計資訊。例如,它們的總執行時間、阻塞時間、系統呼叫阻塞時間等。 每個 Goroutine 實例都有一個指向它的事件時間線的連結。點擊連結後,可以查看該 Goroutine 的時間線,並展示它與其他 Goroutine 透過阻塞/解阻事件互動的情況。
Profiles(阻塞 Profiles) go tool trace 提供了四種阻塞 Profile,這些 Profile 展示了阻止 Goroutine 在邏輯處理器上運行的各種原因。
Network blocking profile:顯示因網路 I/O 而導致的阻斷。
Synchronization blocking profile:顯示由於同步操作(如鎖或通道)導致的阻塞。
Syscall profile:顯示由於系統呼叫而導致的阻塞。
Scheduler latency profile:顯示調度器延遲導致的阻斷。
User-Defined Tasks and Regions(使用者自訂任務和區域) Go 的 trace API 允許程式在 Goroutine 內標註程式碼區域(如關鍵函數),以便分析其效能。也可以為這些區域記錄日誌事件,並關聯執行時的資料值。
User-defined tasks:顯示每個任務的執行時間直方圖。點擊可以查看任務的事件時間線,包括 Goroutine 的建立、日誌事件、子區域的開始和結束等。
User-defined regions:顯示使用者定義的程式碼區域的執行時間直方圖,並提供與該區域相關的事件時間軸。這有助於識別區域中執行緩慢的步驟,以及資料值與執行時間之間的關係。
Garbage Collection Metrics(垃圾回收指標) 包括垃圾回收期間的各種重要指標,例如:Minimum mutator utilization:顯示垃圾回收期間的最小「突變器」(即應用程式程式碼)的利用率。這可以幫助你理解垃圾回收對應用程式的影響。
實際分析 Goroutine Analysis
會先看到如下圖,這裡能告訴我們整個應用程式中,有多少 Goroutine,又是在什麼 package 裡面建立並運行這些 goroutine,以及總共執行時間。
讓我們一起分析以下的圖。

主要 Goroutine 分佈
從圖來看,您可以看到 Goroutine 的啟動位置以及這些 Goroutines 的數量和總執行時間。這裡是重點數據的解讀:
| Start Location | Count | Total Execution Time |
| main.excessiveWorker | 1000 | 1.598845619s |
| runtime.gcBgMarkWorker | 1 | 401.358648ms |
| runtime.bgscavenge | 1 | 154.031374ms |
| runtime.bgsweep | 1 | 11.882451ms |
| 其他 Goroutine | 其餘單次執行都較短 |
從這些數據中,可以得出以下觀察:
main.excessiveWorker占主導地位
Goroutine 數量:
main.excessiveWorker創建了 1000 個 Goroutines,這是這個程序中的主要 Goroutine 群組。總執行時間:這個 Goroutine 群組總共花費了 1.6 秒的執行時間,占用了大部分的計算資源。
這裡可以推測出這個名為 excessiveWorker 的 Goroutine 群組在處理某個密集的任務,並且它創建了過多的 Goroutines,導致 CPU 資源過度競爭。這樣會帶來以下幾個問題:
上下文切換開銷:當有大量的 Goroutines 被創建並調度時,調度器會需要頻繁進行上下文切換,從而導致系統開銷增加,進而影響整體性能。
Goroutine 競爭:過多的 Goroutines 會導致這些 Goroutines 爭奪 CPU 資源或共享資源(如記憶體、I/O),進一步降低系統的效能。
其他 Goroutines 的運行狀態
GC 相關 Goroutine:從表中可以看到 GC 相關的 Goroutines,如
gcBgMarkWorker、bgscavenge和bgsweep,它們分別負責垃圾回收的標記、清除和內存整理。gcBgMarkWorker:花費了 401.358648 毫秒,這是一個相對高的垃圾回收工作時間。過多的 GC 可能會對系統性能造成一定的影響,尤其是在高併發的情況下。
bgsweep 和 bgscavenge:它們分別花費了 11 毫秒和 154 毫秒,這些值相對較低,表示在這段時間內的 GC 壓力並不大。
小範圍執行的其他 Goroutines
- 其餘的 Goroutines (如
main.main、internal/singleflight.(*Group).doCall等)總執行時間非常短,且只有 1 個 Goroutine。這些任務並未對整體性能造成影響,可能是一些初始化或輔助性的執行邏輯。
瓶頸分析
問題 1:
main.excessiveWorker佔據了大部分計算資源推測原因:
excessiveWorker這個 Goroutine 群組創建了過多的 Goroutines(1000 個),且每個 Goroutine 在相對較長的時間內執行。這可能是由於錯誤的並發設計導致的 Goroutine 爆炸問題(Goroutine Leak)或無限迴圈。影響:過多的 Goroutines 導致 CPU 資源耗盡,進而降低了整體系統性能。這會帶來上下文切換過多以及 Goroutine 間競爭資源的問題。
問題 2:GC 壓力
雖然垃圾回收的壓力不大,但
gcBgMarkWorker花費了 400 毫秒的時間,這可能是由於大量 Goroutines 創建和銷毀時產生了大量的內存分配和釋放,進而加重了垃圾回收的負擔。優化建議:可以嘗試減少內存分配和釋放頻率,降低 GC 的負擔。
所以這一頁就已經能給我分一些優化改善方向,
主要問題:過多的 Goroutines(特別是
main.excessiveWorker),導致了 CPU 資源的競爭,進而影響了程式的整體效能。垃圾回收的負擔也增加了。優化方向:減少 Goroutines 的數量,優化內存管理,避免頻繁的內存分配和釋放,並針對具體的 Goroutine 進行性能剖析,找出瓶頸並進行調整。
這些措施應能有效地減少系統負擔,並提高程式的併發性能。但我能根據 D6 介紹的 80/20 定律(80% 的性能瓶頸來自於 20% 的系統資源或程式碼區段)。選擇 main.excessiveWorker 來查看分析。就會看見如下圖所示的內容。
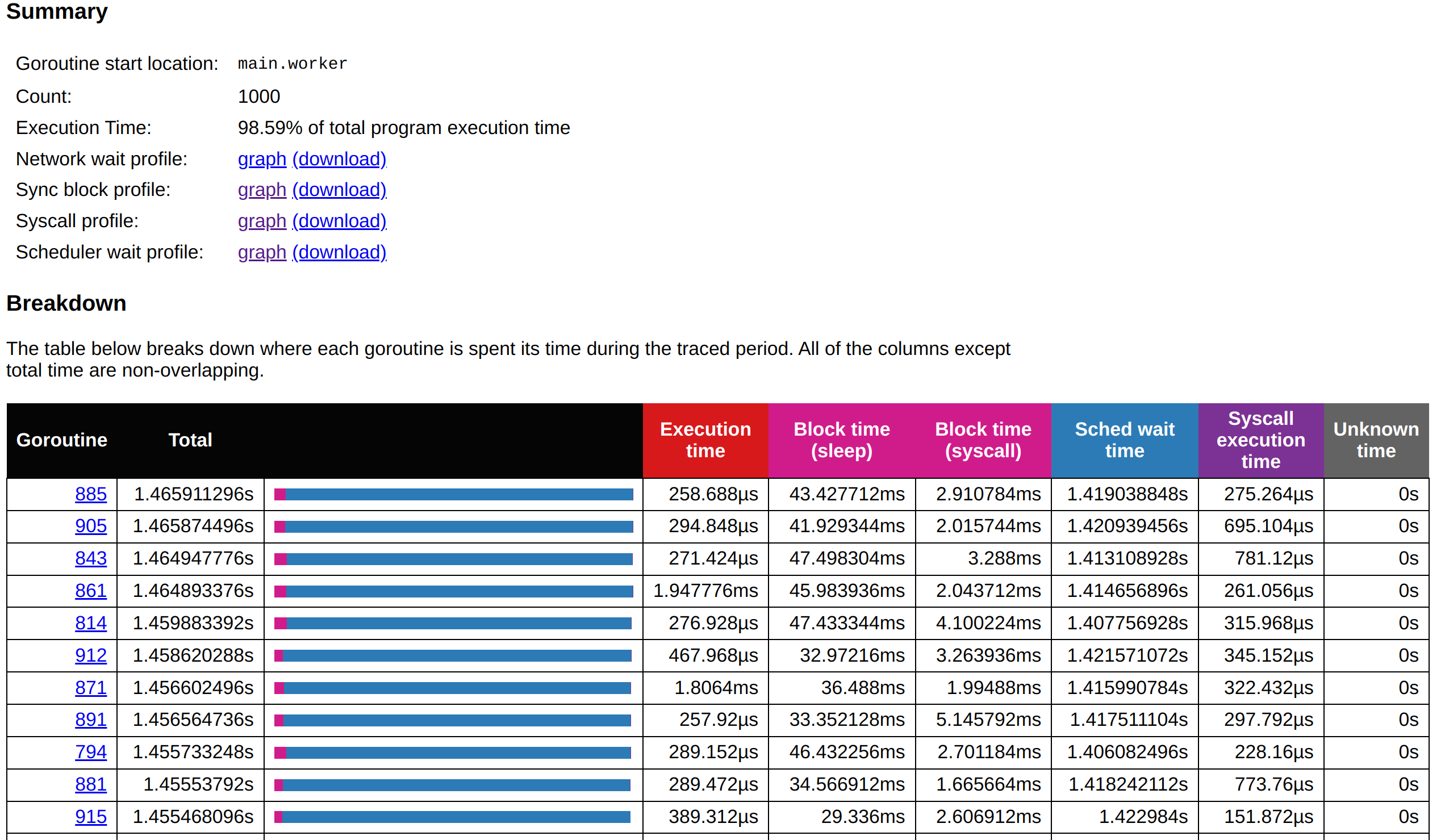
在上圖能看到這頁包含了 Summary、Breakdown、Special ranges 這三個部份。
Summary 部分:
目的:
Summary 是概覽層次的總結,它快速展示了某個 Goroutine 群組在整個程式中的重要性和性能負擔。
功能:
Goroutine Start Location:指示這些 Goroutines 的啟動位置,便於定位它們的程式碼源頭。
Count:顯示這個群組中的 Goroutines 數量(在這個例子中是 1000 個 Goroutines),方便我們了解這部分的併發數量。
Execution Time:顯示這個群組的 Goroutines 佔用的總執行時間(在這裡是 73.28%),這有助於快速確定哪個部分是系統的主要性能瓶頸。
性能瓶頸圖表:還提供了網路延遲、同步阻塞、系統調用阻塞和調度延遲的 pprof 圖表連結,幫助我們進一步調查具體的性能問題。
使用場景:
Summary 是幫助開發者快速識別哪部分的 Goroutines 佔用了最多的系統資源,從而優先關注和調查這些 Goroutines 的性能問題。
Breakdown 部分:
目的:
Breakdown 提供了更詳細的數據,展示每個 Goroutine 的執行情況,包括其執行時間分佈、阻塞情況、調度等待時間等。
Total 顯示的直條圖的顏色比例,剛好是右側對應顏色的區塊(Block time、Sched wait time 與 Syscall time)。
功能:
Execution Time:每個 Goroutine 的實際執行時間,幫助我們了解這些 Goroutines 完成任務所花費的時間。
Block Time:展示 Goroutines 在不同情境下的阻塞時間,如等待 GC、Channel 接收或系統調用的阻塞時間。
Sched Wait Time:顯示 Goroutines 在等待 CPU 調度時所花費的時間,這有助於了解系統的調度瓶頸。
Syscall Execution Time:顯示系統調用的實際執行時間,幫助確定是否有系統層面的 I/O 或其他系統資源調用瓶頸。
Unknown Time:用來表示程式中無法追蹤的執行時間,如果該時間非 0,則表明系統存在一些未知的性能問題,但在本例中均為 0。
使用場景:
Breakdown 可以讓開發者深入了解每個 Goroutine 的性能問題,並找出具體在哪些時間段和操作上出現了性能瓶頸(例如:系統呼叫過多或 CPU 調度延遲)。這部分對於定位問題特別有用。
Special Ranges 部分:

目的:
Special Ranges 專注於特殊的系統事件和垃圾回收過程,幫助我們理解 GC 的影響以及在 stop-the-world 階段程式的暫停情況。
功能:
GC incremental sweep:顯示 Goroutine 在增量垃圾回收掃描階段所花費的時間。
GC mark assist:展示 Goroutine 協助垃圾回收器標記存活對象的時間,這有助於了解 GC 的影響。
Stop-the-world (GC mark termination) 和 Stop-the-world (GC sweep termination):展示在 GC 的標記和掃描終止階段程式被暫停的時間("stop-the-world"),這些暫停時間直接影響到應用的延遲和響應性。
使用場景:
Special Ranges 幫助開發者了解垃圾回收對應用的影響,特別是在併發性高的場景下。它能夠幫助識別 GC 是否導致了應用程式的短暫「停止世界」現象,從而影響應用程式的性能和穩定性。
接著我們就針對 Breakdown 與 Special Ranges 兩個部份來閱讀分析。
問題分析
Breakdown 部份
問題分析:
Syscall 阻塞時間過長:
問題描述:從
Block Time(Syscall)欄位中可以看到,這些 Goroutines 在系統呼叫上阻塞了大量時間(約 2-4ms 以上)。這說明您的程式在進行某些系統操作時,如 I/O 操作(文件、網絡請求等)時,可能遭遇了瓶頸,導致 Goroutines 大量阻塞。影響:當大量的 Goroutines 同時進行系統調用(如文件讀寫、網絡請求等)時,如果這些系統資源的處理速度較慢或過載,會導致 Goroutines 大量堆積在等待系統調用完成,從而影響應用整體性能。
Scheduler Wait Time 较长:
問題描述:Goroutines 在
Sched Wait Time中花費了相當長的時間(大約 700-900 ms)。這表示這些 Goroutines 雖然被創建,但在實際被調度到 CPU 執行時,因為 CPU 資源不足或過度併發,它們在隊列中排隊等待 CPU 的調度。影響:這種情況下,即使 CPU 的總利用率可能並不高,但 Goroutines 的數量過多,導致了 CPU 調度器無法及時處理所有的工作,最終導致大部分 Goroutines 處於等待狀態。
優化建議:
限制 Goroutine 的數量:
原因:過多的 Goroutines 會導致 CPU 調度的壓力過大,系統會花費更多的時間在上下文切換而非實際執行程式邏輯。
解決方案:引入 Goroutine 池,限制同時啟動的 Goroutines 數量。這可以避免無法及時處理的 Goroutines 積壓在調度器中。
優化 I/O 和系統調用:
原因:從
Syscall Execution Time和Block Time(Syscall)可以看出,這些 Goroutines 在進行系統呼叫時花費了大量時間。這通常發生在處理大量 I/O 或頻繁的網絡請求時。解決方案:可以考慮使用異步 I/O 或批量操作來減少系統調用的次數,並提高每次調用的效率。同時,可以檢查是否存在過多的文件操作或網絡延遲問題,從而優化系統呼叫的性能。
調整 CPU 資源分配:
原因:
Sched Wait Time過長表明 CPU 無法及時處理這些 Goroutines,可能是因為 CPU 資源不足或者有過多的任務同時在運行。解決方案:可以考慮優化程式的併發度,減少不必要的 Goroutines 或者提高每個 Goroutine 的工作效率,從而減少 CPU 資源的消耗。
Special Ranges 部份
數據分析
GC incremental sweep 增量清理時間
大部分 Goroutines 在 GC 增量清理階段所花費的時間都極少,通常是納秒級別 (ns),如:
Goroutine 14 花費了 641ns。
Goroutine 15 花費了 3.52µs。
這表明,GC 增量清理對於系統的整體影響較小。增量清理的設計目的就是為了減少垃圾回收時對程式的影響。從數據上看,這部分工作基本上運作良好。
優化建議:
GC mark assist 時間
部分 Goroutines 在 GC 標記輔助過程中有明顯的時間消耗。例如:
Goroutine 10 花費了 2.004928ms,是標記輔助時間最多的 Goroutine。
大多數 Goroutines 花費的時間在 500µs 到數毫秒之間。
這表明某些 Goroutines 在記憶體分配過程中需要幫助 GC 完成標記工作,這可能是因為高併發場景下,記憶體分配頻率較高,導致標記操作佔用了更多的資源。
Stop-the-world (GC mark termination) 時間
在垃圾回收的 "stop-the-world" 階段,所有的 Goroutines 暫停執行,讓 GC 完成標記終止和清理終止操作。從數據看,大部分 Goroutines 在這一階段花費的時間非常少,通常是納秒級別,部分為微秒級別。例如:
Goroutine 75 在 GC Mark Termination 階段花費了 12.992µs。
其他大部分 Goroutines 僅花費了數微秒甚至納秒。
問題分析與優化建議
GC Mark Assist 負擔
問題:在表中,部分 Goroutines 在 GC 標記輔助過程中花費了較多時間(如 Goroutine 10),這表明程式中可能存在較多的記憶體分配操作,導致 Goroutines 必須頻繁幫助垃圾回收器標記物件。
優化建議:減少頻繁的內存分配操作,特別是在高併發場景中,可以考慮使用 記憶體池(memory pool) 或 對象重用技術,減少不必要的記憶體分配,從而降低 GC 壓力。
Stop-the-world 對程式的影響較小
觀察:從數據來看,垃圾回收過程中的 "stop-the-world" 操作對程式影響不大,因為在標記終止和清理終止階段的大多數 Goroutines 暫停時間都非常短(少於 10 微秒)。
優化建議:雖然
stop-the-world暫停時間影響較小,但隨著應用程式記憶體佔用的增加,這些暫停時間可能會變長。因此,仍然需要監控應用程式的物件記憶體使用情況,確保不會因為大規模記憶體分配導致 GC 壓力增加。
增量清理無明顯問題
觀察:增量清理階段(
GC incremental sweep)在各個 Goroutine 上的影響不大,清理工作在這些 Goroutine 中都只花費了幾十微秒的時間。優化建議:這表明現階段垃圾回收器的增量清理機制運作良好,無需進行特殊優化。
找出適合的 Woker 數量
從下圖我們能很輕易的從 Total 比例圖看出 Sched wait time 與 Block time 的差距懸殊,明明寫入 I/O 一定要調用 scscal,然後 Execution time 幾乎在這比例圖上看不太到。

Sched wait time 我們已經知道是 Goroutines 在等待 CPU 調度將 CPU 指派給自己能執行時所花費的時間。雖然 CPU 佔用時間有 98.59%,但可以說幾乎在瞎忙。我們從這裡就能知道 Goroutine 1000 的數量太高了,至於要降低成多少呢?總不能每次都二分法吧(500、250、125這樣嘗試下去) 。
目前嘗試 1000 worker 處理完畢約 1.46 s。但我們知道這很多在瞎忙,所以我們要找出一個適合的 worker 數量,減少瞎忙,但又不能處理的比現在慢。
go run main.go -workers 1000
Workers: 1000, Elapsed Time: 1.468617815s
假設 Total Time 是整個 goroutine 的執行總時間,主要由以下幾部分構成:
T_wait:sched wait time(排程等待時間)T_exec:execution time(執行時間)T_block:block time(包括sleep和syscall block time)T_syscall:syscall execution time(系統調用執行時間)
假設目標是讓 T_wait 和 T_exec + T_block + T_syscall 保持一定的比例,讓 CPU 能夠更加有效利用,並避免過多的排程等待。
我們可以用以下公式來計算最佳的 goroutine 數量:
調整公式
Goroutine 數量 = ( T_wait + T_exec + T_block + T_syscall ) / T_wait
這個公式的想法是,我們將 T_wait 和其他時間(真正工作的時間)作為比值,如果 T_wait 太高,則說明過多的 goroutine 導致過多的排程開銷。我們可以根據這個比例來減少 goroutine 的數量,直到 T_wait 和其他時間達到合理的比例。
可以按照上面的數據嘗試計算一下,以 Goroutine 885 為例。(1.4s + 258us + 43ms+3ms + 300us) / (258us + 43ms+3ms + 300us) = 31。很好執行時間一樣。
go run main.go -workers 31
Workers: 31, Elapsed Time: 1.435286063s
從下圖的數據與比例圖來比較分析。
1. 總體執行時間(Total Time)
兩者的總體執行時間基本上是相同的,均在 1.4 秒左右。這意味著無論是 1000 個 goroutine 還是 31 個 goroutine,總任務完成時間並未受到太大影響。
2. Sched Wait Time(排程等待時間)
1000 個 goroutine 的排程等待時間平均在 1.4 秒左右,這意味著大量的時間花費在等待排程上。
31 個 goroutine 的排程等待時間有所降低,平均在 400-500 毫秒左右,這表示減少 goroutine 數量確實有效地減少了等待時間。
解釋:
當 goroutine 的數量過多時,CPU 無法有效處理,導致過多的 context switching 和等待時間,這就讓大量時間被浪費在排程和調度上。減少 goroutine 數量,CPU 可以更高效地處理每個 goroutine,從而減少了排程等待時間。
3. Block Time(系統調用阻塞時間)
1000 個 goroutine 的阻塞時間大致集中在 40-50 毫秒。
31 個 goroutine 的阻塞時間與 1000 個 goroutine 基本相似,也在 40-50 毫秒左右。
解釋:
系統調用(例如文件讀寫)導致的阻塞時間主要由 I/O 性質決定,這一部分並未隨著 goroutine 數量的變化而明顯變動。
4. Execution Time(執行時間)
1000 個 goroutine 的執行時間幾乎可以忽略不計,每個 goroutine 的執行時間平均只有幾百微秒。
31 個 goroutine 的執行時間有所增長,每個 goroutine 平均達到 20-30 毫秒。
解釋:
隨著 goroutine 數量的減少,每個 goroutine 能夠獲得更多的 CPU 時間進行計算任務,而不是花費在等待排程上。這也說明了系統在高併發場景下會遇到資源競爭問題。
總結:
排程等待時間的改善: 減少 goroutine 數量有效地減少了系統在排程上的開銷,讓 CPU 能夠更好地處理每個任務。
系統調用阻塞時間相對穩定: 減少 goroutine 數量對系統調用導致的阻塞時間並沒有太大影響,因為這部分時間受 I/O 操作影響較大。
執行效率提升: 減少 goroutine 數量,執行時間顯著增加,表明 CPU 可以花更多的時間處理具體的任務,而不是被浪費在上下文切換上。
總的來說,減少 goroutine 數量可以有效提升整體的系統效率,特別是當系統遇到大量的排程開銷時。然而,由於 I/O 操作的特性,block time 並未有太大變化。說明其實我們只需要 31 個 gourtine 就能作到之前一樣的吞吐量。

但能思考,那是否小幅度增加 Gourtine 數量,就能始這段程式執行更快呢?
是否增加 goroutine 數量是否會改善性能主要取決於以下幾個因素:
Block time:如果 block time 比較高(例如大量的 I/O 等待),增加 goroutine 數量可能會改善這種等待現象,因為更多的 goroutine 可以在等待的同時處理其他任務。
Sched wait time:如果 sched wait time 很高,這意味著 CPU 資源正在被搶占。這種情況下,增加 goroutine 數量可能會進一步增加調度壓力,反而使
sched wait time增加,並不會提高性能。
我們曾經在 D11 給過這樣的公式。
Optimal Threads 數量 = ((Thread 等待時間 + Thread CPU 時間)/ Thread CPU 時間)* CPU 數量
在這裡,選取一個典型的 goroutine(例如 goroutine 19),可以得到以下數據:
Sched wait time= 468.98 msBlock time (sleep)= 847.08 msBlock time (syscall)= 84.46 msExecution time= 26.70 ms
計算 Thread 等待時間:
Thread 等待時間=468.98ms+847.08ms+84.46ms=1,400.52ms
所以 Optimal Threads=(26.70ms1,400.52ms+26.70ms)×1 =53.45

讓我們在比較一下兩個的差異。
- 31 vs 53 Goroutine 效果:雖然增加 Goroutine 數量從 31 增加到 53,總體的執行時間略有縮短(從 1.4 秒降到 1.2 秒),但是排隊時間反而小幅度上升,所以排隊時間和阻塞時間仍然是主要的瓶頸,沒有明顯的改善。這表明只是單純增加 Goroutine 數量,並不能大幅提高吞吐量。
因此,在這樣的情況下,與其持續增加 Goroutine,反而可以考慮優化 I/O 和系統調度的方式,這可能會帶來更好的效能提升。




